Sabitlenmiş Tweet

The modern data warehouse for PostgreSQL has arrived!
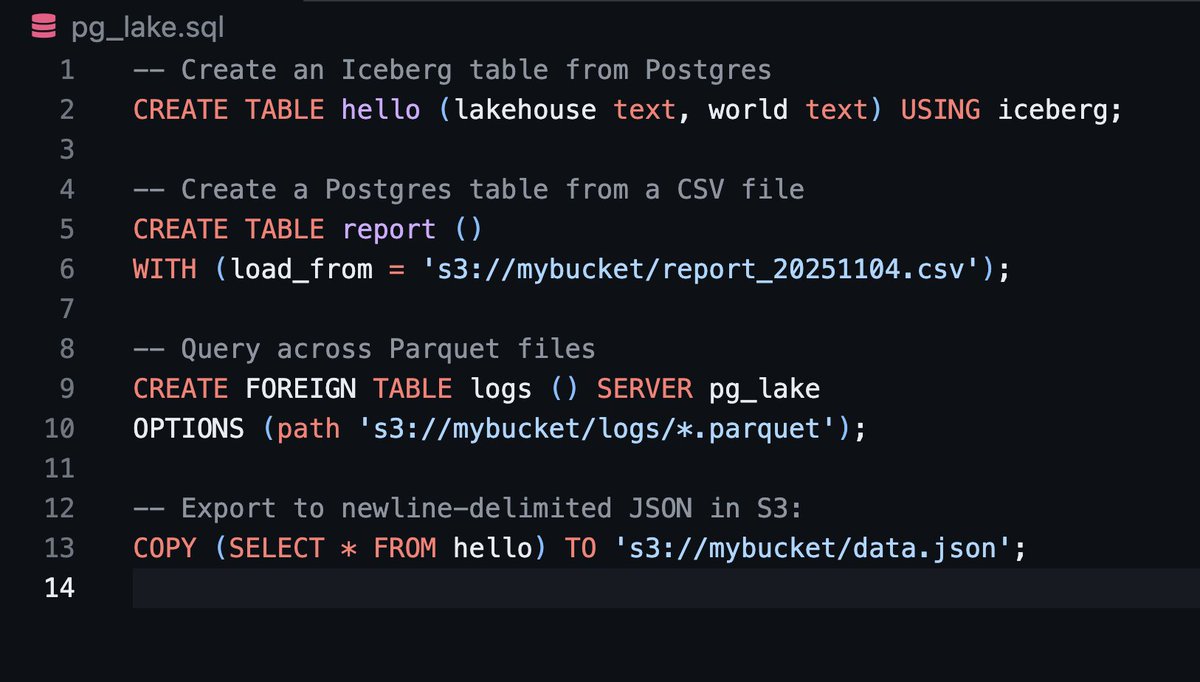
Crunchy Data Warehouse is PostgreSQL enhanced for fast analytics and data pipelines, powered by Iceberg and DuckDB, with easy data lake query/import/export, fast local disk cache, managed for you by the team at Crunchy Data.
Crunchy Data@crunchydata
Announcing Crunchy Data Warehouse! A next-generation Postgres-native data warehouse. Full Iceberg support for fast analytical queries and transactions, built on unmodified Postgres to support the features and ecosystem you love. crunchydata.com/blog/crunchy-d…
English