
lemolatoon
2.7K posts
lemolatoon
@lemolatoon1
bioです。seccamp '22 '23 (Cコンパイラ|OS自作)ゼミ。icon:(@murasame524)
Katılım Ağustos 2021
544 Takip Edilen692 Takipçiler
今日の夢、中学時代の同期と大学の先輩が上海に同時にいて何故か上海の世界線は自分が中学生の時のものだったみたいで大学の先輩の方には認識されなくてなんか泣いちゃった。途中でありえなさ過ぎて夢という事に気づいたけど別に自由に空飛べるとかはなかった
日本語
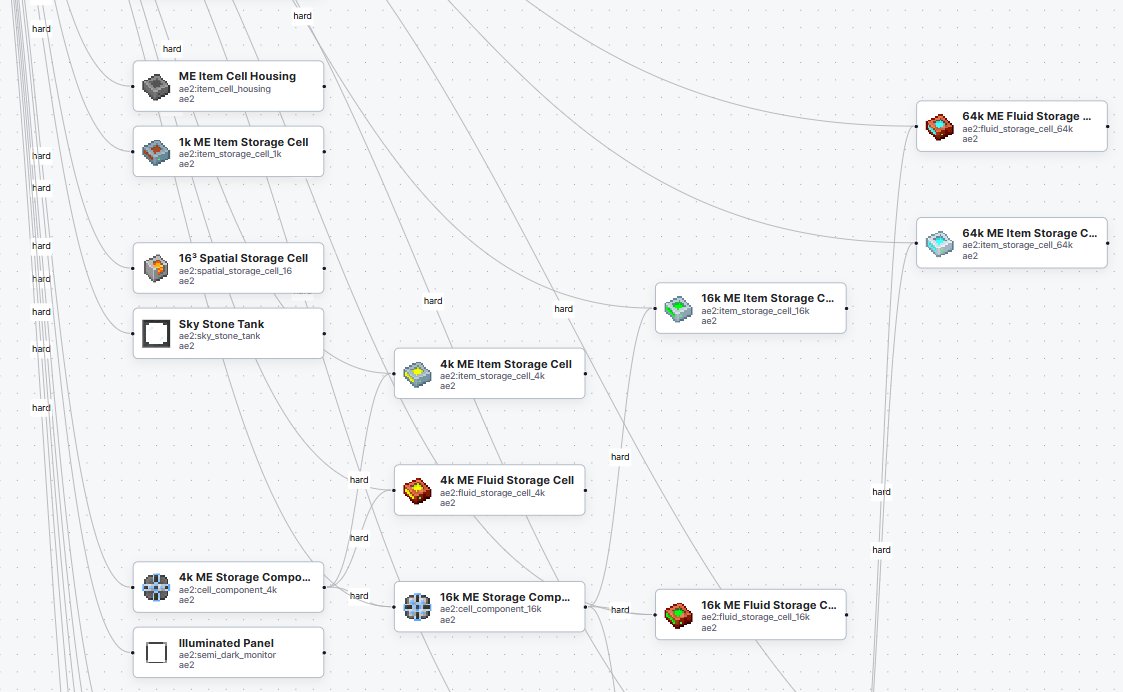
modpackのrecipeのDAGからquestの自動生成するやつをvibe codingしてる、DAGをもとにそのアイテムの重要性スコアをつける部分が肝だけどまだうまくいってない。
日本語
@rupone16 自分がやってるのがPod内でtailscaledを動かすのではなく、各ノードでtailscaledを動かしてtailnet上でkubelet同士を通信させてるのでちょっと違うissueな気がしますね。
日本語
kubernetes + CilliumをTailscaleに載せて使っていてなにか調子悪いんだけど結局何が原因かわかってない。一定間隔でまったく疎通できない時間があって全部パケロスしたりする。この記事の内容と関係あるのかは分からない。
日本語
lemolatoon retweetledi

@cordx56 35B-A3Bの方はおそらくアクティブ3Bだから推論は速くできて、27Bの方はシンプル27Bなので遅いのかなって思ってます、35B-A3Bの方はまだ試してないので今度やってみます。
日本語

@lemolatoon1 今確認したけど、Qwen3.6-35B-A3B:Q4_K_Mで平均48t/sとかだった。割と最近のリリース版llama.cpp。デバイスはDELL OEMのGB10搭載モデル。
日本語
@cordx56 llama.cppのHEADを雑にbuildして4bit量子化でやったら11tok/sとかでした。ローカルLLMそんなにやったことないのでまだもっと速くする方法あるかも?
日本語

今日の夢本当に悪夢だった。なぜかおばあちゃん家から始まったんだけど、急にイーロンマスクとトランプが来て車に一緒に乗ることになって、気づいたらレインボーブリッジみたいなとこ走ってた。そこでビルに丸が出るから合わせて押してって言われて、押したらそれに合わせてミサイルが飛んで全部破壊さ
日本語