Sabitlenmiş Tweet

LTM-2-Mini is our first model with a 100 million token context window. That’s 10 million lines of code, or 750 novels.
Full blog: magic.dev/blog/100m-toke…
Evals, efficiency, and more ↓
English
Magic
28 posts

@magicailabs
Long-context, test-time compute, and e2e Reinforcement Learning to build a superhuman coding agent (that then builds the rest of AGI for us). Join us https://t.co/hGZKtUzsR3
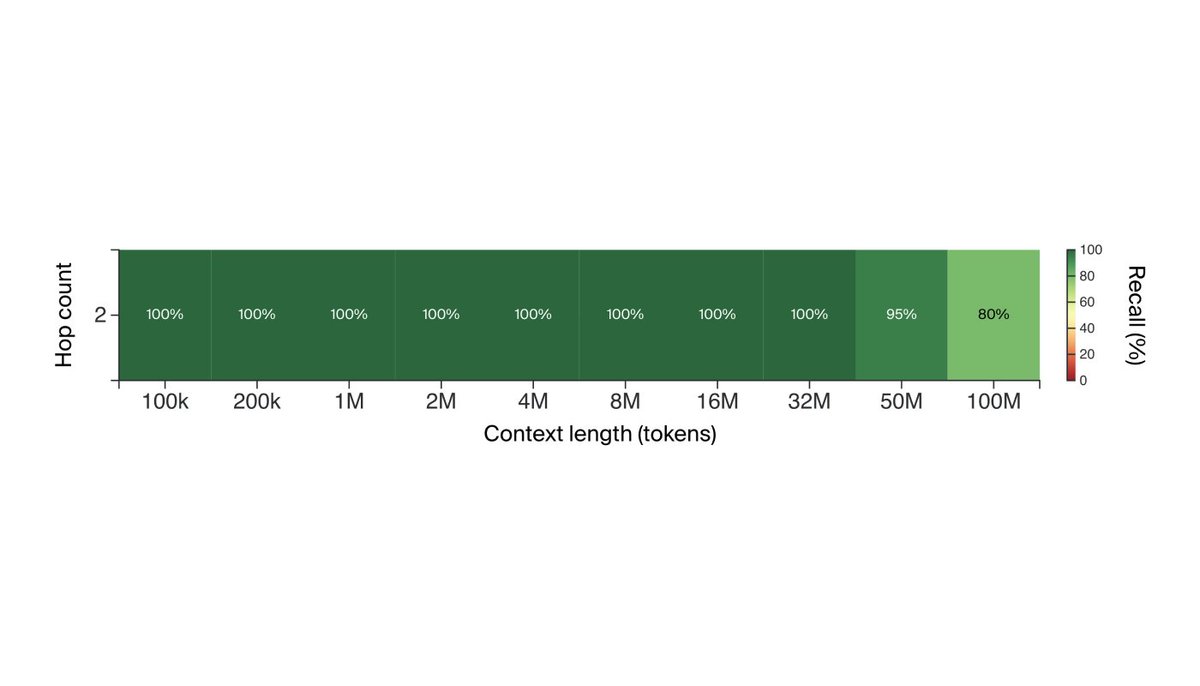


Needle in a Haystack tests The tech report also details a number of microbenchmark “needle in a haystack” tests (modeled after @GregKamradt’s github.com/gkamradt/LLMTe…) that probe the model’s ability to retrieve specific information from its context. For text, Gemini 1.5 Pro achieves 100% recall up to 530k tokens, 99.7% up to 1M tokens, and 99.2% accuracy up to 10M tokens.

Magic.dev has trained a groundbreaking model with many millions of tokens of context that performed far better in our evals than anything we've tried before. They're using it to build an advanced AI programmer that can reason over your entire codebase and the transitive closure of your dependency tree. If this sounds like magic... well, you get it. Daniel and I were so impressed, we are investing $100M in the company today. The team is intensely smart and hard-working. Building an AI programmer is both self-evidently valuable and intrinsically self-improving. If this sounds interesting to you, consider joining them!


We've raised $117M from @natfriedman and others to build an AI software engineer. Code generation is both a product and a path to AGI, requiring new algorithms, lots of CUDA, frontier-scale training, RL, and a new UI. We are hiring!



Meet LTM-1: LLM with *5,000,000 prompt tokens* That's ~500k lines of code or ~5k files, enough to fully cover most repositories. LTM-1 is a prototype of a neural network architecture we designed for giant context windows.
Meet LTM-1: LLM with *5,000,000 prompt tokens* That's ~500k lines of code or ~5k files, enough to fully cover most repositories. LTM-1 is a prototype of a neural network architecture we designed for giant context windows.
Meet LTM-1: LLM with *5,000,000 prompt tokens* That's ~500k lines of code or ~5k files, enough to fully cover most repositories. LTM-1 is a prototype of a neural network architecture we designed for giant context windows.