Martin Kunc retweetledi
Martin Kunc
754 posts

Martin Kunc
@m_kunc
Golang & C# developer
Brno, Česká republika Katılım Eylül 2010
914 Takip Edilen78 Takipçiler


Martin Kunc retweetledi

80 days left. Onward to victory!❤️🤍💚

English
Martin Kunc retweetledi

Go 1.26 brings the long-awaited vectorized operations (SIMD) in the simd/archsimd package.
Since it's hard to create a portable high-level API, the Go team decided to start with a low-level, architecture-specific one and support only amd64 for now.
I think it's a great idea to let developers try things out and give feedback before designing a high-level interface.
But there's one thing I don't quite understand.
Why is the package called simd/archsimd? Since it's amd64-specific, shouldn't it be simd/amd64 or maybe simd/avx?
What happens when Go adds support for SIMD on arm64? Wouldn't simd/archsimd become a messy bag of types, some supported only on amd64 and others only on arm64?

English
Martin Kunc retweetledi

“Courage is not simply one of the virtues, but the form of every virtue at the testing point, which means, at the point of highest reality.”
—C.S. Lewis

English
Martin Kunc retweetledi


Wow, a Duolingo for #golang
I just completed "My First Go Program" on GoFlow! 🎉🐹 Learning Go the fun way. bytesizego.com/goflow
English
Martin Kunc retweetledi

LemonSqueezy rejected my note taking web app so I'm releasing it for free.
End to end encrypted offline markdown notes.
Everything encrypted with a vault key that never leaves your device, no one else can read it, not even me.
I use it all the time, even with sensitive data.
English
Martin Kunc retweetledi

🐹Fast Go = knowing where bytes go
This post is a great “look under the hood” tour of how Go actually hands out memory.
Deep dive into allocator arenas/pages/spans, escape analysis (stack vs heap)
nghiant3223.github.io/2025/06/03/mem…
#golang #go #memory
English
Martin Kunc retweetledi
I've just published two chapters of my interactive book on Go concurrency, and I invite you to read them!
If you are new to concurrency, start with the Goroutines chapter.
Otherwise, try the Wait groups chapter, I bet you'll learn something new.
antonz.org/go-concurrency
English
Martin Kunc retweetledi

