Meng Zhang retweetledi
Meng Zhang
336 posts


Meng Zhang
@mzh1024
Building @Tabby_ML
San Francisco, CA Katılım Aralık 2017
81 Takip Edilen359 Takipçiler

Some bugs don’t show up in logs at all. We’ve been using @getpochi’s browser subagent to debug those.
We ran into a case where the UI rendered correctly, but nothing responded to interaction. Inputs wouldn’t focus, buttons didn’t register clicks, but there were no console errors, and backend logs were completely clean.
At that point, logs weren’t useful. So we updated our investigation Skill to enforce a rule: if logs don’t explain the issue, the agent must verify behavior in a running system before forming a conclusion.
With that in place, Pochi switched to the browser subagent and inspected the page directly.
Instead of reasoning from code, it checked what actually receives input using `document.elementFromPoint`.
The result wasn’t the input field or button. It was:
A container element sitting above the interactive layer, intercepting all clicks and keystrokes.
Tracing it further showed a ::before pseudo-element covering the viewport. It had no visible styles, but it still participated in hit-testing.
The root cause was will-change: transform on the parent, which created a new stacking context. The z-index values looked correct in code, but they were never actually competing at the page level.
The fix was:
```
.app-main.layout-stable::before {
pointer-events: none;
}
```
This class of issue is difficult to catch through logs or static inspection. The system is technically correct, but the behavior is wrong.
The only reliable signal is what actually happens at runtime, which is where Pochi's browser subagent ends up being useful.
English
Use your coding agent as a support engineer.
The setup is fairly straightforward. In our case, @getpochi is given access to runtime data via MCP (we used Logfire here, but the same pattern applies to Datadog / Elasticsearch).
To cement this, I defined a Skill that forces it to start from logs and explain behavior based on evidence (instead of jumping to code). One of the issues I tested was image generation returning null with no errors.
Pochi queried recent requests through Logfire. The signal was in the response payload:
```
{
"credits_balance": "50",
"credits_used": "0"
}
```
The frontend expected credits_remaining. The subtraction produced NaN, which blocked generation.
Nothing failed. The system behaved exactly as written.
The only way to arrive at this was by querying logs, inspecting payloads, and tracing how the data was used downstream - which Pochi could do directly because it had access to runtime data via MCP and was guided by the investigation Skill.
This kind of issue doesn’t show up as an error and is hard to spot from code alone. It only becomes obvious when you can reconstruct behavior from actual system data.
Here's the task link: app.getpochi.com/share/p-086629…
English
A migration prompt works once. But how do you enforce it across every repository in a team?
We turned a one-shot migration prompt into a reusable Pochi Skill and enforced it through CI + lint checks.
Check out the full tutorial 👇
docs.getpochi.com/tutorials/mana…
English
Checkout the full repo in case you want to use it in your workflow 👉 github.com/mufassirkazi/d…
English
.@getpochi has been a 100× productivity boost for our marketing workflow. Here’s one example.
Every time we finished writing a tutorial in @Larksuite, @NotionHQ, or @googledocs, publishing it to our Next.js docs site still took another 30–45 minutes (converting to Markdown, uploading assets to S3, and preparing a PR).
Now it takes about ~10 seconds.
`docflow fetch `
This command pulls the document, converts it to Markdown/MDX, extracts images and media, uploads them to S3 with content hashing, rewrites the URLs, and drops the final file directly into the docs directory ready to commit.
The entire tool was built using @getpochi. Would love for you to give it a spin (repo link in comments)
English
Adding an icon to the VS Code activity bar sounds simple until you learn it’s rendered as a masked SVG.
It doesn’t get displayed with its original colors. Instead, it’s treated as a binary shape (opaque vs transparent), and the theme controls the fill. So an icon that looks correct in dark mode can break in light mode.
We ran into this while adding the new Pochi sidebar icon. In dark mode, the face needed to be opaque. In light mode, it effectively needed to be inverted so the outline renders correctly against a light background. One SVG couldn’t handle both cleanly.
