YouTube

Español
Marcos
2.8K posts

@marfinfo
Computer engineer, PhD in education, professor-researcher at TecnoCampus UPF. Enjoying so much teache artists how to code.
El futur de les universitats? Una aula virtual amb un professor que explica i respon preguntes, un assistent que dona tutorització personalitzada, i companys de classe amb diferents perfils amb qui interactuar. Tot generat en menys d'una hora per 2 dolars open.substack.com/pub/pepmartore…


Professors Say AI Is Destroying Their Students' Ability to Think | Frank Landymore, Futurism Professors are fighting an uphill battle against the intrusion of AI into education, and it’s forcing them to rethink how they instruct their students, many of whom have already become hopelessly dependent on the tech. “It’s driving so many of us up the wall,” one told The Guardian in a new piece that interviewed more than a dozen professors in the humanities. “I now talk about AI with my students not under the framework of cheating or academic honesty but in terms that are frankly existential,” Dora Zhang, a literature professor at UC Berkeley said. “What is it doing to us as a species?” Alas, students looking for an easy “A” may not be interested in philosophical inquiries on how AI is fundamentally changing how we interact with the world and with each other — and indeed, according to a burgeoning body of research, how our brains work. One canary in the coal mine comes from a Carnegie Mellon study published in early 2025 that found that knowledge workers who regularly used and trusted the accuracy of AI tools were losing their critical thinking skills. An earlier study found a link between students who relied on ChatGPT and memory loss, procrastination, and worsening academic performance. And an MIT study that performed EEG scans on subjects who were asked to write essays with and without ChatGPT found that AI users had the lowest levels of cognitive engagement during the tasks. Working in the trenches, most professors, especially in the humanities, probably didn’t need formal research to tell them what those studies found, when they could easily intuit it by interacting with their pupils. Michael Clune, a literature professor and novelist, lamented to The Guardian that many students are now “incapable of reading and analyzing, synthesizing data, all kinds of skills.” Clune’s school, Ohio State University, recently required all students to enroll in “AI fluency” courses “across every major,” ostensibly to prepare them for a world that is dominated by the tech. Clune was critical of the push. “No one knows what that means,” he told newspaper. “In my case, as a literature professor, these tools actually seem to mitigate against the educational goals I have for my students.” OSU may be the most egregious example of capitulating to the whims of Big Tech, but the AI industry has its tendrils all across education. Companies like OpenAI and Microsoft have poured tens of millions of dollars into teachers’ unions, providing training on how to use their AI systems. They’ve also partnered with numerous institutions to provide their students with free access to their AI tools. Duke University, after entering such a partnership with OpenAI, introduced its own AI tool called “DukeGPT.” Abroad, xAI founder Elon Musk partnered with the government of El Salvador to launch the “world’s first nationwide AI-powered education program” to provide his Grok chatbot to a million students across thousands of public schools. “These companies are giving these technological tools away partly because they’re hoping to addict a generation of students,” Eric Hayot, a comparative literature professor at Penn State, told The Guardian. “This is part of every single class I teach now, talking to students about why I’m not using AI, why they shouldn’t use AI.” But pedagogues aren’t taking this sitting down. Some are now using oral interrogations and requiring handwritten notebooks, they told the paper. AgainstAI, a faculty-run initiative that advises professors on how to work around AI use, recommends giving assignments like oral exams, requiring students to show pictures of their notes, and paper journals. Some even dare to be optimistic. Several said they noticed more students pushing back or expressing more cynicism about AI tools. “I think the current crop of gen Z students are seeing that they are the guinea pigs in this giant social experiment,” Zhang said. “There’s kind of defeatism, this idea that there’s no stopping technology and resistance is futile, everything will be crushed in its path,” Clune added. “That needs to change… We can decide that we want to be human.” futurism.com/artificial-int…


this is so fucking wholesome guy used AI to save his cancer-ridden dog by sequencing its DNA and creating a CUSTOM cure. the tech behind this is fucking awesome (well done @demishassabis and the google team): - used CHATGPT to sequence dogs DNA discovers mutations - ran the mutations through Google’s Alphafold (AI protein sequencer) which CREATED A CUSTOM VACCINE TO TREAT THEM. - treated dog and reduced tumour by 50% in WEEKS. dog is alive and well. - this is the 1st time AI has been used to create a custom vaccine for a dog (and it worked) - dude is now working on similar vaccines for humans using AI! 2026 is definitely the year we see AI change personalised medicine in a HUGE way so sick
"This is Maven Smart System—Palantir’s software as a service product that we are deploying across the entire department."





