Sabitlenmiş Tweet

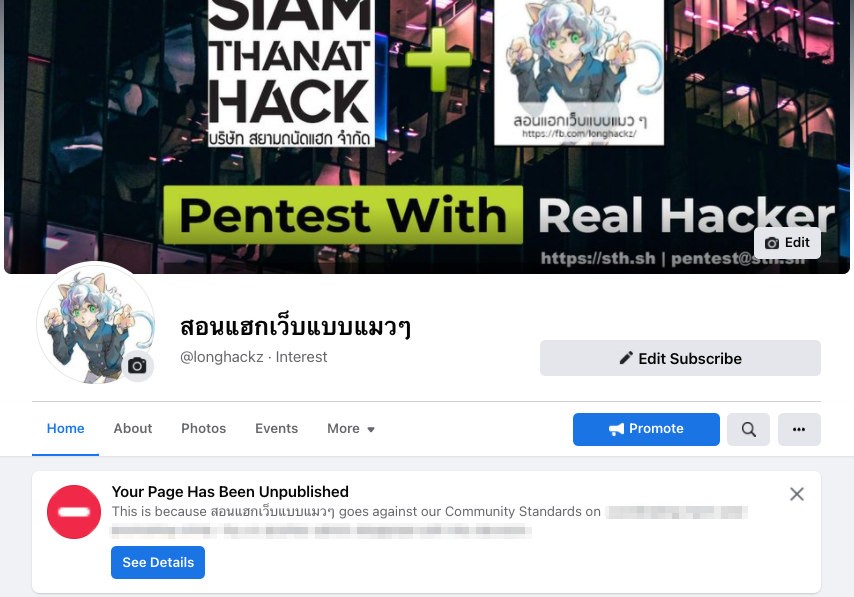
สวัสดีชาว สอนแฮกเว็บแบบแมวๆ (facebook.com/longhackz) ตอนนี้เฟซบุ๊กเหมือนจะบินทั้ง v.1 และ v.2 น่าจะย้ายมาอยู่บนทวิตเตอร์ (@longhackz ) และช่องทางอื่น ๆ แทน ใครสนใจเรื่องแฮก ๆ มาติดตาม follow รอกันได้เล๊ย 😂
ไทย
สอนแฮกเว็บแบบแมวๆ
272 posts

@longhackz
อัปเดทข่าวสารและเทคนิคการแฮกเว็บ กด ติดตาม กันโล้ด แชร์ได้ไม่ต้องขอ, คอร์สสอนแฮกเว็บแบบแมวๆ v.2 ย้ายมาจากเฟซบุ๊ก (โดนแบน)