Obra faraônica do governo Federal em Santa Catarina
O trecho da Serra da Rocinha, em Timbé do Sul, é uma demanda de mais de 70 anos dos produtores locais. A rodovia integra Santa Catarina à Serra Gaúcha até a Argentina, sendo um importante escoadouro.
Parabéns ao governo Lula!
"Me senti andando em Berlim nos anos 1930. Israel é o 4º Reich"
Jornalista Abby Martin relembra série de entrevistas que fez com israelenses em 2016 e afirma que sociedade israelense é "orgulhosamente fascista, racista e maníaco-genocida".
Como funciona o Ratio Escritório
O Ratio Escritório é um fluxo de trabalho multiagente para apoio à produção de peças jurídicas. A ideia não é substituir o advogado nem prometer automação total. O objetivo é organizar melhor o trabalho jurídico, etapa por etapa, com o profissional no controle o tempo todo.
O fluxo é dividido em agentes com funções bem delimitadas. Cada um recebe o que o anterior produziu, entrega algo concreto e visível, e aguarda a decisão do usuário antes de avançar.
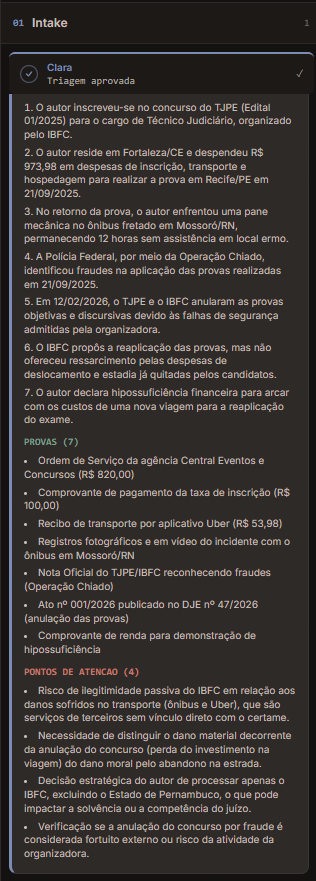
Clara — triagem e intake
O primeiro agente é a Clara. Quando o advogado descreve o caso, ela não apenas repassa o texto adiante: analisa o que foi relatado, organiza os fatos, lista as provas disponíveis, aponta pontos de atenção e, quando percebe lacunas relevantes, faz perguntas diretas ao usuário.
Se falta clareza sobre o polo passivo, sobre documentos ou sobre algum fato importante, a Clara devolve perguntas objetivas. O usuário pode complementar as informações, pedir que ela refaça a análise com o novo material ou simplesmente seguir assim mesmo, a escolha é dele. A ideia é que a Clara funcione como uma analista jurídica conversando com o advogado, não como um parser de texto que aceita qualquer coisa e segue em frente.
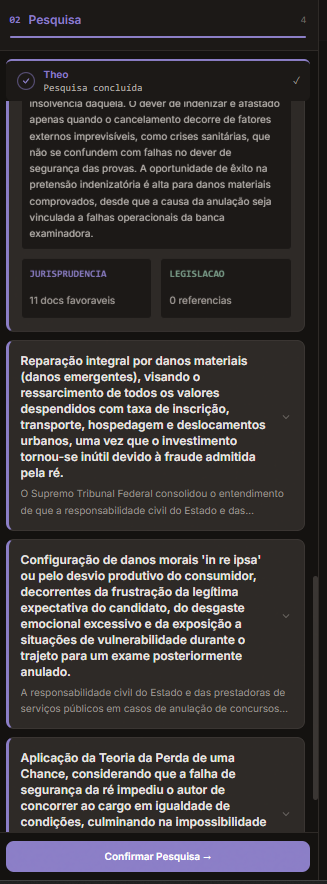
Theo — pesquisa jurídica
Com o caso estruturado, entra o Theo. Ele decompõe o problema em teses jurídicas distintas e faz pesquisa para cada uma separadamente. O resultado não aparece como uma caixa-preta genérica: o usuário vê as teses identificadas, o raciocínio do Theo para cada uma delas e a legislação complementar levantada para sustentar a peça.
