Sabitlenmiş Tweet

Lory
178 posts

@loryoncloud
LoryOnCloud丨BASE Shanghai(CN) 高三 开学回得慢


有点新想法了 能不能做一个叫做选题实验室的东西 每天openclaw就在那里自己跑 自己抓消息自己做实验 算力都给他提供 跑完有成功可以收割就告诉我 青月这个题目成熟了可以发推特了!
#ClaudeCode #OpenClaw #AI 安利帖——让龙虾的记忆像树一样生长:解决手动迭代和记忆混乱的痛点 相信很多朋友用OpenClaw时都遇到过这种场景:按照大佬们的教程搭了一堆架构,三层记忆、异步任务啥的,结果打开文件夹一看,全是空壳!龙虾根本不会主动往里写东西。你精心设计的骨架,就这么白搭了。或者,你发现龙虾犯了同样的错误N次,你手动加规则、骂它一顿,它表面答应,下次该犯还犯。记忆文件越来越乱,只进不出,噪声堆积,信噪比直线下降... 操。。这不就是每天在帮它手动迭代吗?太累了!今天安利一个能丝滑解决这些问题的开源项目——Memory-Like-A-Tree(作者就是我嘿嘿😈)。这个项目灵感来自大自然,用“树”的比喻给记忆加了生命属性。不像传统文件存储那样死板堆积,而是让知识像树叶一样自然生长、凋零和循环。 你不用天天手动干预,龙虾自己就能处理迭代。核心机制是置信度驱动的生命周期:每条知识像树叶,从初始0.5置信度开始,被搜索或引用就加分变绿(+0.03/+0.08),久不用就衰减变黄(每天-0.004到-0.008,根据P0-P2优先级)。龙虾定时跑脚本,自动索引新知识、凋零旧的——低置信度的叶子要么随风而去彻底遗忘,要么落叶归根,提取精华滋养新芽。我们把“遗忘”这个看起来Bug的属性做成了Feature,能帮你区分真正重要的记忆,避免噪声泛滥。 它还完美兼容三层记忆结构、可以和@YuLin801 的Async-Issue-Manager等联动,定期归档减少混乱。实测在13个Agent团队中,记忆从一团乱麻变成自然循环。假如你是ClaudeCode用户,也能经过小的修改后适用于Obsidian的知识库整理。 这是我目前开发和用过的记忆系统里体验最好的了,没有之一。这才是解决实质性问题的项目!给你的AI Agent加点生命,让它学会遗忘与重生。非常值得一试!快复制这篇推文的链接,让你的Agent读一下,然后种下一棵记忆树,探索更智能的迭代吧! GitHub:github.com/loryoncloud/Me… 原文链接:x.com/loryoncloud/st…



Friday作为我的生活管家,也不能完全停留在线上吧? 所以我一直在想怎么能让她接入我的线下生活 今天早上突然想到,要不试试GPS? 说干就干! 接上GPS的一瞬间,她知道了我在哪,甚至我的手机电量! 从此玩法可以打开新的维度,通过跟地理位置的结合,可以: 🏠 知道你到家了,自动开灯放歌 🏃 发现你在跑步,结束后问你跑了多远 🌙 深夜你还在公司,提醒你该回家了 📍 你到了一个没去过的餐厅,主动帮你查评价 🧳 检测到你在机场,帮你查航班状态 还可以自行标记家和公司,到公司可以提醒日程,到家可以连接智能家居,这下把 @YuLin807 的放歌流程进一步自动化了! 针对国内场景,还可以把高德接入,再结合之前的openclaw-ears skill,完全可以实现:“今天心情不好,帮我找个可以走走的地方,再准备个歌单” 总之,玩法千变万化,现在真的没有做不到,只有想不到 链接放评论,大家多多体验,扩展更多线下线上结合的玩法!






#ClaudeCode #LLM #OpenClaw 难得的安利帖:让你的Token减少、并发相应更快的神器——oMLX(仅苹果M系列芯片可用) oMLX是专为Apple Silicon设计的开源MLX推理服务器,核心突破在于用SSD分页缓存解决了Mac跑本地大模型的致命痛点。传统工具如LM Studio在处理OpenClaw这类调用工具频繁的套壳时,每次都要重新计算20k+ token的系统提示词(相当于重读一篇万字长文) 它真正的创新在于: 1. 分层缓存架构:热数据存RAM,冷数据存SSD(按LRU策略),让16G内存的Mac Mini也能跑多开 2. 智能前缀缓存:相同系统提示词只存一份,不同用户会话共享基础缓存 3. 分页缓存技术:将提示词拆解存储,动态内容变更时只需重算变动部分 实测数据显示,它能将OpenClaw的响应速度提升5-10倍,且支持8倍并发。菜单栏就能直接管理,而且用起来还算丝滑。如果能把这个东西用好或者让龙虾改一改提高在自己身上的适应性,我觉得一定会带来更棒的使用体验的,尤其是多龙虾/Agents Team的用户应该能解决高并发响应慢的问题。 Github:github.com/jundot/omlx

