
Nuno Campos
1.7K posts
Nuno Campos
@nfcampos
@witanlabs “that most limited of all specialists, the well-rounded man” https://t.co/sWDUx7YcQa
London Katılım Aralık 2008
1.5K Takip Edilen3K Takipçiler
On the other hand, on a coding task I tried it produced better results than opus on the same earlier today
English
GPT 5.4 Thinking in ChatGPT seems like a step backwards in search, the query “What are the best tea rooms or coffee shops serving loose leaf tea in London, around Clerkenwell, Holborn, Marylebone where I can sit in for 60mins” produces a shortlist of 6 options, where options 1 and 2 have been closed for several years, and option 4 is a blog (lol)
chatgpt.com/s/t_69a9e734ff…
English
@zebriez Not sure if it counts as a primer on a single topic, but designing data intensive applications has to be up there
English

what is the best technical primer on a topic you've ever read?
English
@juanstoppa Thanks! Both GPT 5.1 and 5.2 and Opus and Haiku 4.5 and 4.6
English

@nfcampos great article Nuno! what model were you using for the research ? (sorry if I missed it in the github repo)
English
I wanted to share what we learned over the past few months, building agents 🧵
English
@FundamentEdge Good questions, but benchmarks are meaningless without context, on an earlier version of our benchmark we hit 90+% accuracy. While that looks nice, it’s useless for continuing to make progress, so we added more complicated tasks.
English

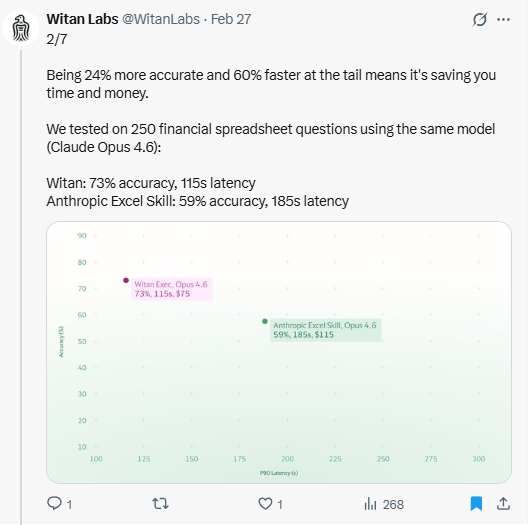
This is one of the biggest sticking points on AI Excel that I'm trying to understand.
73% accuracy is progress, but is it useful for anything at all?
We were on a vendor call last month and the vendor bragged of hitting 65% accuracy in Excel and Andrew Carr and I texted "an analyst who is 65% accurate in Excel is 100% fired".
Why is AI Excel only 60-70% accurate? Are these issues fundamental or solvable?
> Is MCP fundamentally too brittle to get to 99% accuracy?
> Is the data layer clean enough to hit 99% accuracy (i.e. there's a reason why hedge fund analysts don't start their models with a Bloomberg download)
> Are the foundation models powerful enough to handle the multi-modal (filings, PRs, investor decks, data supplementals), multi-document, "needle in a haystack" issues for LLMs? Context windows have grown, but they are still not large enough to capture all of the documents and files for one ticker (letalone a coverage universe)
> Is the commercial opportunity large enough for foundation labs to build RL environments for public equity modeling, as they are doing on investment banking modeling?
Does the "march of 9s" on AI Excel take 6 months or 6 years? Driverless cars took 13 years from DARPA Urban challenge to first Waymo.
These are legit questions. I don't know.
I also don't really trust public evaluation sets (i.e. LLM's win physics competitions...then you learn the LLM trained on the physics competition test bank lol). The real questions in investment research modeling are out of sample questions (i.e. how to model SAAS retention in a Claude-world...there is no prior on which to rely).
So I am building my own evaluation set. 100 use cases ranging from simple (input 3 statements from 10-K to AMZN model) to complex (model GE split/spin).
Am I wasting my time? 36 months form now, are we still only at 80% accuracy in AI Excel?
These are questions, now answers - love your takes in replies or DM!
Patrick OShaughnessy@patrick_oshag
For all the spreadsheet people out there …
English
Nuno Campos retweetledi

to make coding agents good at other tasks, you need good tools for those tasks
these are some good tools for working with spreadsheets!
Nuno Campos@nfcampos
Code mode for spreadsheets, compatible with every coding agent (and OpenClaw!). Try it out and let me know what you think!
English
I'll be posting new features and updates over next few weeks, you can always check the changelog to see it ahead of time... github.com/witanlabs/wita…
English
Code mode for spreadsheets, compatible with every coding agent (and OpenClaw!). Try it out and let me know what you think!
Witan Labs@WitanLabs
Coding agents are surprisingly bad at spreadsheets. They'll cobble together a Python script that silently breaks formulas, misreads cached values, or corrupts formatting. The problem isn't the model, it's the tools. We built Witan to fix this. witanlabs.com/agents
English
English

we are finalizing @aidotengineer Europe speaker acceptances and realizing that we actually dont have enough good speakers for these tracks:
- mechanistic interpretability
- generative media (video/image but could also use more voice/music)
- Claw track (openclaw etc power users)
if you have GOOD work - not an ad for your barely launched startup, actual good work - in these areas please please reply or DM and I’ll skip you to the front of the line. We pay all travel and accommodation for our international speakers, and our talks regularly get hundreds of thousands of views.
ai.engineer/europe
English
@nicbstme github.com/witanlabs/rese… no need to reverse engineer ours! Great piece btw
English

@0xarch1tect Thanks! Planning is just a prompt (skill to be precise) right now
English

this thread is packed. a few things stood out.
the "define the end state before you touch a cell" finding is the one id push on most. its basically forcing the agent to front-load its inference before it starts taking irreversible actions. the errors dont disappear, they just surface during planning where they cost nothing. ive seen similar patterns building agentic workflows, the ones that blow up mid execution almost always skipped a planning gate.
the domain knowledge > tools point is underrated. most teams obsess over the tool layer and treat domain knowledge as an afterthought. but youre describing four tool backends coming and going while the financial expertise kept compounding. the tools are the interface, the knowledge is the actual product. thats a real reframe for anyone building vertical agents right now.
the eval section deserves more attention in this thread. "llm as judge" failing on anything with a correct answer isnt surprising but its still something teams learn the hard way. programmatic comparison is slower to set up but youre flying blind without it. the 50 to 73 to 92 trajectory only becomes legible when you have something deterministic to measure against.
the part i found most interesting was the failed test shaping the product direction. youre not just saying "run benchmarks", youre saying a benchmark that contradicted your thesis told you what to build next. thats a different relationship with evaluation than most teams have.
whats your current thinking on how to structure the planning gate before execution kicks off? curious if thats a prompt pattern, a separate model call, or something else entirely.
English
Read the full story (and lots of technical details!) in the repo github.com/witanlabs/rese…
English
The test that contradicted our thesis was the one that shaped the product. We expected the Witan CLI verify workflow to beat openpyxl on QnA tasks. It lost, 70% to 85% — not because of capability, but because spawning a separate process per CLI command was the wrong interaction pattern for exploration tasks that need 20+ queries. That failure told us the REPL should be the external product (witan xlsx exec), and the remaining CLI commands (render, calc, lint) should be a lightweight verification add-on for agents that already have their own spreadsheet tools. We wouldn't have found either insight if the test had confirmed what we expected.
English