We weren’t sure what the right approach was. @getpochi solved it by registering two separate activity bar containers and conditionally rendering them using a when clause tied to isDarkTheme. So there are actually two icons defined, but only one is visible at a time, and it switches reactively when the theme changes.
It also introduced the necessary theme context management and updated our test utilities to support the new sidebar view types.
What I liked here is that Pochi reasoned about how VS Code actually renders activity bar items instead of trying to force a workaround into a single SVG.
Here's the full commit: github.com/TabbyML/pochi/…
English
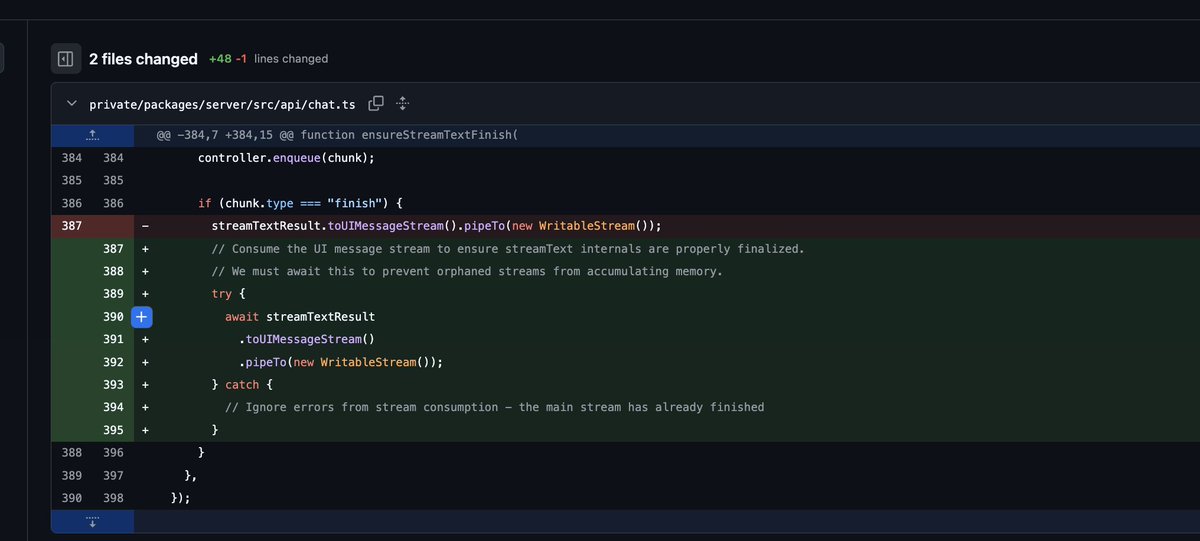
Our Node service kept getting killed at 16GB RSS.
V8 insisted memory usage was only ~2GB.
Heap and Large Object Space looked stable. Nothing in the usual dashboards suggested a leak, but RSS kept climbing until the container died.
That mismatch is a nasty class of bug. Everything you normally trust is telling you you’re fine.
We gave the full repo to @getpochi and asked it to identify where memory was growing outside V8.
It traced through our streaming code and found a `pipeTo()` that wasn’t awaited. Each completed request left behind a running stream with no cancellation or backpressure. The memory was accumulating in native buffers and libuv internals, so it never showed up in heap stats.
The fix was literally adding `await`. Pochi even went a step ahead and explained the difference between heap, external memory, and RSS, and followed the code path that made the graphs disagree.
That’s the kind of problem I want an AI coding agent to help with - not another CRUD endpoint, but reasoning about why a live production system is behaving in a way that doesn’t make sense.
English
If anyone's looking to checkout the full repo 👉github.com/mufassirkazi/g…
English
Fun project: we put together a GitHub visualizer that turns a repo’s day into a little animated office. 📁🪴
Built completely with @getpochi.
