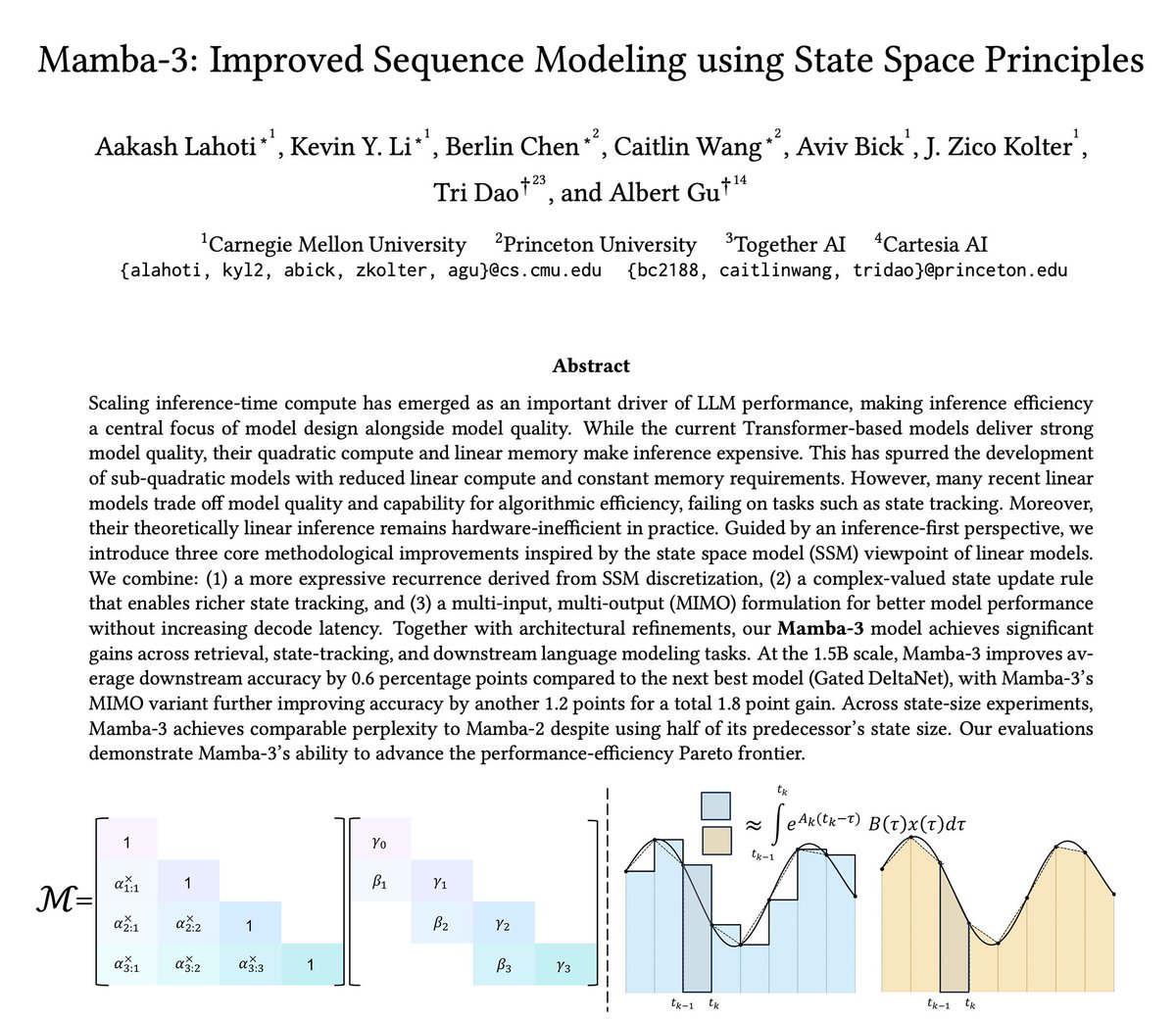
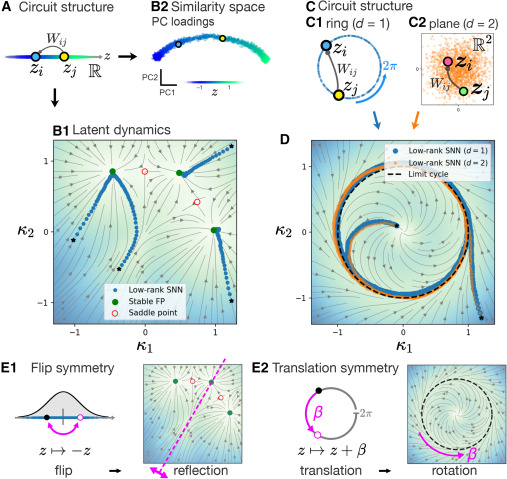
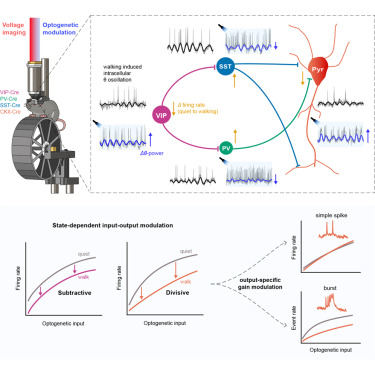
M Ganesh Kumar retweetledi

Neural manifolds do not map one-to-one onto circuit architecture. This study shows that distinct recurrent circuits can generate similar low-dimensional dynamics, yet still leave identifiable constraints on neural selectivity and population activity.
cell.com/neuron/fulltex…
English