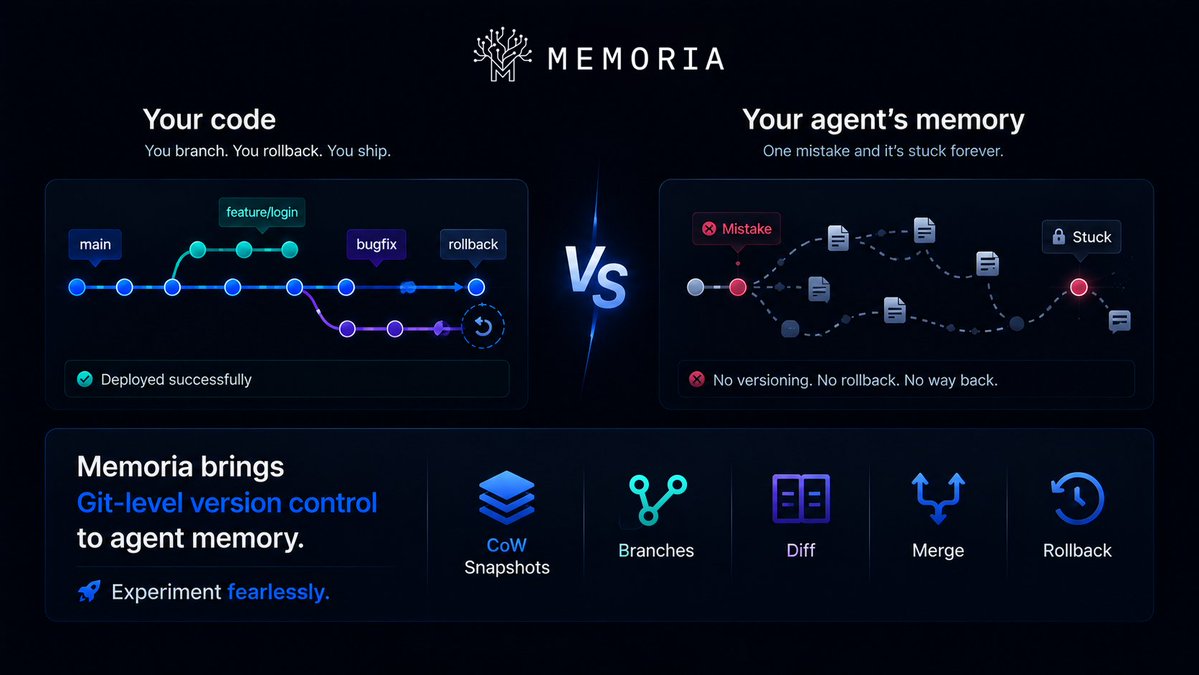
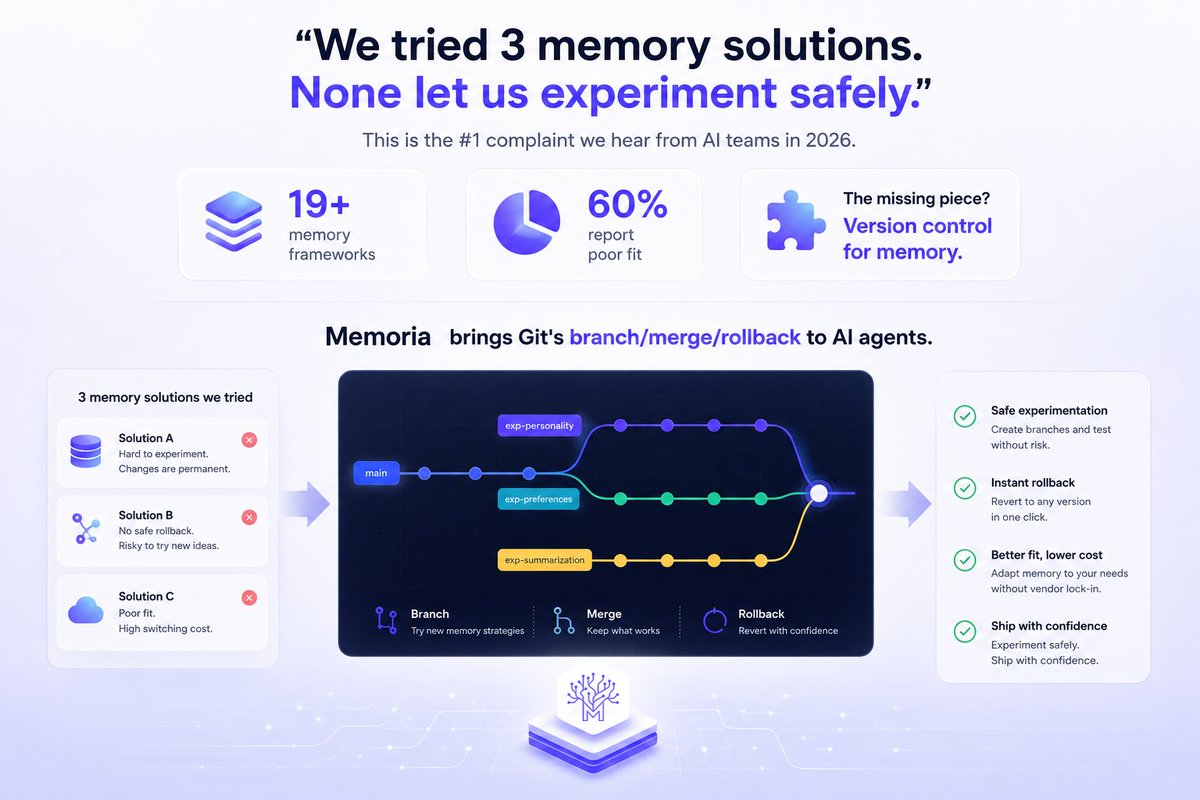
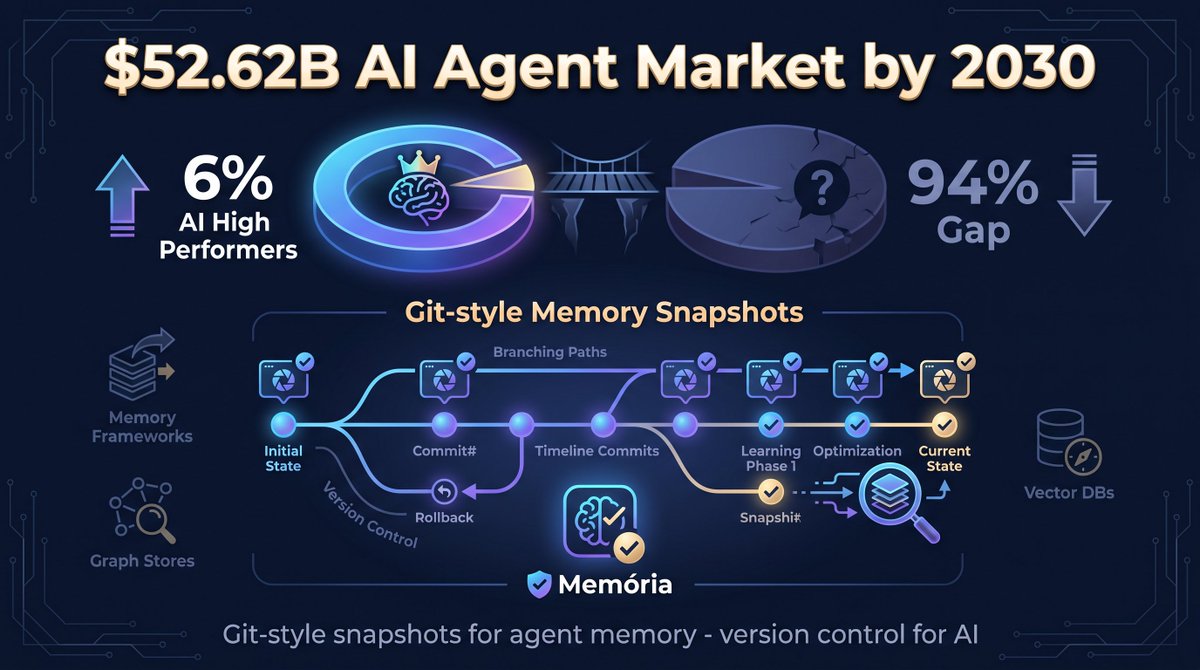
Mem0, Zep, Letta — 84K+ stars, $34M+ funding. They nail retrieval. But none answer: "Can I undo what my agent just remembered?"
Memoria = Git for agent memory. Snapshots, branching, diff, rollback.
The missing piece the big three never built.
Try it:thememoria.ai/?utm_source=tw…
#AIAgents #AgentMemory #GitForData #Memoria

English