Sabitlenmiş Tweet

現在のAIの中核であるTransformerを置きかえることを目指す論文の改訂版を出しました!
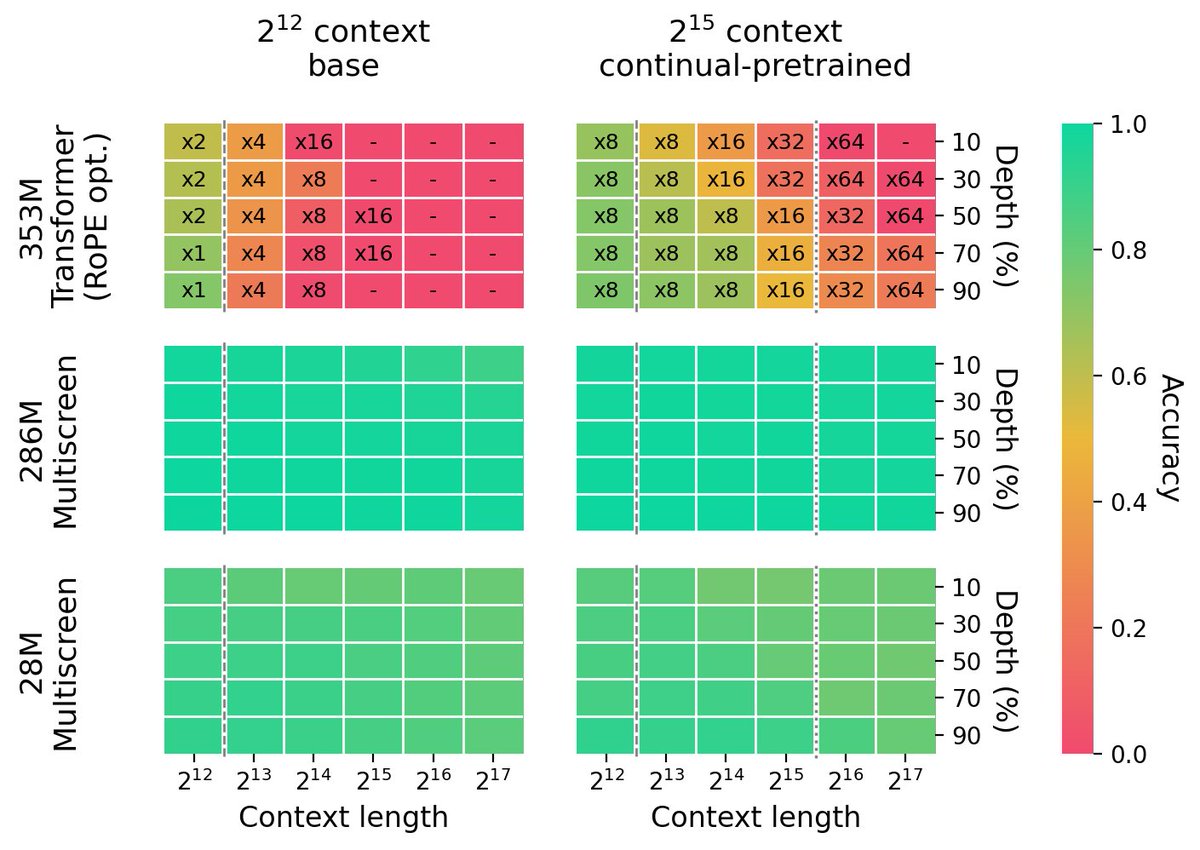
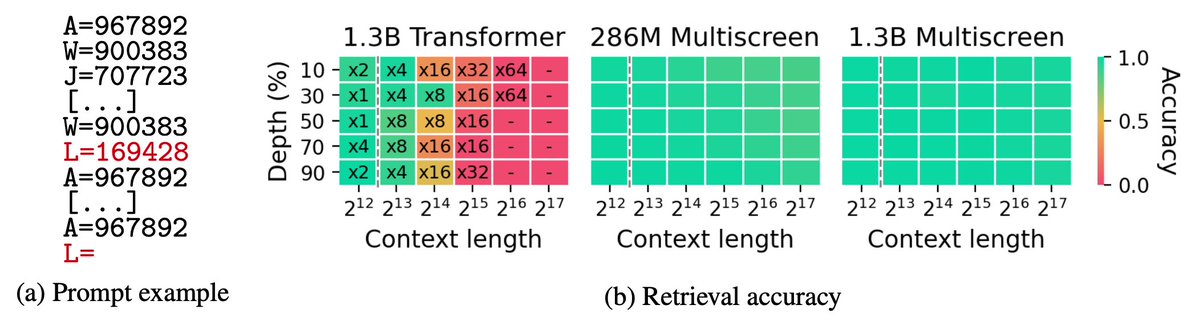
✅ 学習時より圧倒的に長い文でも性能維持&正確な情報取得
✅ 学習の安定性が桁違い(なんと学習率1でも学習可能!)
✅ モデルサイズ削減 & 推論速度向上
✅ 解釈性の大幅向上
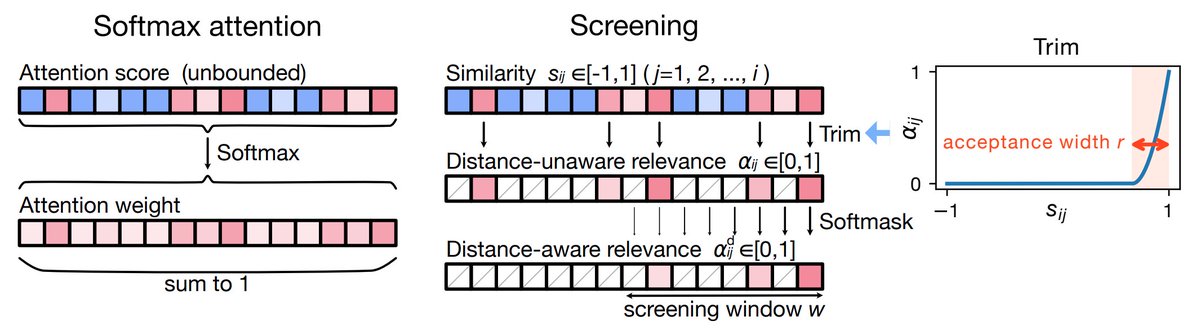
本文に図を追加してわかりやすくまとめ直しました!
読んでもらえると嬉しいです!!周りの人にもぜひ共有してください!!
論文 → arxiv.org/abs/2604.01178



日本語