Isso evita aquela sensação de que "o sistema pensou alguma coisa e eu não faço ideia do quê". A pesquisa fica auditável.
Helena — redação da minuta
Com base no material da Clara e nas pesquisas do Theo, a Helena monta a minuta da peça. A proposta aqui é que o documento seja revisável como um bloco estruturado — o usuário consegue editar e salvar a redação antes de avançar para a etapa seguinte. Nenhuma parte do fluxo avança sozinha.
Marco — revisão adversarial
Depois da minuta, entra o Marco. Ele assume o papel de advogado da parte contrária e tenta encontrar fragilidades: processuais, materiais, argumentativas. A crítica aparece de forma organizada para que o advogado possa avaliá-la com calma.
Mas o ponto mais relevante aqui é que isso não é uma revisão única e definitiva. O fluxo permite iteração: o usuário lê a crítica do Marco, ajusta a peça, roda uma nova rodada de revisão, compara as versões. Pode fazer quantas idas e voltas achar necessário antes de seguir.
Auditor e Formatador — entrega
Na etapa final, o sistema roda verificações formais e gera o .docx. O histórico completo do caso fica navegável — o usuário pode voltar para qualquer etapa anterior, restaurar um snapshot e revisar a pesquisa, a redação ou a última rodada de crítica do Marco quando quiser.
Por que dividir em agentes com funções separadas
Não é uma questão estética. Quando cada agente tem uma responsabilidade bem definida — Clara entende e estrutura, Theo pesquisa, Helena redige, Marco ataca, Auditor e Formatador fecham — o advogado deixa de lidar com um bloco genérico de IA e passa a lidar com um fluxo jurídico compreensível, etapa por etapa. Ele sabe o que cada agente recebeu, o que produziu e por quê o caso está no estado em que está.
O que ainda está em desenvolvimento: melhorar a qualidade das perguntas da Clara em casos mais complexos, fortalecer a pesquisa legislativa do Theo, e refinar a rastreabilidade de custos por etapa. São pontos que afetam diretamente a utilidade prática do sistema e que estão sendo trabalhados de forma contínua.
No fim, o Ratio Escritório é menos um sistema que "escreve petições sozinho" e mais um ambiente de trabalho jurídico assistido, com etapas separadas, memória do caso, revisão controlada e o profissional tomando as decisões em cada ponto do fluxo.
Resultado final sem edição alguma no pipeline nem no documento final: docs.google.com/document/d/1Zz…
Vale deixar claro que isso é uma versão inicial. O fluxo funciona, mas está longe de ser um produto acabado. A qualidade das perguntas da Clara, a profundidade da pesquisa do Theo, a estrutura formal das peças geradas pela Helena, a capacidade crítica do Marco — tudo isso ainda tem muito espaço para melhorar. A ideia de publicar isso agora é justamente abrir a discussão: sobre o modelo, sobre as limitações, sobre o que faz sentido ou não nesse tipo de abordagem para o trabalho jurídico real.
Abaixo mais prints
Don't pay for Apple Music, use ESound
Don't pay for Netflix, use Flixio
Don't pay for Peacock, use GlitchTV
Don't pay for Hulu, use ShowZone
Don't pay for Disney, use Netmirror
Don't pay for Spotify, use Lyra
Don't pay for Prime Video, use CineHub
Don't pay for Paramount+, use EpicFlix
Don't pay for YT Premium, use Brave browser
Don't pay for HBO Max, use Moviebox
Don't pay for Apple TV, use Streamly
🫶🏿
O mandado de segurança somente é cabível para trancar ação penal quando demonstradas, de forma inequívoca, a atipicidade da conduta, a ausência de justa causa ou a existência de causa extintiva da punibilidade. AgInt no MS 31311 / DF – CE/STJ – J. 26/08/2025 - DJEN 01/09/2025.
✨ CRONOGRAMA DE ESTUDOS PROMPT COMPLETO CLAUDE AI ✨
Instruções Iniciais:
1) Fiz pelo navegador, mas vc pode baixar o claude no pc;
2) Anexe o edital do seu concurso; o último edital ou um arquivo com as disciplinas q deseja estudar e o conteúdo programático de cada uma delas +
[CONTEÚDO PATROCINADO]
Medicina não é mercadoria.
