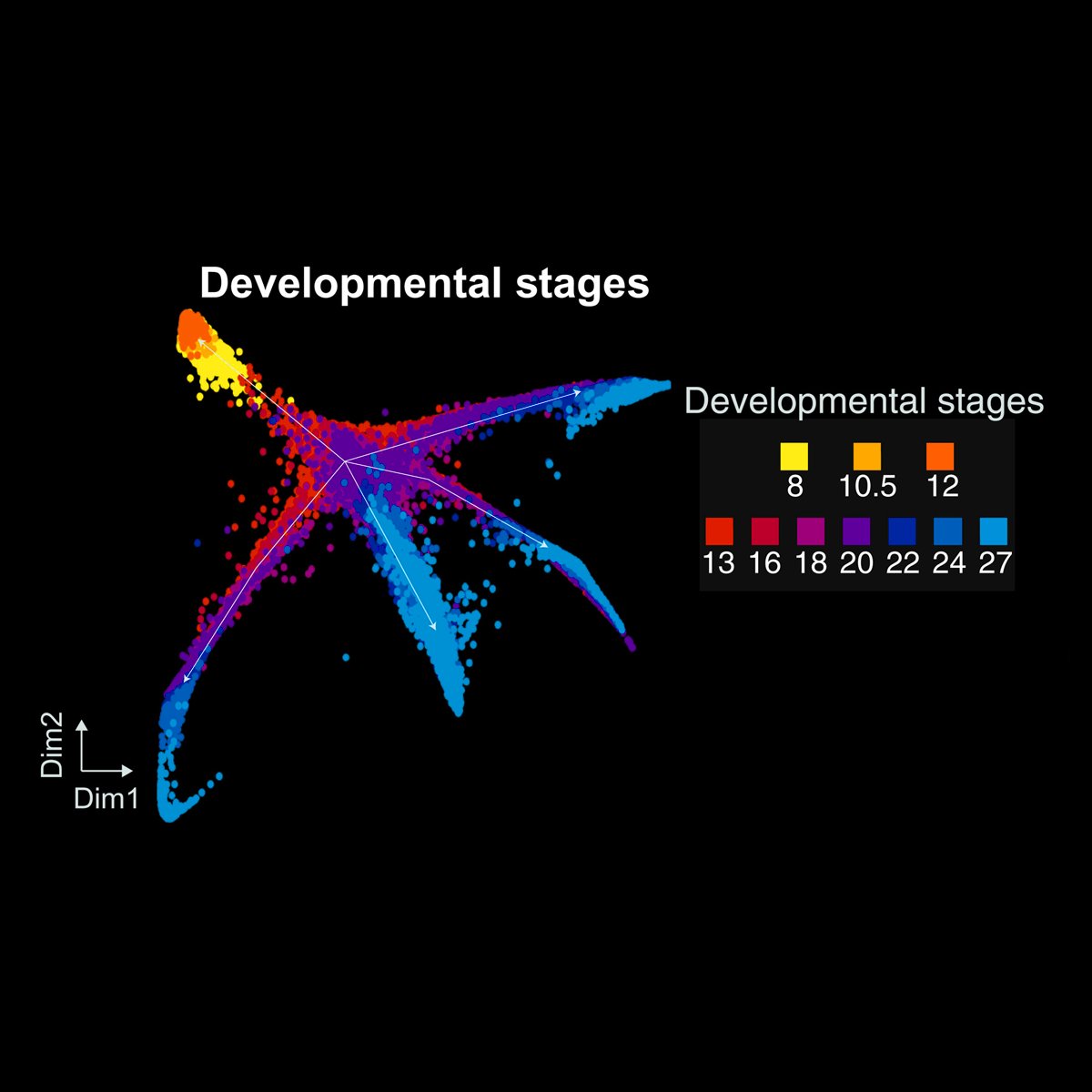
Martin Proks retweetledi

We are looking for: PhD Student (starting as Research Assistant) and Postdoctoral Researcher in Stem Cell Biology and Mechanobiology. Please RT💕
🔗 About our lab: renew.science/principal_inve…
🎓 PhD position: jobportal.ku.dk/phd/?show=1524…
🧪 Postdoc position: jobportal.ku.dk/videnskabelige…

English