@coreyganim Just curious enough to know two things
- how do you handle paperclip token usage
- how did u integrate gstack skills here when they are mostly Q&A driven
Did you finetuned stuff??
What I love about this article is that it shows you what to actually DO with Paperclip.
The stack:
→ Paperclip = your AI company (assigns work, tracks progress)
→ gstack = your engineering team (15 specialist skills from Garry Tan)
→ autoresearch = your R&D lab (100 experiments while you sleep, from Karpathy)
The 10-minute setup:
STEP 1: npx paperclipai onboard --yes
Open dashboard → Create company → Hire your CEO agent
STEP 2: Clone gstack to ~/.claude/skills/gstack
Now your agents can: /office-hours (plan) → /review (check code) → /qa (test in real browser) → /ship (deploy)
STEP 3: Build autoresearch as a skill
Give it a research question → Sleep → Wake up to 100 completed experiments
The killer move: Run 10-15 gstack commands simultaneously. One agent plans, another tests, another ships. All at once.
Three free tools. Zero employees. One AI company.
Claude Code 2.1.78 has been released.
26 CLI changes, 3 system prompt changes
Highlights:
• Response text streams line-by-line as it's generated, providing immediate partial output for faster feedback
• Third-party uploads show a clear public-exposure warning to reduce accidental sharing of sensitive data
• StopFailure hook fires when a turn ends from API errors (rate limit/auth), enabling explicit error handling
Complete details in thread ↓
We're shipping a new feature in Claude Cowork as a research preview that I'm excited about: Dispatch!
One persistent conversation with Claude that runs on your computer. Message it from your phone. Come back to finished work.
To try it out, download Claude Desktop, then pair your phone.
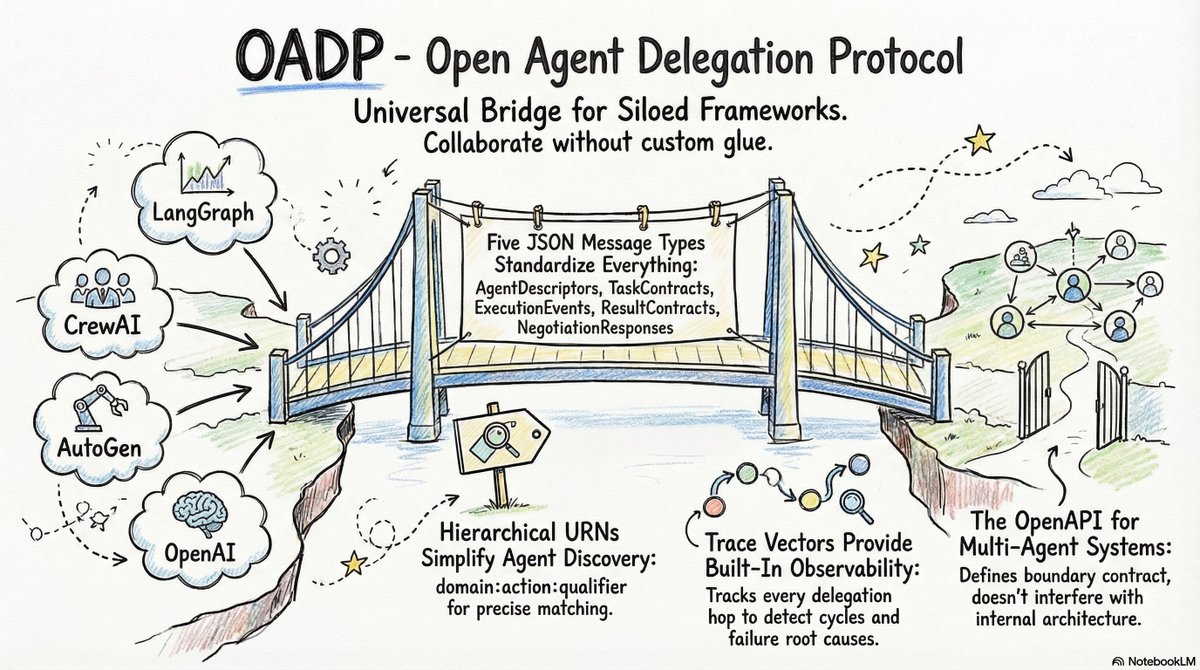
Over the past couple of months experimenting with multi-agent AI, one problem kept appearing: agent handoffs across frameworks. So we built OADP — Open Agent Delegation Protocol, a minimal standard for agent-to-agent delegation. #AI#Protocol#Agents
🔗 github.com/Open-Agent-Del…
Three days ago I left autoresearch tuning nanochat for ~2 days on depth=12 model. It found ~20 changes that improved the validation loss. I tested these changes yesterday and all of them were additive and transferred to larger (depth=24) models. Stacking up all of these changes, today I measured that the leaderboard's "Time to GPT-2" drops from 2.02 hours to 1.80 hours (~11% improvement), this will be the new leaderboard entry. So yes, these are real improvements and they make an actual difference. I am mildly surprised that my very first naive attempt already worked this well on top of what I thought was already a fairly manually well-tuned project.
