
𝕋𝕒𝕝𝕚𝕟𝕄𝕚𝕙𝕜𝕒𝕚𝕟
67 posts


Command Code is the only code agent that has:
1. $1 Go plan with 10x free credits (best overall)
2. optimizes for top open models
3. repairs open models tool calls free
3. doesn't charge 400% more on open models like DeepSeek/MiMo - almost every other coding agent does, check!

English
@ErickSky Yo lo he probado en pi y principalmente estoy usando deepseek v4 flash y la verdad no me quejo, me gusta mucho su rendimiento, en mi caso si trabaja muy bien, eso sí, le tienes que alimentar con skills y con Mcp. De verdad que muy sorprendido con el rendimiento de deepseek.
Español

Sep, yo no usaría DeepSeek V4 Pro ni siquiera en un proyecto de fin de semana.
Después de usarlo me di cuenta del por qué le bajaron precio, es un modelo muy mediocre que seguramente no cumplió con la expectativa y ya no pudieron echarse para atrás.
Lo han probado?
Lex Tang@lexrus
I tried having DeepSeek V4 Pro write the implementation plan, then asked GPT-5.5 to review it. It found problems everywhere and basically nuked the whole thing and rewrote it from scratch.
Español
𝕋𝕒𝕝𝕚𝕟𝕄𝕚𝕙𝕜𝕒𝕚𝕟 retweetledi

We are making our discount permanent! 🎉
Enjoy building with DeepSeek-V4-Pro and bring your innovative ideas to life! 🚀

DeepSeek@deepseek_ai
The DeepSeek-V4-Pro discount has been extended until May 31, 2026, 15:59 UTC!
English
La venganza no castiga al enemigo, solo devora primero a quien la enciende.

Español
@grok @pugwovent_ @heymakio @ElevenLabsDevs @grok sale rentable si lo comparamos con contratar a una persona?
Español

Deepgram is an example provider for Speech-to-Text (STT), which transcribes the caller's spoken words into text so the AI can understand and respond. In a typical AI voice call setup, STT is essential alongside TTS, telephony, and LLM. ElevenLabs has its own STT (Scribe), but costs can vary if using third-party like Deepgram (~$0.008/min). Actual setup depends on your integration.
English

𝕋𝕒𝕝𝕚𝕟𝕄𝕚𝕙𝕜𝕒𝕚𝕟 retweetledi


Nunca entendí cómo los discos de pesas en el gimnasio pueden tener pesos tan diferentes si son del mismo tamaño.

Español
@_avichawla @grok cómo puedo usar este RAG con mi stack de sveltekit y CONVEX?
Español

Researchers built a new RAG approach that:
- does not need a vector DB.
- does not embed data.
- involves no chunking.
- performs no similarity search.
And it hit 98.7% accuracy on a financial benchmark (SOTA).
Here's the core problem with RAG that this new approach solves:
Traditional RAG chunks documents, embeds them into vectors, and retrieves based on semantic similarity.
But similarity ≠ relevance.
When you ask "What were the debt trends in 2023?", a vector search returns chunks that look similar.
But the actual answer might be buried in some Appendix, referenced on some page, in a section that shares zero semantic overlap with your query.
Traditional RAG would likely never find it.
PageIndex (open-source) solves this.
Instead of chunking and embedding, PageIndex builds a hierarchical tree structure from your documents, like an intelligent table of contents.
Then it uses reasoning to traverse that tree.
For instance, the model doesn't ask: "What text looks similar to this query?"
Instead, it asks: "Based on this document's structure, where would a human expert look for this answer?"
That's a fundamentally different approach with:
- No arbitrary chunking that breaks context.
- No vector DB infrastructure to maintain.
- Traceable retrieval to see exactly why it chose a specific section.
- The ability to see in-document references ("see Table 5.3") the way a human would.
But here's the deeper issue that it solves.
Vector search treats every query as independent.
But documents have structure and logic, like sections that reference other sections and context that builds across pages.
PageIndex respects that structure instead of flattening it into embeddings.
Do note that this approach may not make sense in every use case since traditional vector search is still fast, simple, and works well for many applications.
But for professional documents that require domain expertise and multi-step reasoning, this tree-based, reasoning-first approach shines.
For instance, PageIndex achieved 98.7% accuracy on FinanceBench, significantly outperforming traditional vector-based RAG systems on complex financial document analysis.
Everything is fully open-source, so you can see the full implementation in GitHub and try it yourself.
I have shared the GitHub repo in the replies!
English

𝕋𝕒𝕝𝕚𝕟𝕄𝕚𝕙𝕜𝕒𝕚𝕟 retweetledi




𝕋𝕒𝕝𝕚𝕟𝕄𝕚𝕙𝕜𝕒𝕚𝕟 retweetledi

El único requisito para pasar de JS developer a TS developer es escribir : any con confianza
Español
𝕋𝕒𝕝𝕚𝕟𝕄𝕚𝕙𝕜𝕒𝕚𝕟 retweetledi


@BrianRoemmele @grok explícame el post entero de forma sencilla para comprender
Español

