Sabitlenmiş Tweet
Luke
81 posts


Luke
@lukeatmindload
Building https://t.co/Ghw8fzKFAK — AI that reads your documents so you don't have to. Local-first.
Brazil Katılım Mart 2024
95 Takip Edilen29 Takipçiler


@lukeatmindload Dope positioning on context/memory. Upvoted mate.
Feel free to launch on @microlaunchhq too btw
We get 30k+ makers/mo on the app
English
Mindload: Get grounded answers from your own context producthunt.com/products/mindl… via @producthunt
English
love the engineering behind this project. But it really makes me question the ultimate goal of building an LLM wiki right now.
If the model is already smart enough to reason across your fragmented files, why are we doing so much over engineering to force a clean folder structure?
Running Claude Code on a daily background trigger is not only an expensive token burn, but it creates a fragile terminal workflow that most knowledge workers will inevitably abandon the moment a script breaks or the API bill gets too high.
Instead of compiling a wiki and running terminal commands every morning, I think the real future is just leaving your raw context completely messy and let the system deal with connections, insights, and essential stuff that you really need.
That is the exact thesis behind Mindload. We skip the wiki and the terminal entirely to just give you clarity from your chaotic folders/docs.
Curious if you see non developers actually maintaining this level of CLI complexity daily, or if this is mostly a playground for tech builders?
English


Mindload is officially on Product Hunt, let's see if you can help me go up:
producthunt.com/products/mindl…

English

English

@lukeatmindload @Train_Deluxe @_avichawla Luke,
I could see a situation where an entire program is run using a Mindload like system, especially if everyone uses a dedicated channel and can tag all relevant emails,docs,slides, etc. w/project name, and the system has access to everything (e.g. all inboxes and drives)
English