Antifragile Programming and Why AI Won’t Steal Your Job
Whenever I say I dislike debugging and organize my programming habits around avoiding it, there is always pushback: “You must not use a good debugger.”
To summarize my view: I want my software to be antifragile (credit to Nassim Taleb for the concept). The longer I work on a codebase, the easier it should become to fix bugs.
That’s not natural. For most developers lacking deep expertise, as the codebase grows, bugs become harder to fix: you chase symptoms through layers of code, hunt heisenbugs that vanish in the debugger, or fix one bug only to create another. The more code you have, the worse it gets. Such code is fragile. Adding a new feature risks breaking old, seemingly unrelated parts.
In my view, the inability to produce antifragile code explains the extreme power-law distribution in programming: most of the code we rely on daily was written by a tiny fraction of all programmers who have mastered antifragility.
How do you reverse this? How do you ensure that the longer you work on the code, the shallower the bugs become?
There are well-known techniques, and adding lots of tests and checks definitely helps. You can write antifragile code without tests or debug-time checks… but you’ll need something functionally equivalent.
Far-reaching prescriptions (“you must use language X, tool Y, method Z”) are usually cargo-cult nonsense. Copying Linus Torvalds’ tools or swearing style won’t guarantee success. But antifragillity is not a prescription, it is a desired outcome.
Defensive programming itself is uncontroversial—yet it wasn’t common in the 1980s and still isn’t the default for many today.
Of course, a full defensive approach isn’t always applicable or worth the cost.
For example, if I’m vibe-coding a quick web app with more JavaScript than I care to read, I’ll just run it in the browser’s debugger. It works fine. I’m not using that code to control a pacemaker, and I’m not expecting to be woken up at midnight on Christmas to fix it.
If your program is 500 lines and you’ll run it 20 times a year, antifragility isn’t worth pursuing.
Large language models can generate defensive code, but if you’ve never written defensively yourself and you learn to program primarily with AI assistance, your software will probably remain fragile.
You can add code quickly, but the more you add, the bigger your problems become.
That’s the crux of the matter. Writing code was never the hard part—I could write code at 12, and countless 12-year-olds today can write simple games and apps. In the same way, a 12-year-old can build a doghouse with a hammer, nails, and wood. Getting 80% of the way has always been easy.
Scaling complexity without everything collapsing—that’s the hard part.
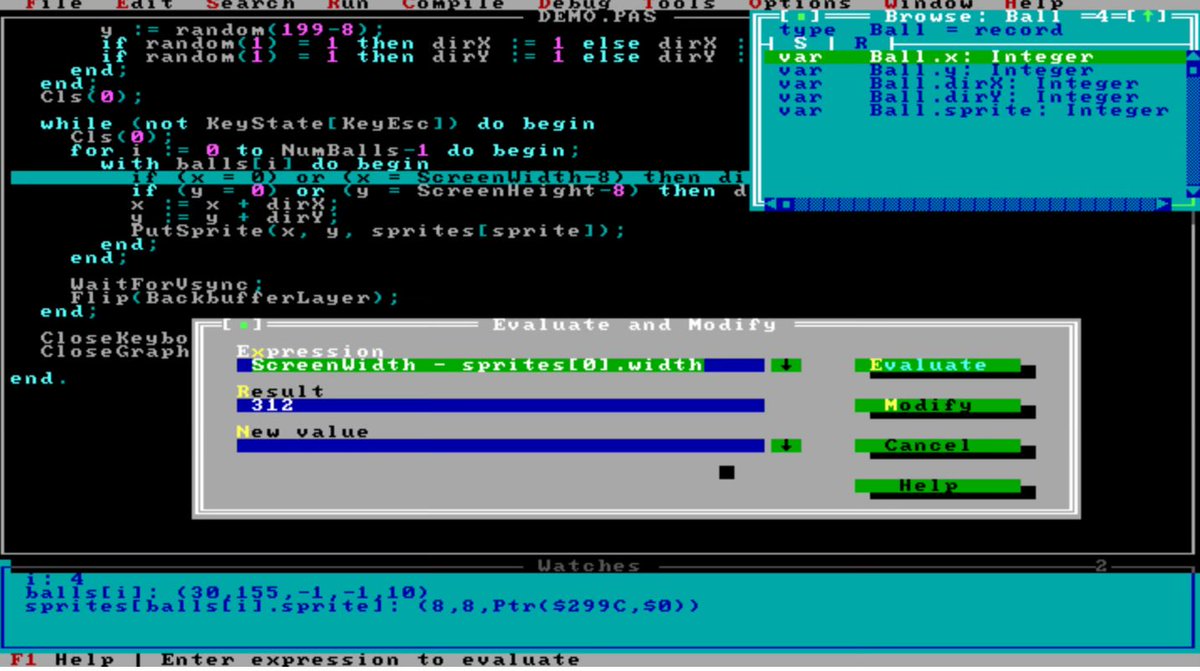
English
Martin Kunc retweetledi

>finally finished all the GPU puzzles in CUDA C++
>rewriting everything from scratch actually helped a lot.
>from now on I’ll be documenting everything I learn in this repo
github.com/jalexine/gpuco…
English
Data Learers' Manifesto is a though provoking set of questions for organizations about what data driven means, summarizes the lack of data management and points out the benefits in managing the data properly: dataleaders.org/manifesto/
English
good morning
>day 11 of unemployment
>chapter 5 of pmpp
>the goal here isn’t to read the whole book, just enough to start reimplementing papers

