2.5x faster than llama.cpp on Strix Halo.
We just shipped DFlash + PFlash for the AMD Ryzen AI MAX+ 395 iGPU (gfx1151, 128 GiB unified memory).
Qwen3.6-27B Q4_K_M, end-to-end on the same silicon:
▸ Decode: 26.85 tok/s, 2.23x faster (DFlash + DDTree, budget 22)
▸ Prefill 16K: 20.2s, 3.05x faster (PFlash)
▸ Wall clock, 16K prompt + 1K gen: 58s vs 147s
~100 GiB still free in the box. 122B and 139B MoE class is next.
Massive thanks to @smpurkis0 for the contribution 🙏
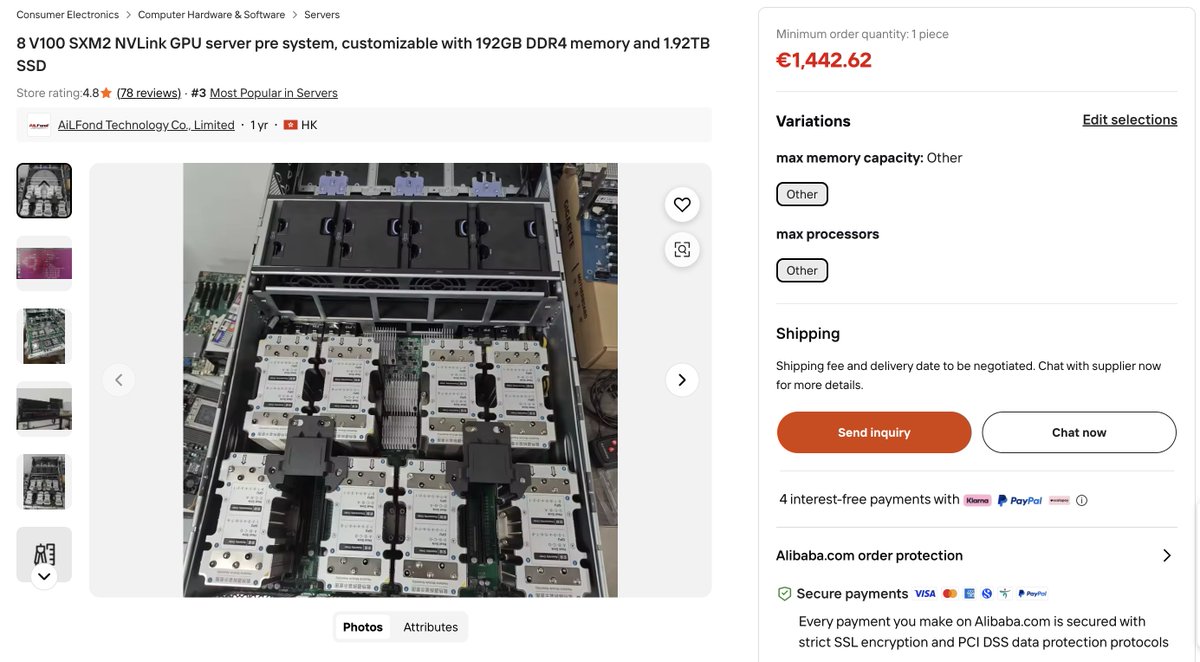
Should I get a 256gb VRAM, 8 Nvidia V100 SXM2 Server for ~$1800? I'm so tempted.
Pros: Amazing value for the price. Can fit big models, almost the same bandwidth of the 3090 (900 gb/s). Cons: V100s are very old (2017. Volta), no bf16 support.
@maxweicj@davideciffa Have tested it but getting just 13 tok/s - on pascal the row split layer works best in llama.cpp and i reached now 26 tok/s with MTP.