O Conselho Federal de Medicina alerta para riscos quando decisões administrativas interferem no acesso de pacientes ao tratamento indicado.
Em alguns casos, isso pode significar a perda de uma chance de sobrevivência.
Como evolução natural do ratiojuris.me, fiz uma sessão de brainstorming com Claude, ChatGPT, Gemini para projetar a próxima fase: o Ratio Escritório: um escritório jurídico virtual multi-agente. (sempre faço sessão de brainstorming com modelos distintos antes de implementar algo)
A ideia é que o advogado descreva o caso em linguagem natural e uma equipe de agentes de IA faça o trabalho pesado de pesquisa, redação, validação e contradição. Pesquisa jurisprudência, redige a peça, e um agente adversário ataca a própria petição, simulando o que a parte contrária faria. O advogado supervisiona tudo, edita, aprova, e no final tem uma peça robusta pronta pra protocolar.
O que o está projetado, por ora:
- Intake inteligente: Você descreve o caso e a IA faz perguntas dinâmicas até entender tudo (tipo uma consulta com um estagiário muito bom);
- Pesquisa guiada por teses: Antes de buscar qualquer coisa, o sistema decompõe seu caso em teses jurídicas e pesquisa especificamente para cada uma, incluindo jurisprudência contrária;
- Redação por seções: A petição é gerada seção por seção (fatos, fundamentos, pedidos), cada parágrafo com a fonte linkada
- Loop de adversário/contraparte/opositor: Um agente separado (usando um modelo diferente) tenta destruir a petição. Aponta falhas processuais, argumentos fracos, jurisprudência faltante. E o sistema te obriga a lidar com cada ponto antes de finalizar;
- Verificação: Conferência automática em 5 camadas pra garantir que nenhuma citação é inventada. Se não conseguir verificar, marca como [VERIFICAR] em vez de deixar passar;
No final, download de um .docx nos padronizado, pronto.
Decisões técnicas que achei mais interessantes:
- O motor de pesquisa do Ratio atual (que já funciona com STF e STJ) vira a ferramenta que os agentes usam. Não joga nada fora.
- O agente adversário usa um modelo de IA diferente do redator de propósito, pra evitar "concordância automática" entre modelos iguais. Aqui, vale destacar:
O agente que ataca a petição é deliberadamente configurado para discordar. Quando o usuário tem chaves de provedores diferentes (ex: Gemini + Claude), o sistema usa modelos de empresas diferentes para redigir e criticar porque modelos diferentes têm pontos cegos diferentes, e essa diversidade gera críticas que o redator sozinho não encontraria. Mas mesmo com um único provedor, o sistema força a crítica real: saída estruturada que obriga o agente a preencher campos específicos de falhas, busca obrigatória de jurisprudência contrária, e rejeição automática quando o agente "não encontra nenhum problema" (porque toda petição tem problemas).
Mesmo assim, se o usuário ficar com uma pulga atrás da orelha e decidir comparar com a resposta de outro provedor, pode "importar parecer externo" que vai passar por todo o processo de validação antes de um veredito de um bom insight externo não observado.
- O usuário tem 2 pontos de aprovação obrigatórios: um após o intake ("entendemos o problema?") e outro após a pesquisa ("temos base suficiente?"). O sistema nunca segue sozinho.
- Cada ação mostra quanto vai custar em tokens antes de executar. Transparência total de custo.
- Tudo roda local na máquina do usuário. Nenhum dado do caso vai pra servidor externo além das chamadas de API dos modelos.
Stack: Python + FastAPI + LangGraph + LanceDB + React. Streaming em tempo real via SSE.
Haverá uma nova aba no webapp. Como funcionaria na prática: docs.google.com/document/d/1mD…
Sugestões?
OBS: eu não sou advogado, nem formado em direito. Eu sou um concurseiro curioso. Então é muito provável que haja lacunas que minha ignorância não permite visualizar. Adapte o roadmap pra sua necessidade.
Tudo deve ficar registrado na sua máquina em um banco de dados SQL (inicialmente). Nos comentários, uma representação visual de como mais ou menos deve ficar.