MoonMath.ai retweetledi

Our most popular section on the website is Challenges.
It's how we hire:
Solve a challenge → get a job offer 💪
A few examples below. More coming soon.
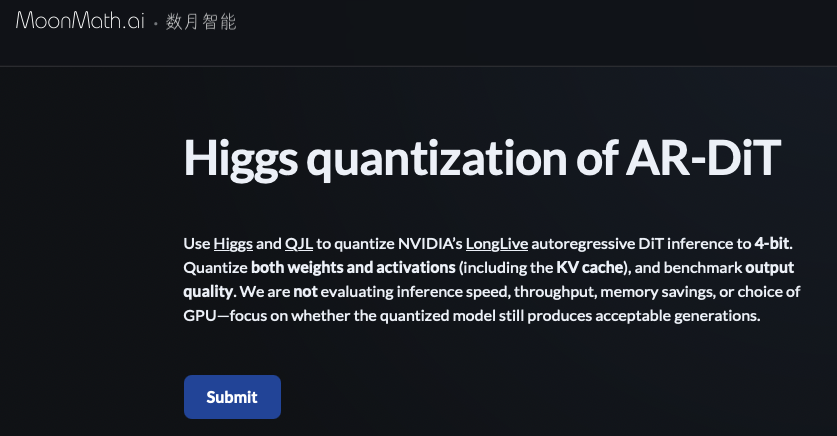
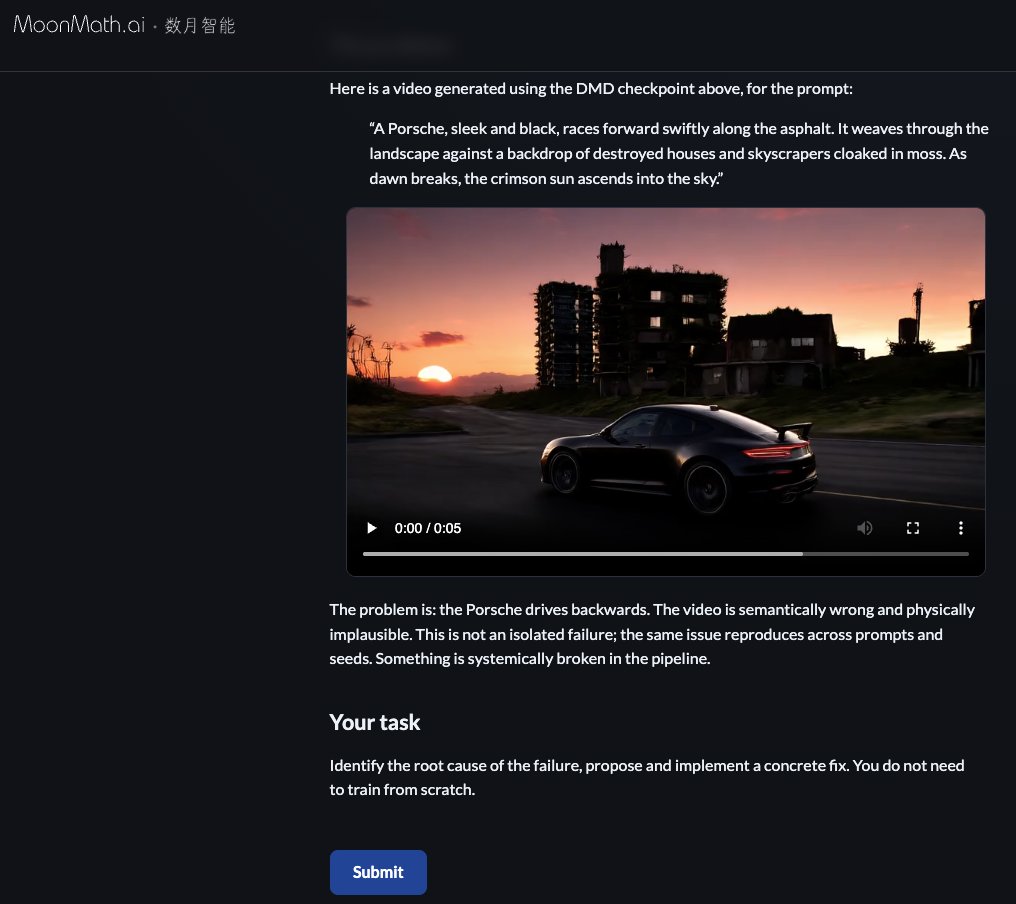
Claude won’t help..

English
MoonMath.ai
48 posts


@moonmathai
World models hardware acceleration, https://t.co/vS8lswRvhS

Video AI benchmarks are broken. VBench requires 6,230 videos per model eval. Scores cluster near the ceiling. Yes-bias makes every model look good. Rankings don't match what humans prefer. We built WorldJen to fix this. 🧵
Announcing World Model Accelerator, fal's new product: fal.ai/wma We've spent years building the inference layer for generative media. In 2023, we shipped 30 FPS, low-latency, action-controlled diffusion APIs, years before anyone else. Fast forward to today and we've been powering foundational model companies across image, video, real-time speech-to-speech and action-controlled world models. Now we're opening it up. World Model Accelerator is the system behind it all. Our in-house inference engine hits SOTA performance on Hopper and Blackwell for Diffusion Transformer workloads, both causal and bi-directional. Built on fal Serverless, it scales seamlessly from 1 GPU to 1,000+. This is the same platform that's been running real workloads, at scale, for years. A new WebRTC gateway optimizes latency between users and GPUs (routing requests to the closest region), built on the same infra that powers our real-time speech workloads. And direct access to the fal Marketplace puts your model in front of enterprises spending hundreds of millions on generative media, with a real co-selling motion behind it. This is the infrastructure layer for world models.

Cosmos-Predict2.5-2B Inference NVIDIA H200 vs AMD MI300X moonmath.ai/posts/cosmos-a…
High performance benchmarks for video & world models. worldjen.com *made with @storynote_ai

The community invested enormous efforts in optimizing attention, but the large `nn.Linear` layers that surround attention? Largely untouched! Introducing LiteLinear: a drop-in video DiT acceleration that compress nn.Linear layers via calibration-aware low-rank decomposition + quantization. Targets both FFN and attention projection linears (Q/K/V/O) without retraining We are releasing LiteLinear support for both @nvidia Hopper and @AMD Instinct, together with a proof of concept on @Lightricks LTX-2 FFN: 22.5% faster transformer compute 11.5% peak memory reduction 7.6% faster end-to-end inference Blog: moonmath.ai/posts/liteline… Code: github.com/moonmath-ai/Li…
The community invested enormous efforts in optimizing attention, but the large `nn.Linear` layers that surround attention? Largely untouched! Introducing LiteLinear: a drop-in video DiT acceleration that compress nn.Linear layers via calibration-aware low-rank decomposition + quantization. Targets both FFN and attention projection linears (Q/K/V/O) without retraining We are releasing LiteLinear support for both @nvidia Hopper and @AMD Instinct, together with a proof of concept on @Lightricks LTX-2 FFN: 22.5% faster transformer compute 11.5% peak memory reduction 7.6% faster end-to-end inference Blog: moonmath.ai/posts/liteline… Code: github.com/moonmath-ai/Li…