English
Martin Kunc retweetledi
As a kid, I was always getting into trouble at school—the weird one asking offbeat questions. Today, I’d probably be labeled and medicated.
I vividly remember refusing to memorize multiplication tables. My teacher insisted, “It’s important!” But I’d just visited my cousin with his shiny new electronic calculator. I shot back: “With calculators everywhere, why does this matter?” Boom—big trouble for that cheeky question.
And no, before you ask: I never did learn those tables.
Later, fresh out of my PhD, I launched a business with zero experience or mentors. It went okay for a while, but man, was it stressful. The issue? I don’t lie. Sure, I slip up accidentally like anyone, but deliberate deception? I hate it and suck at it. When clients asked, “How long will this take?” I’d honestly reply: “I don’t know.”
Even now, when I do industry consulting, I stick to the truth. I recall one client handing me a 10-page infrastructure summary and asking for efficiency tips. I paused and said: “I don’t know.” They countered, “Another consultant whipped up a full plan in minutes!” My response: “I wouldn’t trust that guy.” Unfortunately, many people are willing to pay for lies. I try hard to spot these people and decline to work with them.
Working as a government researcher shocked me—the institutional lies were everywhere. My boss would blatantly lie to an industry representative right in front of me. Universities, where I work now, might be even worse: lies stacked sky-high. Modern universities sell lies on a grand scale. Each of them is made of tens of Einstein-level researchers. If only they receive a bit more money, they will cure cancer. They are all dedicated to the well being of their students while outsourcing most of the teaching to low-paid staff. No wonder so many academics are unwell.
That early business stress? It wasn’t from lies I told. It came from the pressure to start lying. I only recognize the source of the stress years later. Had I been more self-aware, I'd have been calmer and more efficient.
I’m convinced lies corrode your soul and weaken you.
“The truth will set you free.”
« But Daniel, won't lies make you more money? » We live in an imperfect world where lies keep you out of trouble and may even help you on your way to the top. But lying has a cost that might far outweight the benefits.
See, we are not playing a game of Monopoly where taking money for the bank while nobody is watching can make you win the game... Your primary objective should be to be someone you can be proud of. Nobody cares, not really, about how much money you earned or how many prizes you won. Sure, you can lie and still feel good about youself, but rationalisation will only take you so far.
English
Martin Kunc retweetledi

A. Babiš a pokračování českého "ne-eura"...
Úroky, které naše země platí za státní dluh, patří k těm vyšším v Evropě. Přesněji: zatímco Německo platí za desetileté půjčky úrok 2,6 %, Slovensko (s nízkým ratingem a hroznou vládou) 3,4 %, podobně jako krizí sužovaná Francie, český úrok činí - přes vysoký rating - více než 4,3 %.
Při dnešním stavu schodků a plánech vlády @AndrejBabis bych tipoval, že se náš státní dluh posune do konce dekády k 5 tisícům miliard korun.
Kvůli "ne-euru" za něj budeme i dál platit vysoké úroky.
Při našem ratingu a nízkém dluhu si myslím, že naše sazba by v případě přijetí eura byla někde kolem 3 % (tam je Slovinsko, Bulharsko či Portugalsko). Stát by tedy ušetřil (postupně, po splacení dluhopisů s nižším úrokem z minulosti) v další dekádě zhruba 65 miliard korun ročně. To je obrovská suma, odpovídající spoustě užitečných výdajů, nebo - zjednodušeně řečeno - "dárku" každému občanovi ve výši téměř 6 tisíc korun ročně.
Další desítky miliard by po přijetí eura ušetřily i firmy díky dostupnosti levnějších úvěrů.
Pokud je Andrej Babiš tak racionální člověk, jak o sobě říká (a někteří mu věří), snadno zjistí, že získat silnou podporu pro přijetí eura je velmi snadné. Místo toho ale vytváří vládu, která - kromě primárního cíle nevydat pány Babiše a Okamuru justici ke stíhání - bude silně stát za pokračováním českého "ne-eura".
To je ostatně jeden z hlavních požadavků hlavního partnera A. Babiše, Motoristů.

Čeština
@alexinexxx Hi, hope you will find a job soon. What do you use for cuda vm ?
English
good morning
>first day of unemployment
>gpu programming seems so cool
>wrote my first kernels

