Sabitlenmiş Tweet

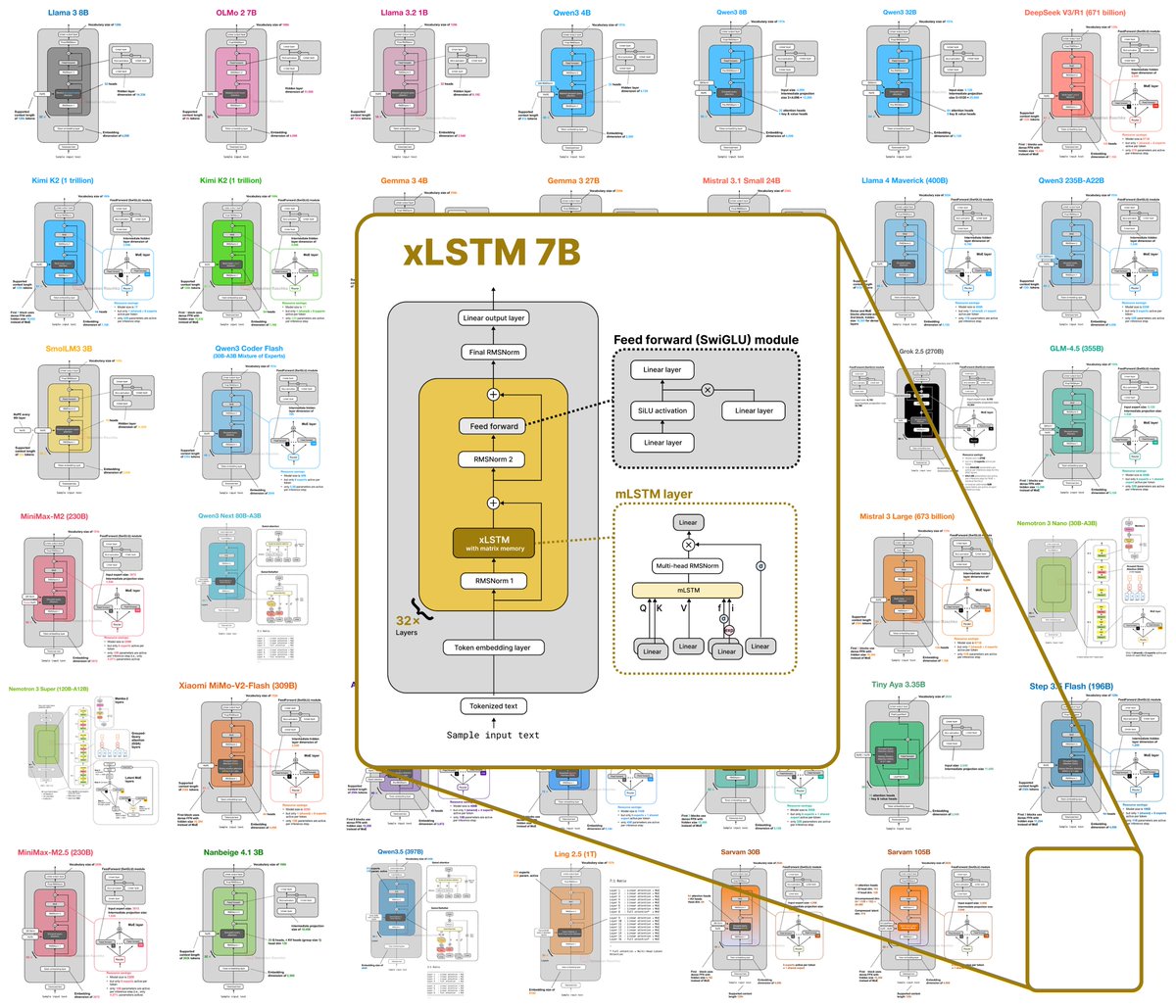
Yesterday, we shared the details on our xLSTM 7B architecture. Now, let's go one level deeper🧑🔧
We introduce
⚡️Tiled Flash Linear Attention (TFLA), ⚡️
A new kernel algorithm for the mLSTM and other Linear Attention variants with Gating.
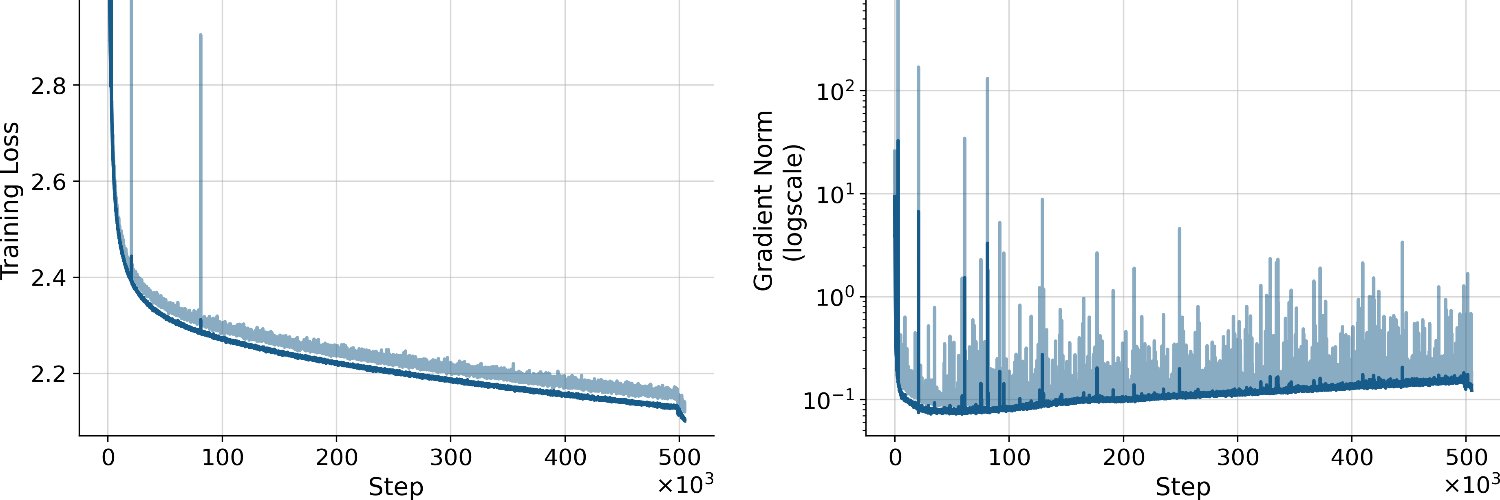
We find TFLA is really fast!
🧵(1/11)

English