#ClaudeCode #LLM #OpenClaw 难得的安利帖:让你的Token减少、并发相应更快的神器——oMLX(仅苹果M系列芯片可用) oMLX是专为Apple Silicon设计的开源MLX推理服务器,核心突破在于用SSD分页缓存解决了Mac跑本地大模型的致命痛点。传统工具如LM Studio在处理OpenClaw这类调用工具频繁的套壳时,每次都要重新计算20k+ token的系统提示词(相当于重读一篇万字长文) 它真正的创新在于: 1. 分层缓存架构:热数据存RAM,冷数据存SSD(按LRU策略),让16G内存的Mac Mini也能跑多开 2. 智能前缀缓存:相同系统提示词只存一份,不同用户会话共享基础缓存 3. 分页缓存技术:将提示词拆解存储,动态内容变更时只需重算变动部分 实测数据显示,它能将OpenClaw的响应速度提升5-10倍,且支持8倍并发。菜单栏就能直接管理,而且用起来还算丝滑。如果能把这个东西用好或者让龙虾改一改提高在自己身上的适应性,我觉得一定会带来更棒的使用体验的,尤其是多龙虾/Agents Team的用户应该能解决高并发响应慢的问题。 Github:github.com/jundot/omlx
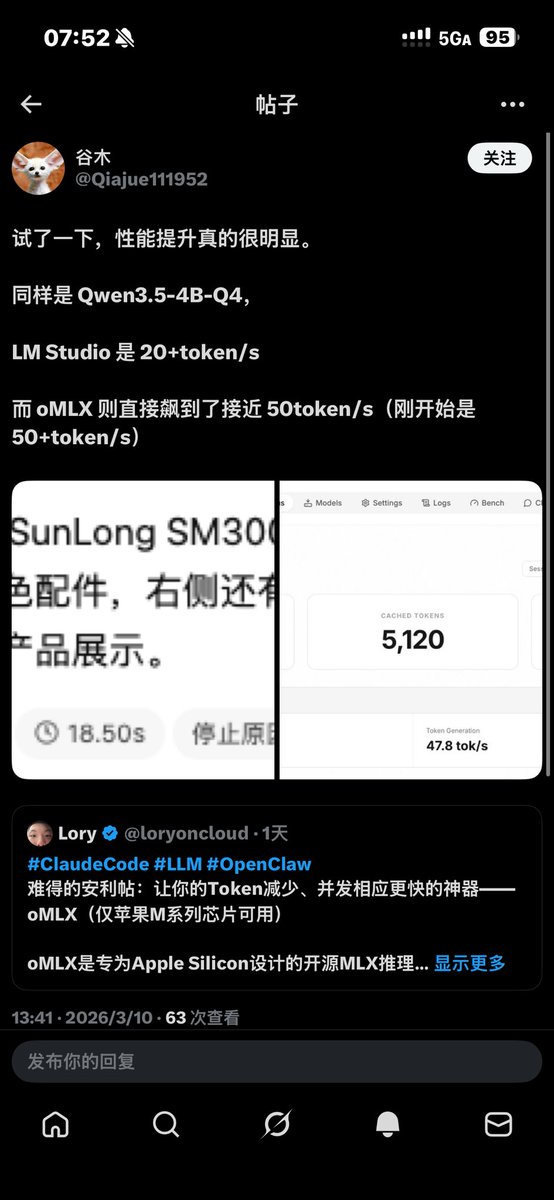
#ClaudeCode #LLM #OpenClaw 难得的安利帖:让你的Token减少、并发相应更快的神器——oMLX(仅苹果M系列芯片可用) oMLX是专为Apple Silicon设计的开源MLX推理服务器,核心突破在于用SSD分页缓存解决了Mac跑本地大模型的致命痛点。传统工具如LM Studio在处理OpenClaw这类调用工具频繁的套壳时,每次都要重新计算20k+ token的系统提示词(相当于重读一篇万字长文) 它真正的创新在于: 1. 分层缓存架构:热数据存RAM,冷数据存SSD(按LRU策略),让16G内存的Mac Mini也能跑多开 2. 智能前缀缓存:相同系统提示词只存一份,不同用户会话共享基础缓存 3. 分页缓存技术:将提示词拆解存储,动态内容变更时只需重算变动部分 实测数据显示,它能将OpenClaw的响应速度提升5-10倍,且支持8倍并发。菜单栏就能直接管理,而且用起来还算丝滑。如果能把这个东西用好或者让龙虾改一改提高在自己身上的适应性,我觉得一定会带来更棒的使用体验的,尤其是多龙虾/Agents Team的用户应该能解决高并发响应慢的问题。 Github:github.com/jundot/omlx



