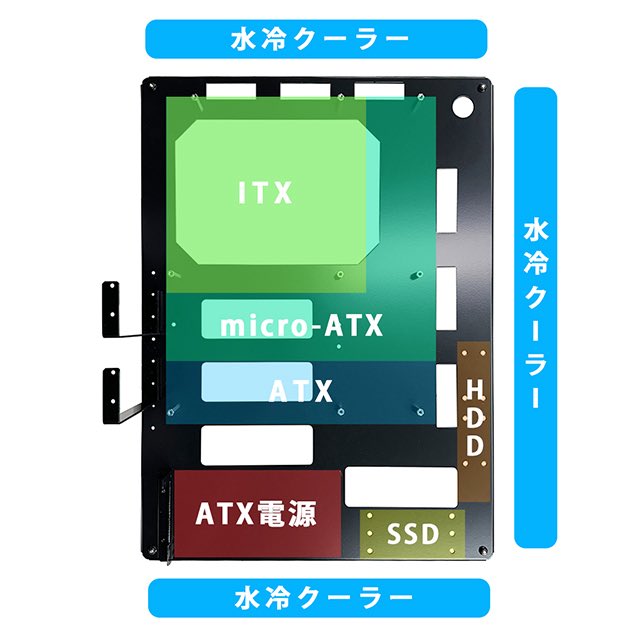
@BIG3_PEAK_ADAPT ローカルLLMを自分でホストできるならSuperpowersプラグインいれてCodexはSpecとPlanの記述だけさせる
実際のコーディング出力はローカルLLMにやらせる
とトークン出力を節約できます
Planの中に仕様を満たすコードがほとんど出力されてるからCodex単体でやると損
日本語
CopenDeCamp
41 posts


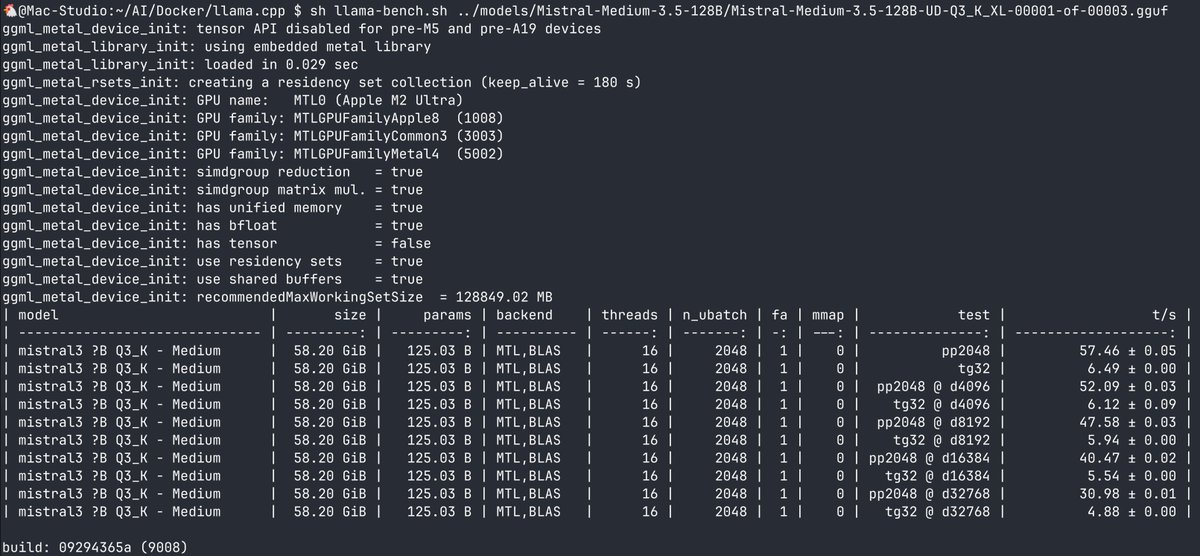
お!Mistral-Medium-3.5-128BのGGUFのウェイトがずっと消されてたけど、今見たらアップロードされている huggingface.co/unsloth/Mistra…
EVO-X2は、GPT-OSSが公開された当初は、画期的なデバイスだったと思う。 同等のモデルを動かすためにRTX Pro6000Blackwellや、Mac Studioが必要であり、それがローカルで25万円で購入できる唯一の選択肢だった。 ただ個人的に唯一誤算だったのは、生成AI恩恵も受けたのに、ROCmのCUDA互換性やその開発速度が劇的に上がらなかったこと。
Ryzen AI Max+ 495のベンチマークが登場 CPU性能はMax+ 395から10%増もGPU性能は同等 一方でメモリの最大サポート容量は128GBから192GBへ大幅拡大 AI向け用途を想定 gazlog.jp/entry/ryzen-ai…

CPU、GPU性能向上はわずかで大きな変更点はメモリを192GBにできるようになったことか EVO-X2買ったは良いのだが、AI性能はNVIDIA GPUやMacに劣るのでローカルAI用途としては使っていない。そういう意味でメモリ増やしても使いみちあるのかな?200BのLLMがローカルで動いた!(2tpsで)とかになりそう






今の平均的な大学生のSNS事情 ・Instagram→必須 ・BeReal→6割くらいやってる。無くても耐え ・LINE→必須だがインスタで事足りる。親しい人以外はあまり交換しない ・Twitter→# 春から○○大とかでしか使わない。推しを見るために使ってる人多数 ・TikTok→殆ど入れてる。よく見てる