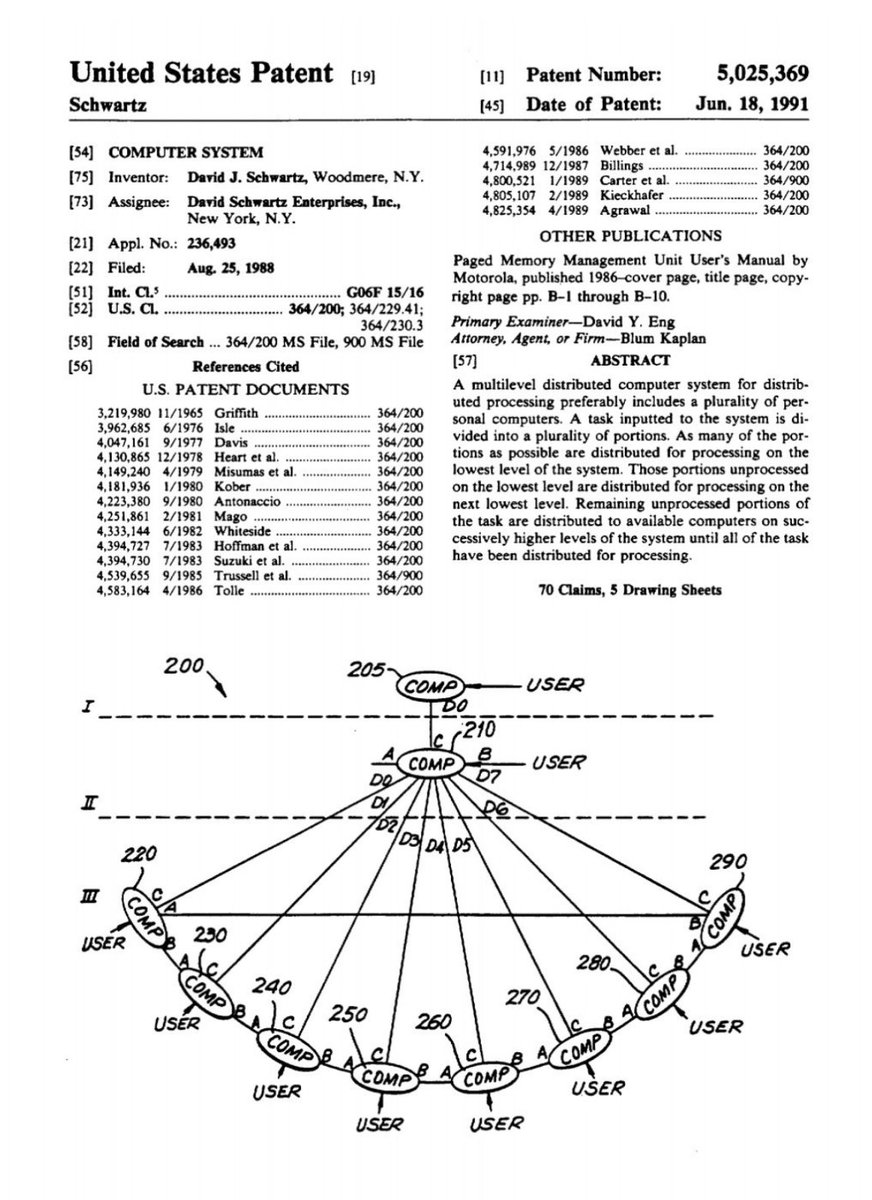
Telusuko retweetledi

☁️ Day 2/50 — #50DaysOfAzure
Every Azure VM, database, and app sits inside ONE thing -> a Virtual Network.
No VNet = no connectivity. No security. No Azure.
Here's the service you MUST understand first 🧵👇
#50DaysOfAzure #Azure

Dashrath Mundkar@dashmundkar
🚀 I'm starting #50DaysOfAzure! For the next 50 days, I'll break down ONE Azure service daily: ☁️ What it does 🔧 Real-world use cases 💡 Key features 📊 Pricing insights 🏗️ Architecture tips From VMs to Quantum Computing — we're covering it ALL. Follow along & RT to help others learn! 🧵👇 #Azure #Cloud
English