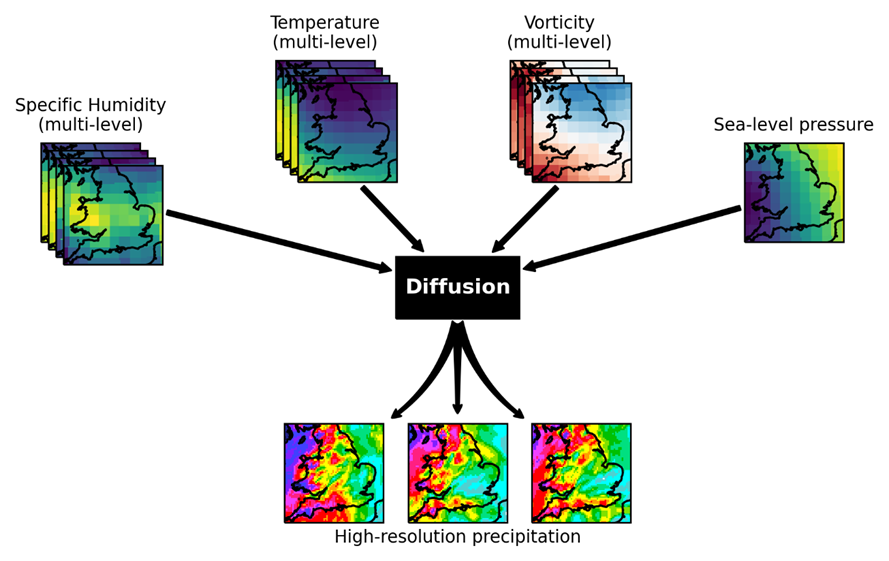
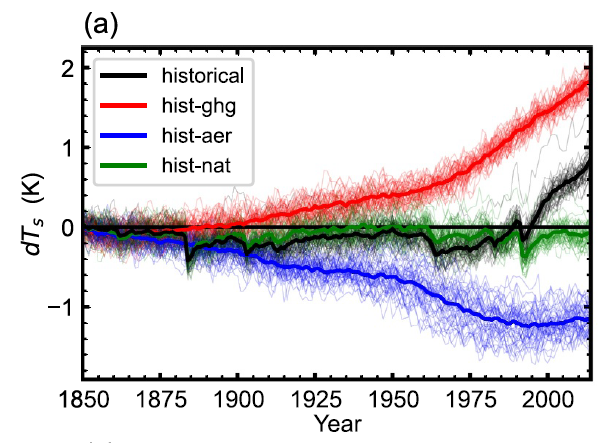
Mark J. Webb retweetledi

We also applied AlphaEvolve to over 50 open problems in analysis ✍️, geometry 📐, combinatorics ➕ and number theory 🔂, including the kissing number problem.
🔵 In 75% of cases, it rediscovered the best solution known so far.
🔵 In 20% of cases, it improved upon the previously best known solutions, thus yielding new discoveries.
English