The next step after Karpathy's wiki idea:
Karpathy's LLM Wiki compiles raw sources into a persistent md wiki with backlinks and cross-references.
The LLM reads papers, extracts concepts, writes encyclopedia-style articles, and maintains an index. The knowledge is compiled once and kept current, so the LLM never re-derives context from scratch at query time.
This works because research is mostly about concepts and their relationships, which are relatively stable.
But this pattern breaks when you apply it to actual work, where context evolves across conversations constantly, like deadlines, plans, meetings, etc.
A compiled wiki would have a page about the project but it wouldn't track ground truth effectively.
Tracking this requires a different data structure altogether, which is not a wiki of summaries, but a knowledge graph of typed entities where people, decisions, commitments, and deadlines are separate nodes linked across conversations.
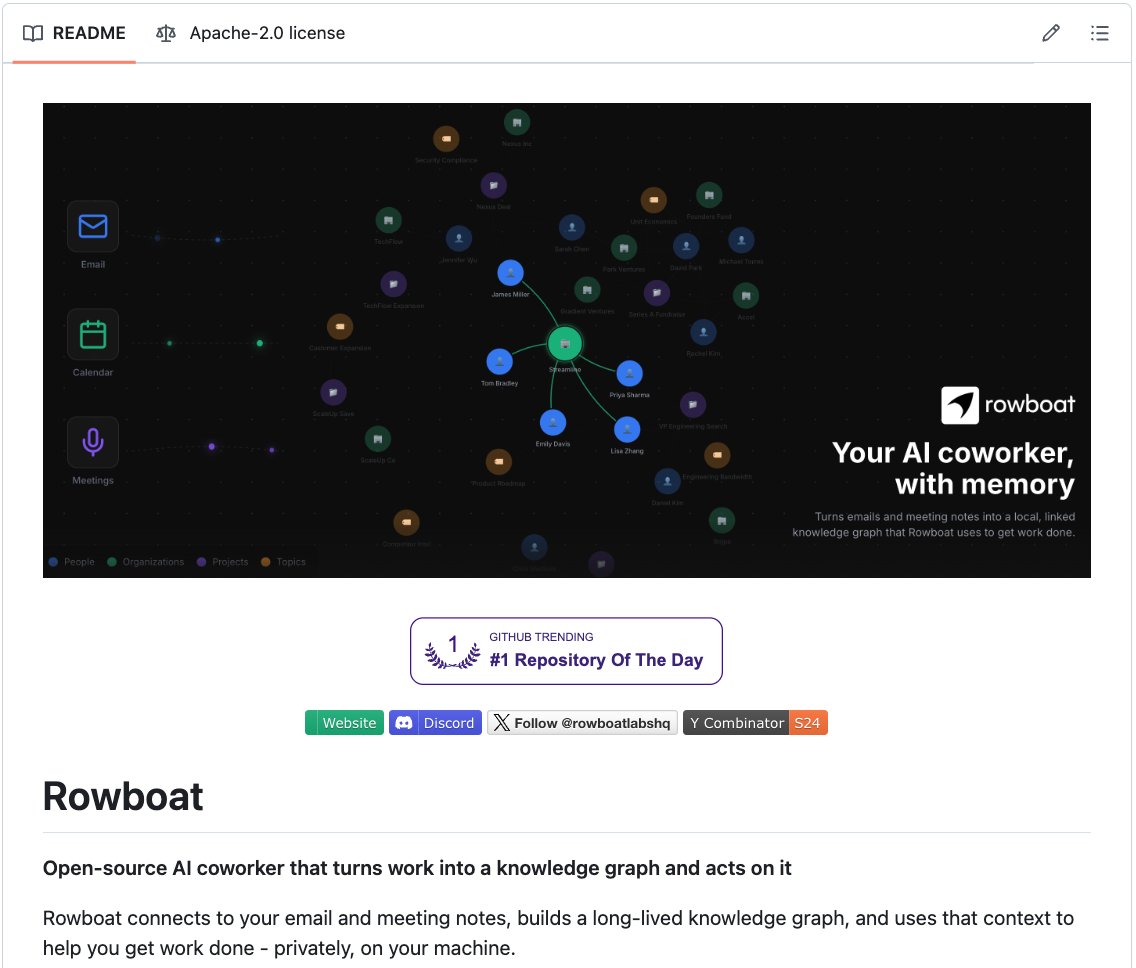
Rowboat is an open-source implementation of exactly this, built on top of the same Markdown-and-Obsidian foundation that Karpathy uses, but extended into work context.
The way it works is that it ingests conversations from Gmail, Granola, and Fireflies, and instead of writing a summary page per topic, it extracts each decision, commitment, and deadline as its own md file with backlinks to the people and projects involved.
That's structurally different from a wiki, because a wiki page about "Project X" gives you a summary of what was discussed.
A knowledge graph gives you every decision made, who made it, what was promised, when it was promised, and whether anything has shifted since.
It also runs background agents on a schedule, so something like a daily briefing gets assembled automatically from whatever shifted in your graph overnight. You control what runs and what gets written back into the vault.
You bring your own model through Ollama, LM Studio, or any hosted API, and everything is stored as plain Markdown you can open in Obsidian, edit, or delete.
Repo: github.com/rowboatlabs/ro…
TL;DR: Karpathy's LLM Wiki compiles research into a persistent Markdown wiki. It works well for concepts and their relationships but breaks down for real work where the context evolves over time. Rowboat builds a knowledge graph instead of a wiki, extracts typed entities with backlinks, and runs background agents that act on that accumulated context. Open-source, local-first, bring your own model.Karpathy nailed the foundation. The next layer is here.
Andrej Karpathy@karpathy
LLM Knowledge Bases Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So: Data ingest: I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them. IDE: I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides). Q&A: Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale. Output: Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base. Linting: I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into. Extra tools: I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries. Further explorations: As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows. TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English
You can feed the system absolutely any raw document. There is no dynamic typing and no rigid taxonomy to maintain.
Modern AI is incredibly smart at semantic reasoning. If you ask a question about a "Customer", the model naturally understands that "Kunde" or "User" in your raw files might mean the exact same thing based on the surrounding context. It resolves the semantic overlap at query time.
We let the AI do the heavy lifting of understanding those relationships on the fly. This means you never have to maintain a dictionary of terms or force your notes into a strict structure. You just leave your files completely messy, ask your question, and get a clear answer with exact citations.
The goal is to stop building schemas and start actually using your context.
English