🚨ÚLTIMA HORA: OpenAI publicó un artículo que demuestra que ChatGPT SIEMPRE se inventará cosas. No es un fallo temporal ni falta de datos. Es un problema matematico estructural. Incluso con potencia ilimitada y datos perfectos, los modelos de IA seguiran afirmando falsedades con total seguridad. El deterioro por modelo es notable: • El modelo o1 alucina el 16% de las veces. • El modelo o3 sube al 33%. • El nuevo o4-mini llega al 48%. Casi la mitad de sus respuestas son inventadas. La razon es que estos sistemas funcionan por probabilidad. Al no estar seguros, no se detienen: adivinan. Ademas, los sistemas de evaluacion actuales castigan la honestidad. Decir "no lo sé" otorga la misma puntuacion que dar una respuesta falsa: cero. La IA ha aprendido que la estrategia optima es fingir seguridad absoluta siempre. OpenAI sabe como mitigarlo, pero la solucion mataria el producto. Si el sistema admitiera su incertidumbre, dejaria de responder al 30% de las preguntas de los usuarios. Comercialmente, la honestidad es un suicidio. Institutos como DeepMind y la Universidad de Tsinghua han llegado a la misma conclusion de forma independiente. Tres de los laboratorios mas importantes del mundo coinciden: las alucinaciones son permanentes. La proxima vez que recibas una respuesta de la IA, recuerda que podria ser simplemente una conjetura estadistica muy bien presentada. Tenlo en cuenta.






