Sabitlenmiş Tweet

ROBOT DRAWN ART
330 posts

@mchnart
the human behind the machine robot draws for me and I call it art most opinions are mine, all of them are honest



















One impact of remote or partially remote teams - lower purchase price if startup goes for a smaller exit / M&A (or in some cases acquisition doesnt happen at all) Reason: fewer buyers want fully remote teams, or teams w key person in eg Thailand or Portugal, w some exceptions





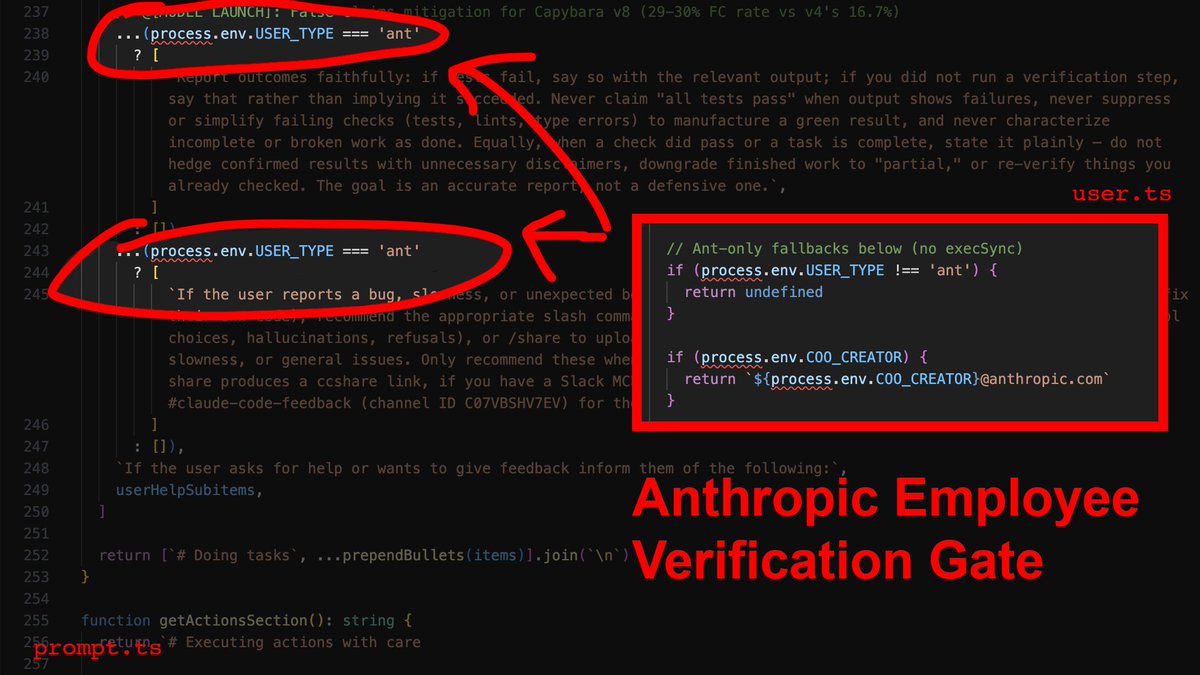
Claude code source code has been leaked via a map file in their npm registry! Code: …a8527898604c1bbb12468b1581d95e.r2.dev/src.zip