This is a first for me because I am very used to doing the iterative optimization of neural network training manually. You come up with ideas, you implement them, you check if they work (better validation loss), you come up with new ideas based on that, you read some papers for inspiration, etc etc. This is the bread and butter of what I do daily for 2 decades. Seeing the agent do this entire workflow end-to-end and all by itself as it worked through approx. 700 changes autonomously is wild. It really looked at the sequence of results of experiments and used that to plan the next ones. It's not novel, ground-breaking "research" (yet), but all the adjustments are "real", I didn't find them manually previously, and they stack up and actually improved nanochat. Among the bigger things e.g.:
- It noticed an oversight that my parameterless QKnorm didn't have a scaler multiplier attached, so my attention was too diffuse. The agent found multipliers to sharpen it, pointing to future work.
- It found that the Value Embeddings really like regularization and I wasn't applying any (oops).
- It found that my banded attention was too conservative (i forgot to tune it).
- It found that AdamW betas were all messed up.
- It tuned the weight decay schedule.
- It tuned the network initialization.
This is on top of all the tuning I've already done over a good amount of time. The exact commit is here, from this "round 1" of autoresearch. I am going to kick off "round 2", and in parallel I am looking at how multiple agents can collaborate to unlock parallelism.
github.com/karpathy/nanoc…
All LLM frontier labs will do this. It's the final boss battle. It's a lot more complex at scale of course - you don't just have a single train. py file to tune. But doing it is "just engineering" and it's going to work. You spin up a swarm of agents, you have them collaborate to tune smaller models, you promote the most promising ideas to increasingly larger scales, and humans (optionally) contribute on the edges.
And more generally, *any* metric you care about that is reasonably efficient to evaluate (or that has more efficient proxy metrics such as training a smaller network) can be autoresearched by an agent swarm. It's worth thinking about whether your problem falls into this bucket too.
I packaged up the "autoresearch" project into a new self-contained minimal repo if people would like to play over the weekend. It's basically nanochat LLM training core stripped down to a single-GPU, one file version of ~630 lines of code, then:
- the human iterates on the prompt (.md)
- the AI agent iterates on the training code (.py)
The goal is to engineer your agents to make the fastest research progress indefinitely and without any of your own involvement. In the image, every dot is a complete LLM training run that lasts exactly 5 minutes. The agent works in an autonomous loop on a git feature branch and accumulates git commits to the training script as it finds better settings (of lower validation loss by the end) of the neural network architecture, the optimizer, all the hyperparameters, etc. You can imagine comparing the research progress of different prompts, different agents, etc.
github.com/karpathy/autor…
Part code, part sci-fi, and a pinch of psychosis :)
I always wondered which Ollama model my machine could run properly.
Now you can easily do that using llms-checker
It's a CLI tool that checks your system specs and recommends the best models to run on Ollama based on what your machine
npm install -g llm-checker
github.com/Pavelevich/llm…
I owe a Public Apology to @OlaElectric and @bhash. 🙏
I previously analyzed your numbers and said the situation looked bad. I was wrong.
I’m sorry, but the numbers are actually much, much worse.
Here is the Q3 reality check that no one is talking about. 🧵👇
Layer 6: AI Systems
A model alone isn’t a product.
Real AI systems add:
• RAG
• Vector DB
• Batching
• Quantization
• Caching
Most hallucination issues are system problems.
Infrastructure defines scalability.
#RAG#MLOps#AIArchitecture
[DemystifyingAI using AI] - AI isn’t magic. It’s a 7-layer stack.
From silicon to chatbot, every AI product runs on the same hidden architecture.
Understand the layers → stop chasing hype → start making better decisions.
Thread 👇
#AI#DeepLearning#LLM