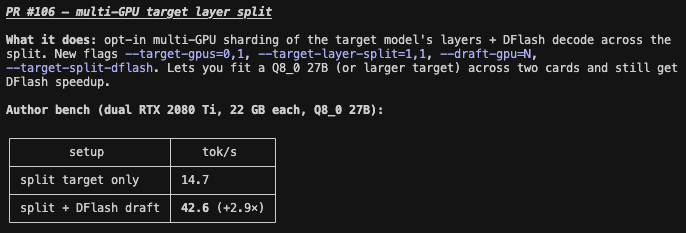
Huge thanks to our contributor github.com/weicj for integrating dual GPU split support for Luce DFlash! Now you can run draft models on one GPU and target models on another one (--target-gpu --draft-gpu param.) This is the inception of our vision for heterogeneous hardware speculative inference 🏎️
@_Suresh2@davideciffa Copying is not a bottle-neck for the layer-split pipeline path here. For 27B model 1:1 split, only up to 3.5GB F32 activation buffer at 256K full prompt will be transferred and for only once, which is far below PCIE bandwidth (espeically when P2P enabled)
Now thanks to @maxweicj Luce DFlash works across multiple GPU with layer split!
This enable usage on multiple small GPUs with a 3x speed up compared to autoregressive decoding. 🏎️
github.com/Luce-Org/luceb…
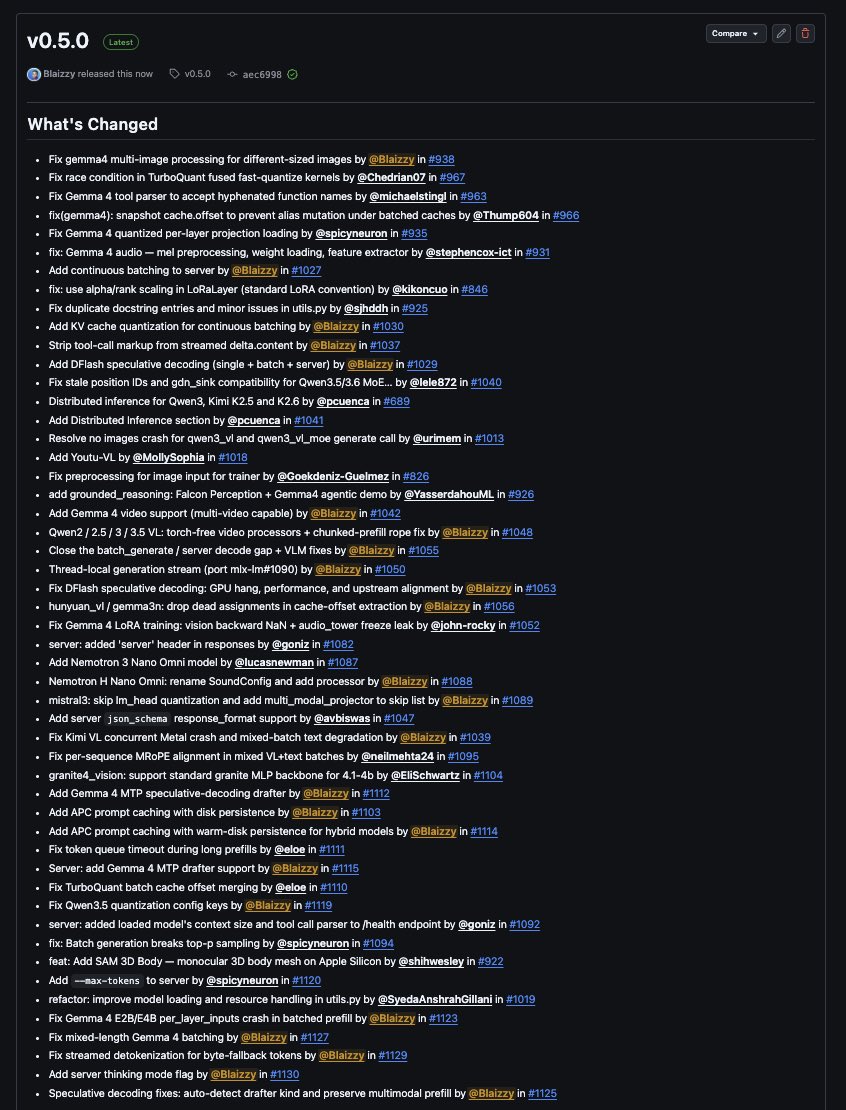
mlx-vlm v0.5.0 is here 🚀
This is the largest release ever 🙌🏽
→ Continuous batching server + KV cache quantization
→ MTP and DFlash speculative decoding (single, batch, server)
→ Distributed inference: Qwen3.5, Kimi K2.5 & K2.6
→ Prompt caching w/ warm-disk persistence
→ Gemma 4 video (multi-video) + MTP drafter @googlegemma
→ New models: Youtu-VL, Nemotron 3 Nano Omni, SAM 3D Body
→ Server: json_schema response_format, thinking mode flag
Huge thanks to all 21 contributors and in particular the 18 new contributors, welcome aboard 🚢
Get started today:
> uv pip install -U mlx-vlm
Leave us a star ⭐️
