mzba retweetledi

mzba
1.4K posts



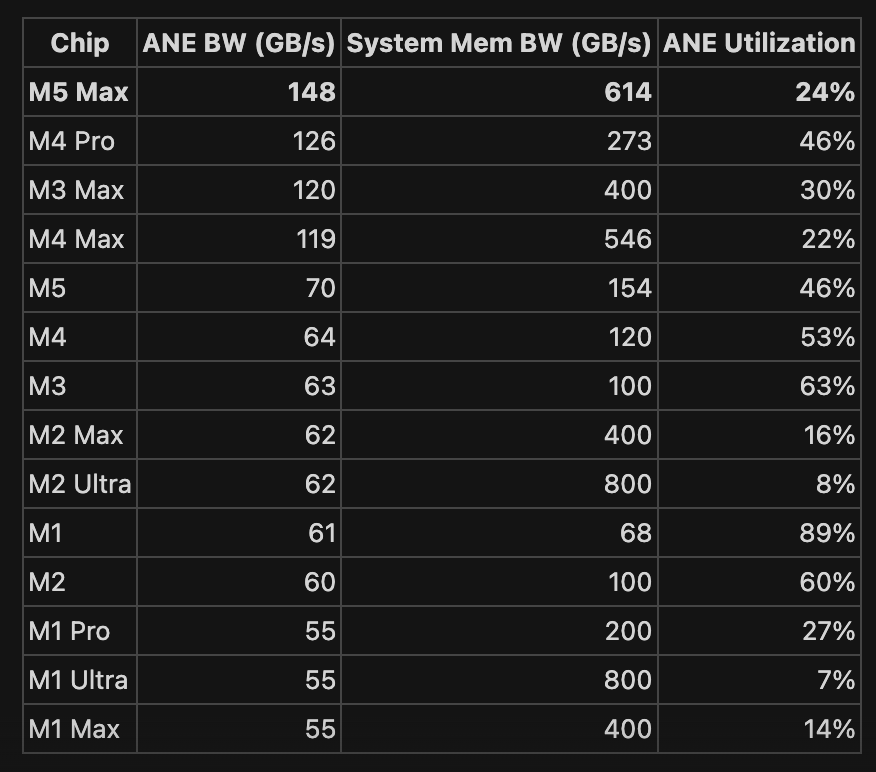
My favorite (and often overlooked) MLX feature is the 17 (and growing) CLI tools part of mlx-lm. You can do so much with a single line of code! Here's a quick overview 🧵 🚀 Inference, 🍦 Serving 🎯 Fine-tuning, ⚡ Quantization 📊 Evaluation & Benchmarking 🤗 Sharing and model management


I hosted @awnihannun on localhost, co-creator of MLX and member of the Deep Speech mafia. Enjoy! Apple Podcasts: podcasts.apple.com/us/podcast/loc… Spotify: open.spotify.com/episode/01Q0Re…

😅嗯,bb-browser,badboy browser,坏孩子浏览器来了,真的很丧良心,但真的很好用。 现在你可以用 bb-browser site 的方式直接拉到任何网站的信息,目前支持 Reddit、Twitter、GitHub、Hacker News、小红书、知乎、B站、微博、豆瓣、YouTube,50+ 个命令,我会持续更新。 当然能做到信息获取这件事不稀奇,我也是看到 @jakevin7 的 twitter-cli 的启发,才做的。但 bb-browser 的实现方式非常丧良心 — 我是通过 Chrome 插件 + CDP 直接操控你真实的浏览器。不是无头浏览器,不是偷 Cookie,不是模拟请求。你已登录了,它就直接用你的登录态。它直接在浏览器 console 里面跑 eval,以前爬虫最麻烦的登录态、还有各种鉴权都没有了😂。(这种方式真的。。。太作弊了,我都能想到哪些大厂前端发现我在这么搞,会怎么骂我,因为真的很难防) 另外我还在命令行里面埋了 guide 命令,也就是说你只要装了 bb-browser CLI 或 MCP,跟你的 Agent 说"我需要把 XX 网站 CLI 化",它就能帮你做了!!
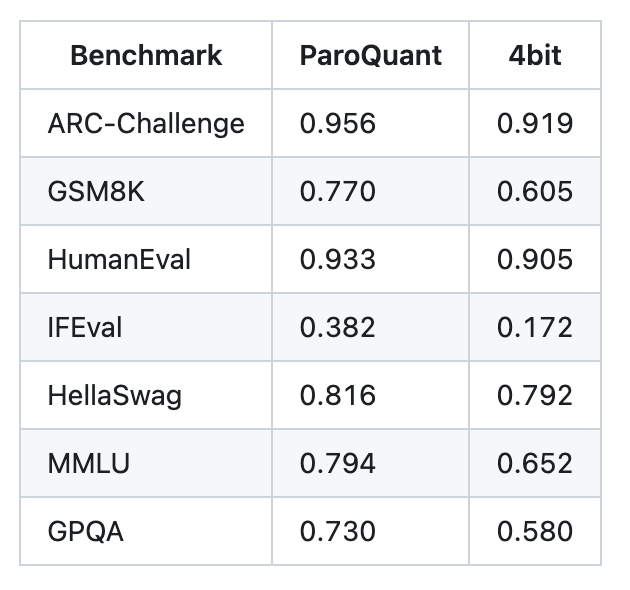



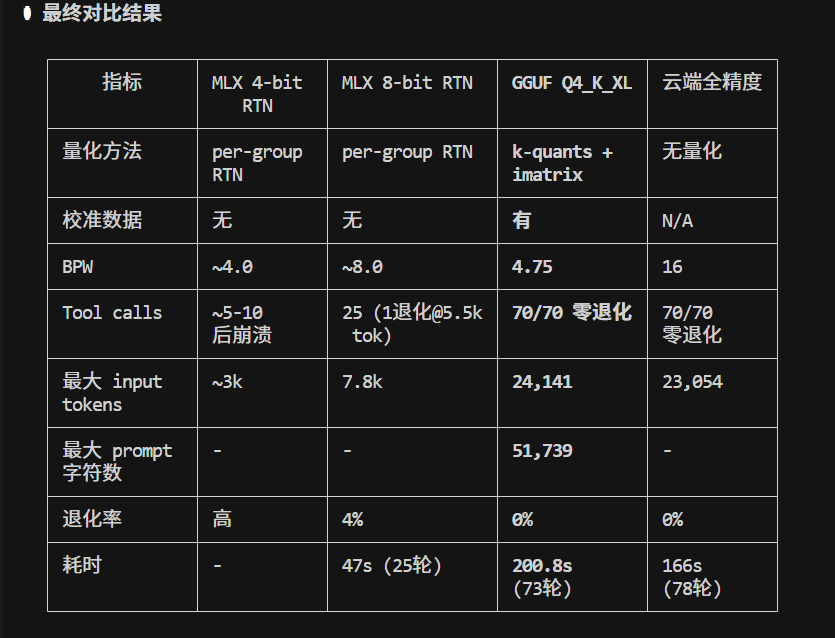


还是算了,qwen3.5低档model不适用于 claude code 的生产力。 MLX/Qwen3.5-35B-8bit , 虽然速度快,也有点智能, 但是不大适用于 claude code, 很容易退化。 大概13轮开始吧。 而一个任务,read write bash 来五六次 tool很常见,基本等于很难用于生产了。

Don't miss this great article.. reddit.com/r/LocalLLaMA/c…