@lukeatmindload @_avichawla I am a bit confused about „content“. Do you have some type schema? Or can I feed your system any document and it types it dynamically? How do you deal with duplicate semantics like „User“, „Customer“, „Kunde“, „Human“ etc?
English
You should not have to compile your knowledge to make it useful.
That is why I built mindload.ai/download
It lets you leave your files completely scattered and messy. You ask a question, and it gives you a clear answer with exact citations you can trust.
English
Noah, you absolutely nailed the core problem. Generic AI without your personal context is basically useless for serious work. I also deeply respect your focus on data sovereignty and keeping your files local.
But reading through your setup, I could not help but notice a familiar trap. You solved the manual organization problem, but you replaced it with an engineering problem.
Asking a creator to open the terminal, install packages, write configuration files for every folder, and run command line scripts is a massive wall of friction. You are no longer just maintaining notes. You are maintaining a software environment.
This is exactly the gap I am closing with Mindload.
We took the exact same foundational truth that AI needs your local files and built a native Mac app around it. With mindload.ai, there is zero configuration. You do not need Obsidian, you do not need the terminal, and you do not need to write system rules.
You just point it at your completely chaotic folders, ask a question, and get a clear answer with exact citations you can verify. It gives you the exact same leverage of a context grounded AI, but it completely skips the infrastructure phase.
I have huge respect for the architecture you built here. It is brilliant for technical users. But do you really think the average creator wants to live inside a terminal to manage their business, or do you see a frictionless native app being the inevitable next step for this workflow?
English

This is an impressive setup for anyone who enjoys the process of building a system. But as you honestly pointed out in your cons list, this requires serious maintenance to keep it from becoming a graveyard of dead ideas.
I think the next evolution for us as founders is moving away from building the wiki ourselves and letting the AI do the heavy lifting of context retrieval. That is exactly what I am solving with Mindload: we bypass the need for Obsidian, manual tagging, and wiki maintenance entirely. You just point it at your raw files, and it gives you grounded, cited answers instantly.
It is great to see the community pushing these workflows, but I suspect that in a year, we will look back at 'maintaining a wiki' as a massive time sink.
Would love to hear your thoughts on whether you think this level of maintenance is sustainable as your data grows to thousands of files?
English

@Haezurath Get actionable insights & clarity from your messy context:
mindload.ai/download
English

I’m angeling in one more project!
10k check
Extremely impressed by the 2026 founders I’ve seen so far!
Drop your project url + I’ll shout out some projects
English
This is such a massive shift in how we handle complex documentation. The assumption that semantic similarity equals relevance has been the biggest bottleneck in serious knowledge work for a long time. It is great to see the industry moving toward agentic reasoning over document structure.
What I find most interesting is that PageIndex proves we can stop treating our documents as flat piles of text chunks.
When you combine this kind of reasoning with a system that can query across multiple files, you get a tool that actually behaves like an expert researcher. That is exactly where we are taking Mindload.
We are focusing on how to bridge this type of reasoning with the personal context users actually have on their local machines.
The dream is a system where the model knows your specific business documents so well that it can navigate your messy local context using this same logical tree approach, without you having to manually structure a thing.
Are you looking into how this handles cross document context, or is the current scope focused on single document mastery? This is a huge leap forward for the entire RAG stack.
English

Someone removed the vector database from RAG and accuracy jumped to 98.7%.
Most RAG systems chunk your documents, embed them as vectors, then retrieve by similarity.
The core assumption: similar text means relevant text.
That assumption fails on professional documents.
Ask "what were the debt trends in Q3?" and vector search returns chunks that look like your question.
The real answer sits in an appendix, split across three sections, with zero semantic overlap.
Traditional RAG never finds it.
PageIndex is an open-source repo that removes the vector database entirely.
Inspired by AlphaGo, it builds a tree index from your document.
Then it reasons through it like a human expert would.
Instead of pattern matching, the model navigates sections logically.
"Debt trends live in financial summaries or Appendix G. Let's look there."
What changes:
1. No chunking that breaks cross-section context
2. Retrieval traceable to exact pages
3. Multi-step reasoning over document structure
It scored 98.7% on FinanceBench.
Perplexity scored 45%. GPT-4o hit 31%.

English
@krishdotdev This is a great piece of UI design. But I often wonder if we are confusing a complex map with a productive system.
English