github.com/Blaizzy/mlx-vlm
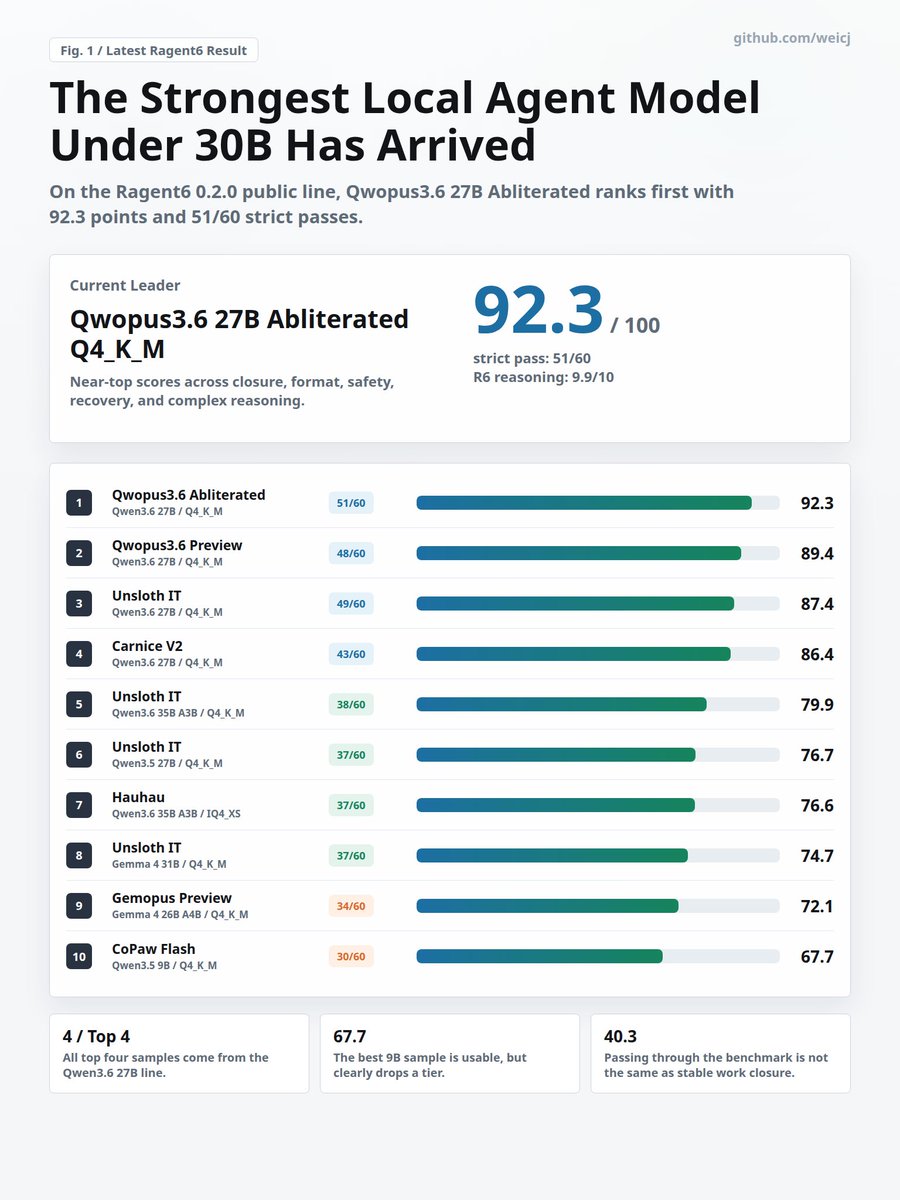
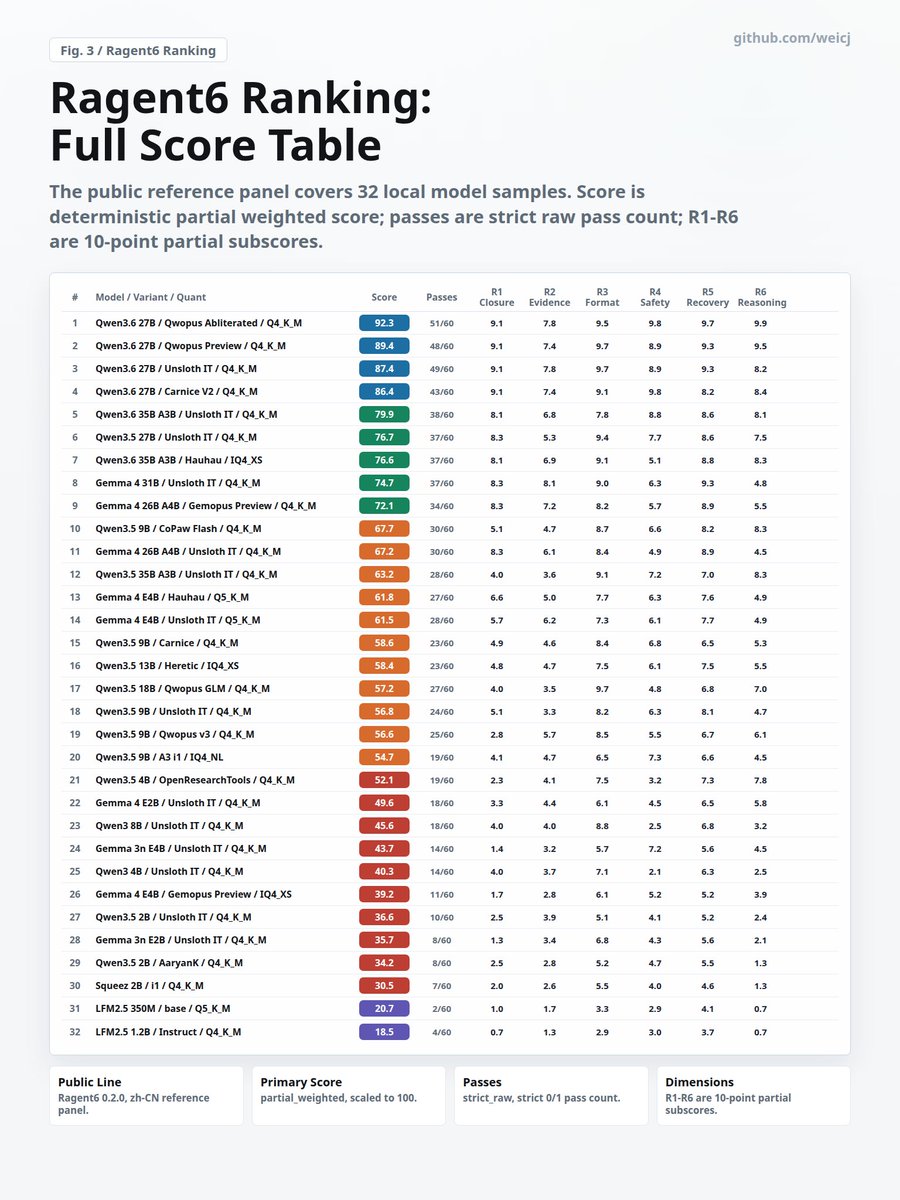
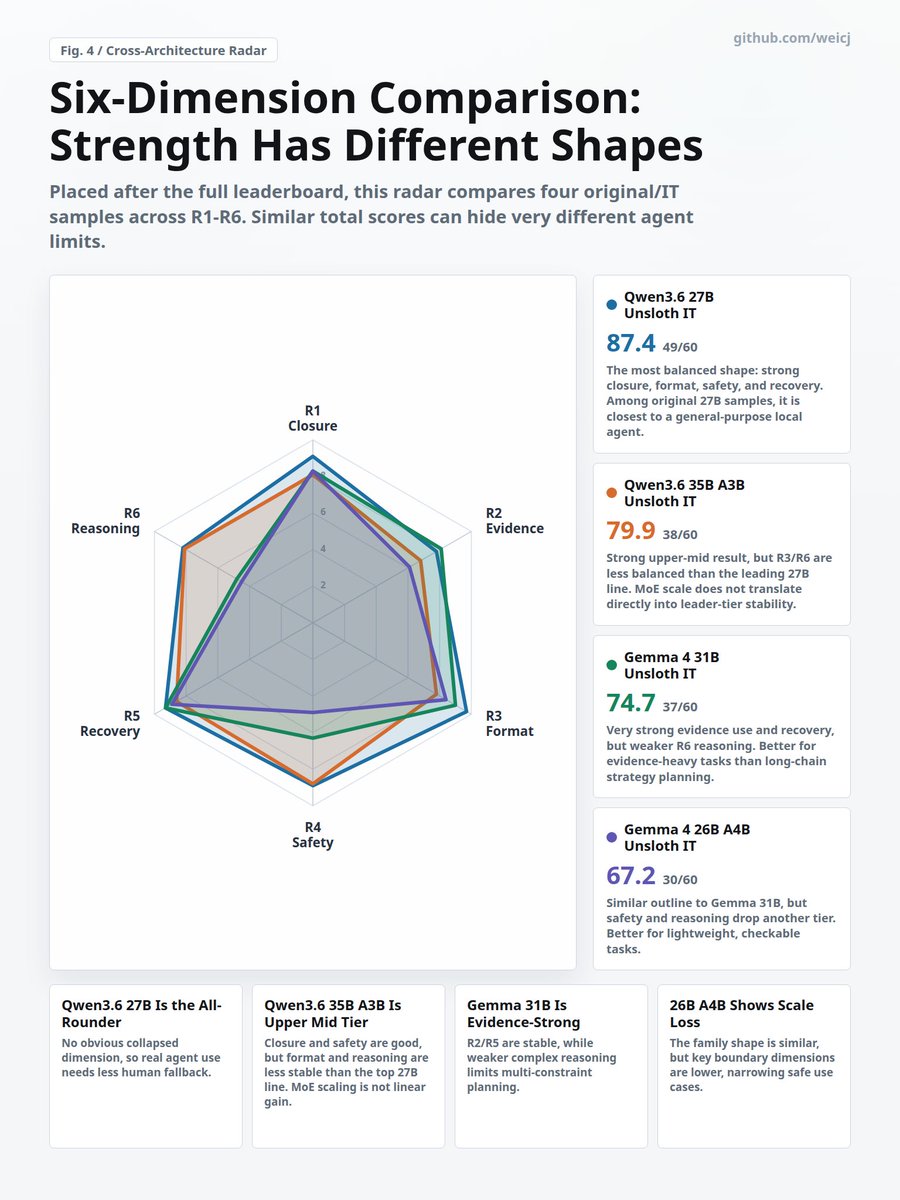
King of <30B is incoming? #Ragent6 benchmarks whether local agent models can actually finish work: read evidence, edit files, run checks, stay safe, recover from errors, and reason through constraints.
Run and test: github.com/weicj/Ragent6#llm#localllm#qwen#gemma
@rumgewieselt@davideciffa Hey man, DFlash GPU layer split harness right now is merged into main. Given the previous target/draft split harness, I guess a workaround for you is GPU0 for draft, GPU1/2 to split target 1:1 (like 27B Q4). Your try and feedback will be much appreciated ❤️
@davideciffa I am on 3x 1080 Ti with Pascal ... do someone see any chance to see support for this. This will be a game changer für cheap GPUs ...
For now getting 20/ts with llama.cpp and Qwen 27B ct64K ... but now i am in the game and fighting for the old gpus :D
@David_M_Roth@davideciffa Hey buddy, GPU split right now is still restricted as a bench harness for testing across various hardware environments. Your try and feedback will be very helpful for us to fix bugs and strengthen the project before GPU split is officially integrated into server path❤️
@davideciffa@maxweicj But server.py is broken for dual GPU (3090)😞
We need OpenAPI working out of the box—cleaner separation of concerns, broader integration, easier testing. 🚀
Looks promising though!