If you’re curious what your repo looks like, reply with a link + date and I’ll generate one.👇
English
We wrote a blog on reducing token usage with Pochi.
Most token blowups aren’t caused by bad prompts or the wrong model.
Usually it’s context that keeps growing, or multiple approaches living in the same thread.
We break down 5 practical fixes.
docs.getpochi.com/developer-upda…
English
Published a tutorial on safe database access for coding agents.
TL;DR:
- read-only isn’t safe if execution surfaces still exist.
- Writable clones + migration scripts work better than prod write access.
Full walkthrough → docs.getpochi.com/tutorials/secu…
English
I’m increasingly uncomfortable with how casually we’re treating software as disposable.
AI made it cheap to try things, so speed started standing in for productivity. The harder signals (clarity, maintainability) get deferred because they’re inconvenient and invisible.
Iteration is good. Throwaway experiments are good. I do that too.
What’s not disposable is anything someone else starts relying on. APIs, UI behaviors, data formats, even weird undocumented quirks. Once they’re depended on, they harden whether you planned for it or not.
And though AI lowers the cost of change, it won't lower the cost of mistakes.
That gap is where most future regret will come from.
English
I’m increasingly convinced CLIs are a better interface for AI than MCPs.
MCPs feel elegant, but they clog the context window and introduce a lot of invisible complexity. Lazy-loading servers will help, but the shape is still heavy.
CLIs are blunt. They compress intent into commands, they’re easy for humans to reason about, and models already know how to use them well.
English
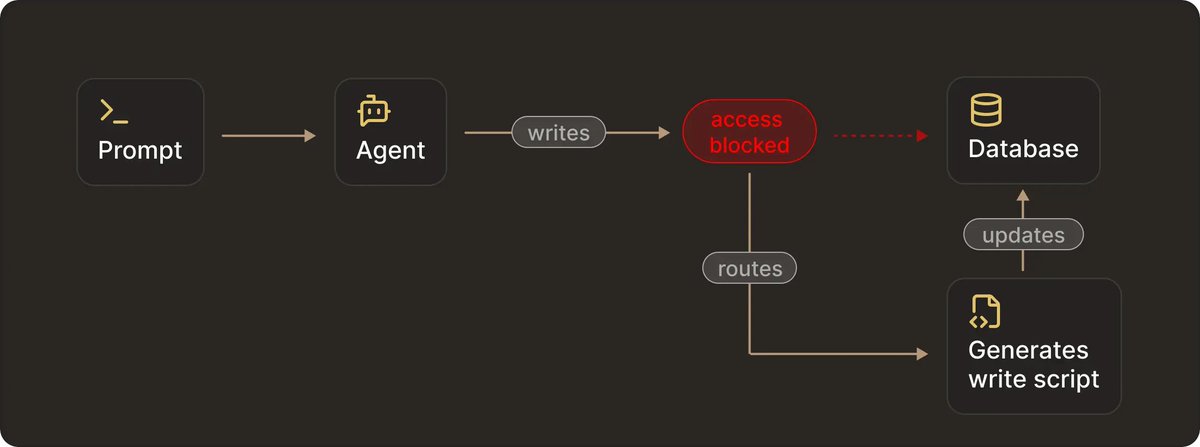
We’re all skeptical about giving agents access to databases and SSH.
But adding more prompts, allowlists, and approval dialogs is not the best way to go forward with it.
Of course, you can restrict what an agent is allowed to do, but still have a system that can overcome those restrictions.
Prompts and rules are control surfaces. Shells, credentials, runtimes, and database roles are execution surfaces.
If an execution surface exists, an agent will eventually route through it. We’ve seen agents route around `readonly` DB tools, generate their own scripts, and use unintended runtimes to modify production state - simply because that’s the fastest path to completing the task.
The only setups that hold up in production enforce safety outside the model.
I wrote a deep dive on this and what actually works when giving agents access to SSH and databases. 👇
docs.getpochi.com/developer-upda…
English