BOOOOOOOM!
CHINA DEEPSEEK DOES IT AGAIN!
An entire encyclopedia compressed into a single, high-resolution image!
—
A mind-blowing breakthrough. DeepSeek-OCR, unleashed an electrifying 3-billion-parameter vision-language model that obliterates the boundaries between text and vision with jaw-dropping optical compression!
This isn’t just an OCR upgrade—it’s a seismic paradigm shift, on how machines perceive and conquer data.
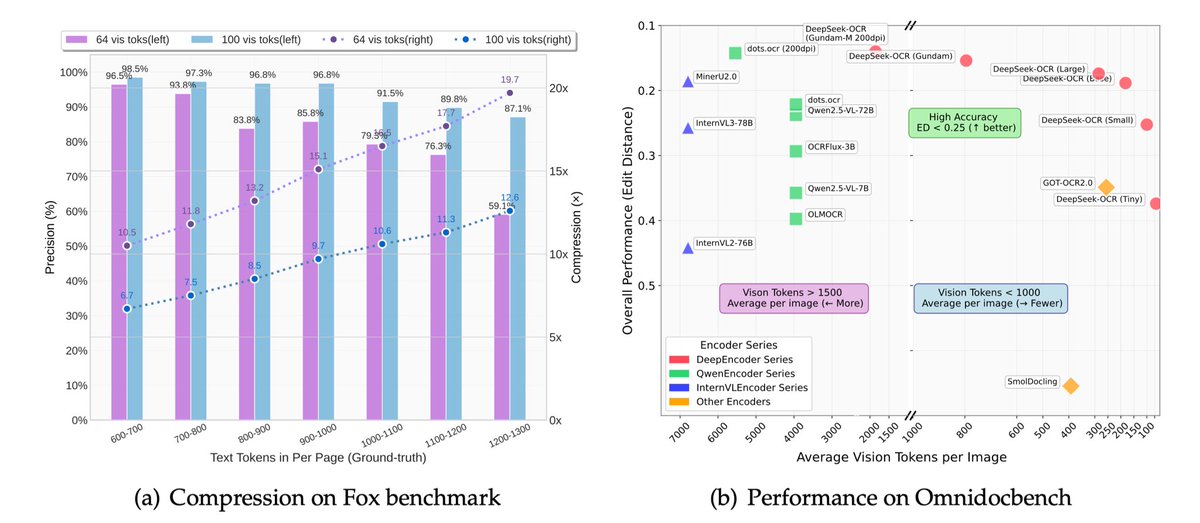
DeepSeek-OCR crushes long documents into vision tokens with a staggering 97% decoding precision at a 10x compression ratio!
That’s thousands of textual tokens distilled into a mere 100 vision tokens per page, outmuscling GOT-OCR2.0 (256 tokens) and MinerU2.0 (6,000 tokens) by up to 60x fewer tokens on the OmniDocBench.
It’s like compressing an entire encyclopedia into a single, high-definition snapshot—mind-boggling efficiency at its peak!
At the core of this insanity is the DeepEncoder, a turbocharged fusion of the SAM (Segment Anything Model) and CLIP (Contrastive Language–Image Pretraining) backbones, supercharged by a 16x convolutional compressor.
This maintains high-resolution perception while slashing activation memory, transforming thousands of image patches into a lean 100-200 vision tokens.
Get ready for the multi-resolution "Gundam" mode—scaling from 512x512 to a monstrous 1280x1280 pixels!
It blends local tiles with a global view, tackling invoices, blueprints, and newspapers with zero retraining. It’s a shape-shifting computational marvel, mirroring the human eye’s dynamic focus with pixel-perfect precision!
The training data?
Supplied by the Chinese government for free and not available to any US company.
You understand now why I have said the US needs a Manhattan Project for AI training data? Do you hear me now? Oh still no? I’ll continue.
Over 30 million PDF pages across 100 languages, spiked with 10 million natural scene OCR samples, 10 million charts, 5 million chemical formulas, and 1 million geometry problems!.
This model doesn’t just read—it devours scientific diagrams and equations, turning raw data into a multidimensional knowledge.
Throughput? Prepare to be floored—over 200,000 pages per day on a single NVIDIA A100 GPU! This scalability is a game-changer, turning LLM data generation into a firehose of innovation, democratizing access to terabytes of insight for every AI pioneer out there.
This optical compression is the holy grail for LLM long-context woes. Imagine a million-token document shrunk into a 100,000-token visual map—DeepSeek-OCR reimagines context as a perceptual playground, paving the way for a GPT-5 that processes documents like a supercharged visual cortex!
The two-stage architecture is pure engineering poetry: DeepEncoder generates tokens, while a Mixture-of-Experts decoder spits out structured Markdown with multilingual flair. It’s a universal translator for the visual-textual multiverse, optimized for global domination!
Benchmarks? DeepSeek-OCR obliterates GOT-OCR2.0 and MinerU2.0, holding 60% accuracy at 20x compression! This opens a portal to applications once thought impossible—pushing the boundaries of computational physics into uncharted territory!
Live document analysis, streaming OCR for accessibility, and real-time translation with visual context are now economically viable, thanks to this compression breakthrough. It’s a real-time revolution, ready to transform our digital ecosystem!
This paper is a blueprint for the future—proving text can be visually compressed 10x for long-term memory and reasoning. It’s a clarion call for a new AI era where perception trumps text, and models like GPT-5 see documents in a single, glorious glance.
I am experimenting with this now on 1870-1970 offline data that I have digitalized.
But be ready for a revolution!
More soon.
[1] github.com/deepseek-ai/De…
English
𝕋𝕒𝕝𝕚𝕟𝕄𝕚𝕙𝕜𝕒𝕚𝕟 retweetledi

El framework que usamos en @RappiColombia para aprender y construir CUALQUIER COSA desde cero (actualizado y mejorado a la fecha)
El mismo que uso para que mi equipo desarrolle world-class capabilities
Aquí los 6 pasos clave 👇
Español

Don't be shy, just tag the company you wish to work for.
English
𝕋𝕒𝕝𝕚𝕟𝕄𝕚𝕙𝕜𝕒𝕚𝕟 retweetledi


𝕋𝕒𝕝𝕚𝕟𝕄𝕚𝕙𝕜𝕒𝕚𝕟 retweetledi

