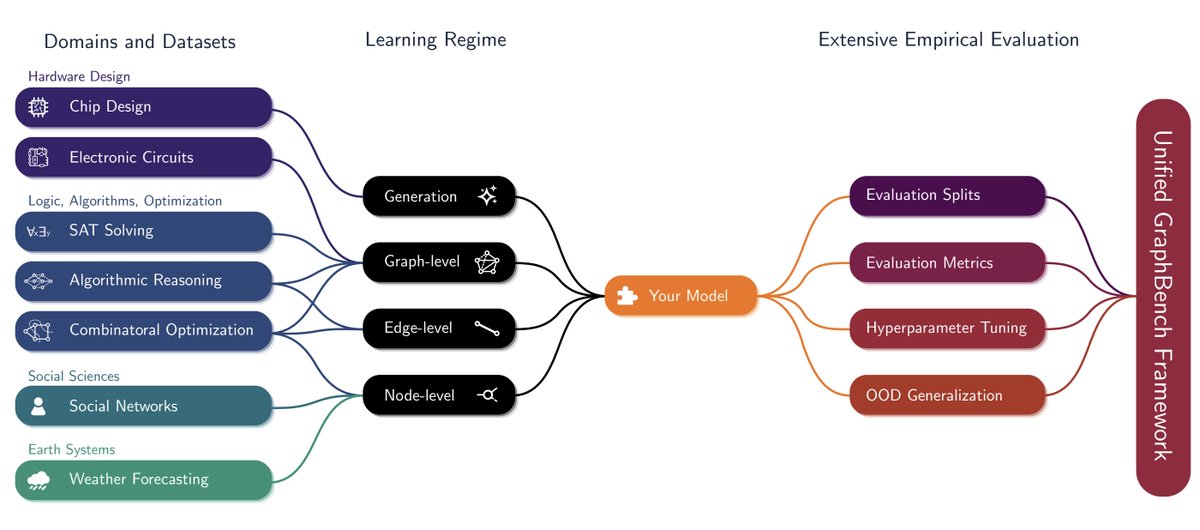
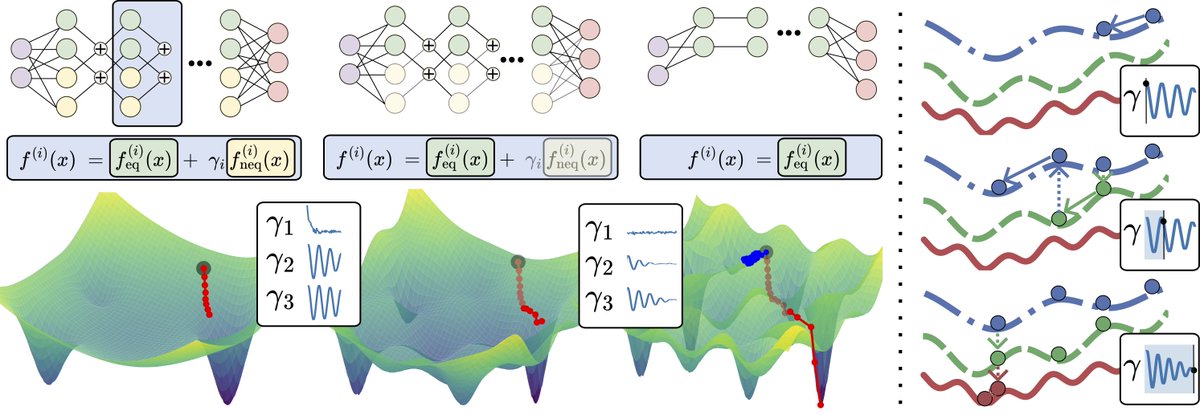
Mathias Niepert retweetledi

Check out neural-os.com it’s really cool.

Yuntian Deng@yuntiandeng
Glad to see followups to neural-os.com, but disappointed that neither the blog (with 34 refs) nor the code repo acknowledged NeuralOS, even tho the released data code appears to build directly on top of ours. That omission is hard to understand given our shared vision.
English