English
Martin Kunc retweetledi

So Python 3.14 finally came out for real yesterday. Finally removing the GIL (global interpreter lock), which allows for way faster multithreaded code without dealing with all the brain damage and overhead of multiprocessing or other hacky workarounds. And uv already fully supports it, which is wildly impressive.
But anyway, I was a bit bummed out, because the main project I’m working on has a massive number of library dependencies, and it always takes a very long time to get mainline support for new python versions, particularly when they’re as revolutionary and different as version 3.14 is.
So I was resigned to endure GIL-hell for the indefinite future.
But then I figured, why not? Let me just see if codex and GPT-5 can power through it all. So I backed up my settings and asked codex to try, giving it the recent blog post from the uv team to get it started.
There were some major roadblocks. I use PyTorch, which is notoriously slow to update. And also pyarrow, which also didn’t support 3.14. Same with cvxpy, the wrapper to the convex optimization library.
Still, I wanted to see what we could do even if we had to deal with the brain damage of “vendoring” some libraries and building some stuff from scratch in C++, Rust, etc. using the latest nightly GitHub repositories instead of the usual PyPi libraries.
I told codex to search the web, to read GitHub issue pages, etc, so that we didn’t reinvent the wheel (or WHL I should say, 🤣) unnecessarily.
Why not? I could always test things, and if I couldn’t get it to work, then I could just retreat back to Python 3.13, right? No harm, no foul.
Well, it took many hours of work, almost all of it done by codex while I occasionally checked in with it, but it managed to get everything working!
Sure, it took a bunch of iterations, and I had to go tweak some stuff to avoid annoying deprecation warnings (some of which come from other libraries, so I ultimately had to filter them).
But those libraries will update over time to better support 3.14 and eventually I won’t need to use any of these annoying workarounds.
Codex even suggested uploading the compiled whl artifacts to Cloudflare’s R2 (like s3) so we could reuse them easily across machines, and took care of all the details for me. I would never think to do that on my own.
Every time there was another complication or problem (for instance, what is shown in the screenshot below), codex just figured it out and plowed through it all like nothing.
If you’ve never tried to do something like this in the “bad old days” prior to LLMs, it was a thankless grind that could eat up days and then hit a roadblock, resulting in a total wipeout.
So it was simply too risky to even try it most of the time; you were better off just waiting 6 or 9 months for things to become simple again.
Anyway, I still can’t really believe it’s all working! We are living in the future.

English
Martin Kunc retweetledi
This UC Berkeley professor is now telling his Computer Science students to « be good at a lot of different things because we don’t know what the future holds. »
We should always tell young people: learn to get good at more than one thing, as quickly as possible. It does not matter what the young person is studying or where they live.
When you have decades of experience, you are likely to ‘be good at different things’ because that’s the natural trajectory of most decent careers: you end up working on several different problems. Most successful people in their forties or fifties have two or more areas of expertise.
When you are young and inexperienced, your most glaring fault is that you haven’t had time to get good at many things. Too often, young people focus narrowly on one specific expertise not realizing the downsides.
The first downside, obviously, is that employers may not specifically need your one expertise. But the second, equally important downside, is that you will lack critical thinking if all you know is one specific technology or technique.
The mistake young people make is to think that if they get really, really good at this ‘one thing’ then they are set for life. And that’s true for some, but it is statistically false. Very few people have a good career with one specific expertise. There are many reasons why this strategy fails. One of them is that it is really, really hard to get really, really good at any one thing. That is, it is far easier to be in the top 1% in two areas of expertise, than to be in the top 0.1% in one area. Expertise follows a Pareto distribution: it is relatively easy when you get started, and the deeper you dig, the harder it gets. The second reason is that the landscape is dynamic. By the time you have become an expert at this one thing, the demand can fall.
English
Martin Kunc retweetledi
Soviet Russia initiated government-planned science. Scientists worked for the state and followed bureaucratic plans. In exchange, they received reliable funding and state recognition.
In the 1970s, the West began emulating the Soviet model. It started generously funding government agencies, like the NSF in the USA. These agencies adopted 5-year plans, directly inspired by the Soviet model. To this day, throughout the West, we require scientists to write such plans, and large government bureaucracies manage science.
As a result, we massively increased the number of PhDs as a percentage of the population. We have far more active scientists than ever in human history. The number of research papers published per year follows an exponential curve.
You would imagine that all this new government funding and planning would result in a golden era for science. But it did not. We are very good at producing research papers but much less effective at producing results. Outside AI and computing, much of which happens in corporations, we are simply stagnating.
Copying Soviet Russia was a mistake.

English
Martin Kunc retweetledi

Why high achievers are trapped in Jung’s Shadow—
and how it's KILLING their creativity.
Here are 5 steps to see if you're stuck in the Shadow...
[And how to reverse it]. 🧵


English