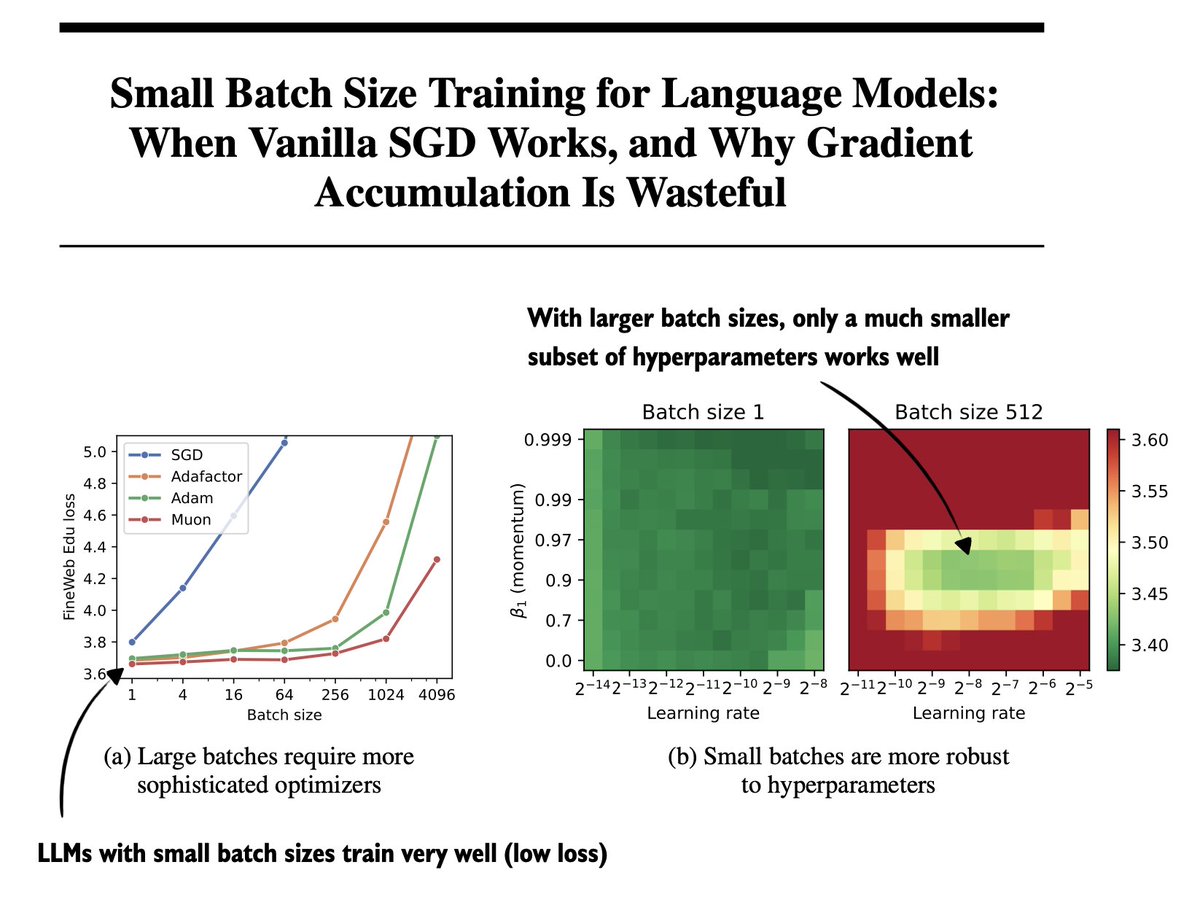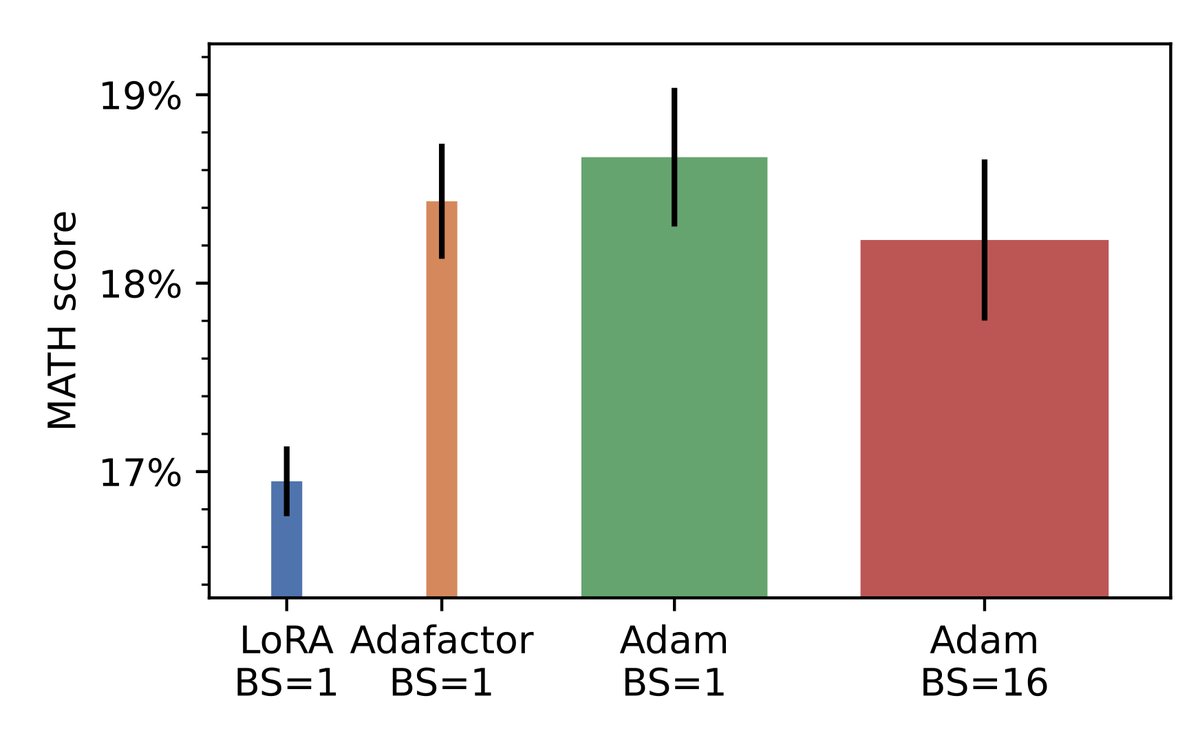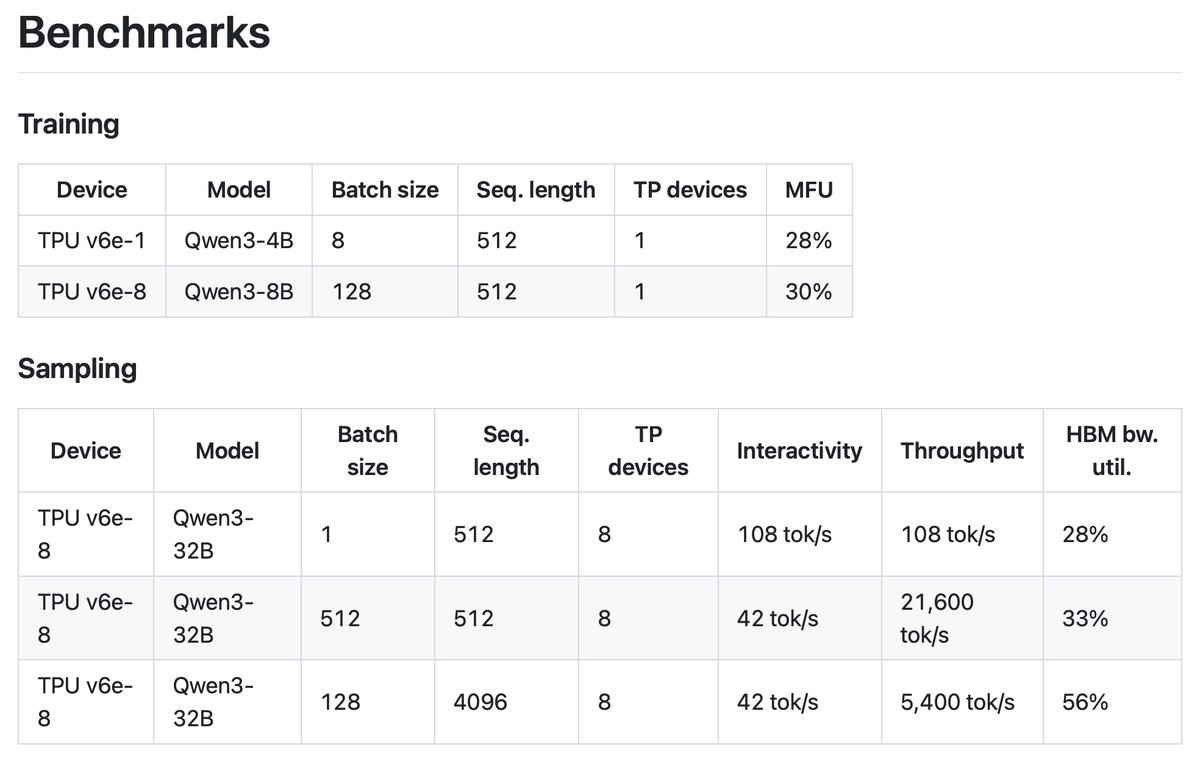

@karpathy Using SGD could save ~10LOC and really shouldn't even hurt performance! x.com/micahgoldblum/…
Micah Goldblum@micahgoldblum
🚨 Did you know that small-batch vanilla SGD without momentum (i.e. the first optimizer you learn about in intro ML) is virtually as fast as AdamW for LLM pretraining on a per-FLOP basis? 📜 1/n
English