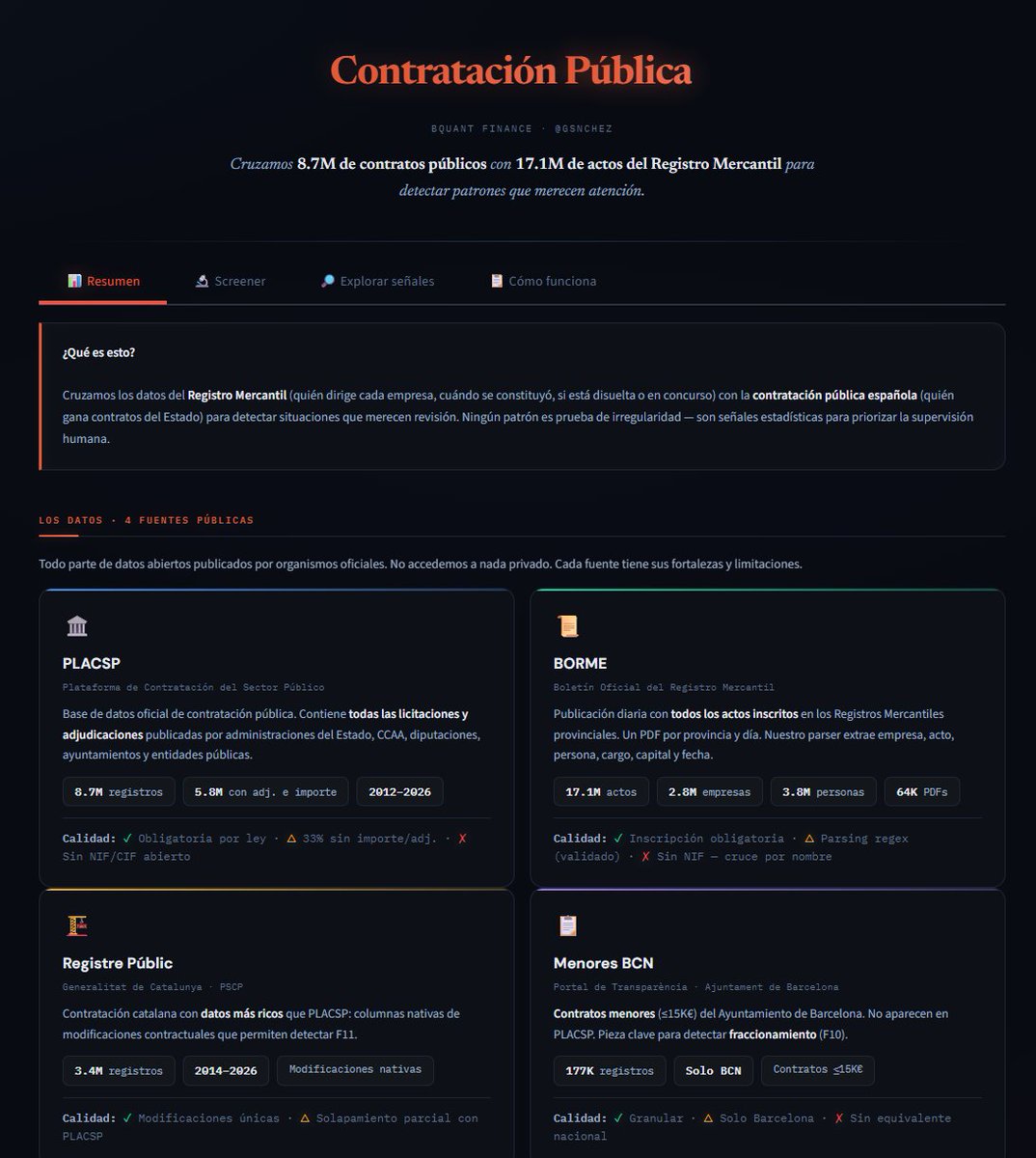
Os comento algunos resultados preliminares: 1/ He parseado 126.065 PDFs del BORME desde 2009 hasta hoy. ¿Por qué 2009? Porque ahí cambió el formato del boletín. Antes de eso la estructura es diferente y requiere otras técnicas, pero 2009-2026 cubre la inmensa mayoría de empresas activas hoy. 2/ El problema del cruce: el BORME no publica el CIF de las empresas. Solo el nombre y los datos registrales (tomo, hoja, inscripción). Así que para cruzar con licitaciones toca hacer matching por nombre normalizado: quitar acentos, unificar formas jurídicas (S.L. = SL = Sociedad Limitada), eliminar paréntesis, guiones, etc. Resultado: de 5,9M de adjudicaciones en el PLACSP, 3,8M cruzan con alguna empresa del BORME. Un 64%, que representa 1.482 mil millones de euros en contratos (67% del importe total). El 36% restante son autónomos (personas físicas que no aparecen en el Registro Mercantil), UTEs, y empresas constituidas antes de 2009. 3/ ¿Y las homónimas? Sin CIF, "CONSTRUCCIONES GARCIA SL" en Madrid y en Sevilla son la misma empresa para nosotros. Para medir el problema, analicé los NIFs del propio PLACSP: el 95% de los nombres normalizados corresponden a un único CIF. La homonimia existe pero es baja. 4/ Con ese cruce he buscado 5 tipos de anomalías: Empresa recién creada: constituida menos de 6 meses antes de ganar un contrato público. Salen 16.337 adjudicaciones. Capital ridículo: empresa con menos de 10.000€ de capital social ganando contratos de más de 100.000€. 71.461 adjudicaciones. Multi-administrador: la misma persona aparece como cargo en más de una empresa. 1.052.326 personas. Este flag todavía está crudo — lo interesante será cruzarlo con PLACSP para ver si esas empresas compiten en las mismas licitaciones. Disolución post-adjudicación: la empresa se disuelve menos de un año después de ganar el contrato. 9.928 adjudicaciones. Adjudicación en concurso: empresa en situación concursal recibiendo contratos públicos. 9.655 adjudicaciones. Ninguno de estos flags es una acusación. Crear una SL con 3.000€ de capital es perfectamente legal. Que un administrador esté en 5 empresas también. Son señales que, acumuladas o combinadas, merecen una segunda mirada. 5/ Lo que falta: cruzar los multi-administradores con licitaciones concretas, analizar cambios de cargos alrededor de las fechas de adjudicación, incorporar contratos menores, y buscar fuentes complementarias de CIF para mejorar el matching. Vamos a ello.





Hace aproximadamente una hora, LaLiga volvió a bloquear sitios web y aplicaciones al azar en España. En el pasado, esto a menudo ha incluido romper la banca en línea, Bizum, etc., para muchos usuarios. Así que, si sales esta tarde, lleva efectivo - o ten el VPN activado.