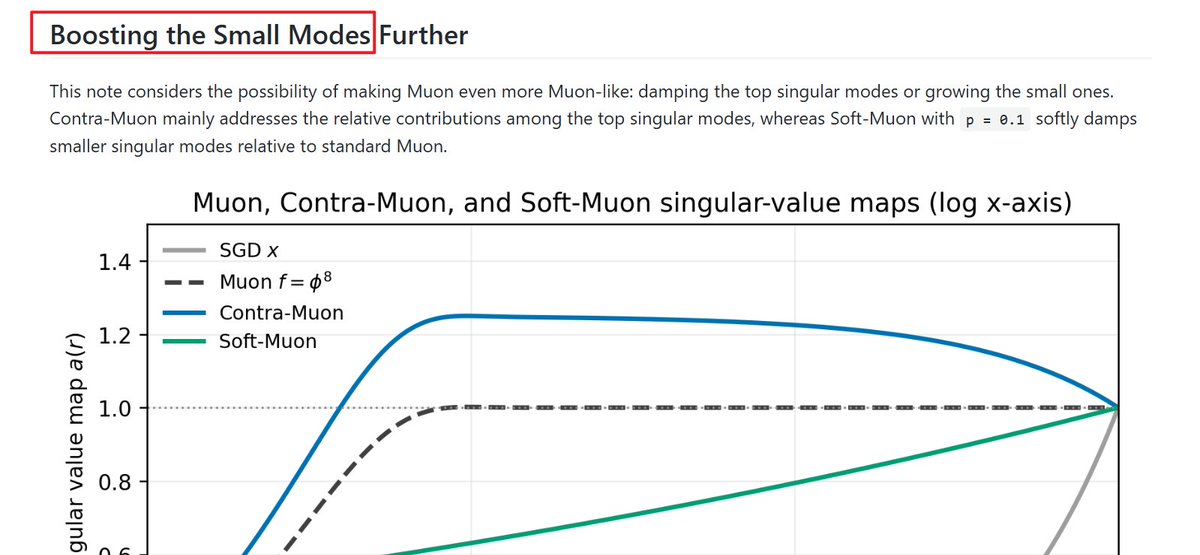
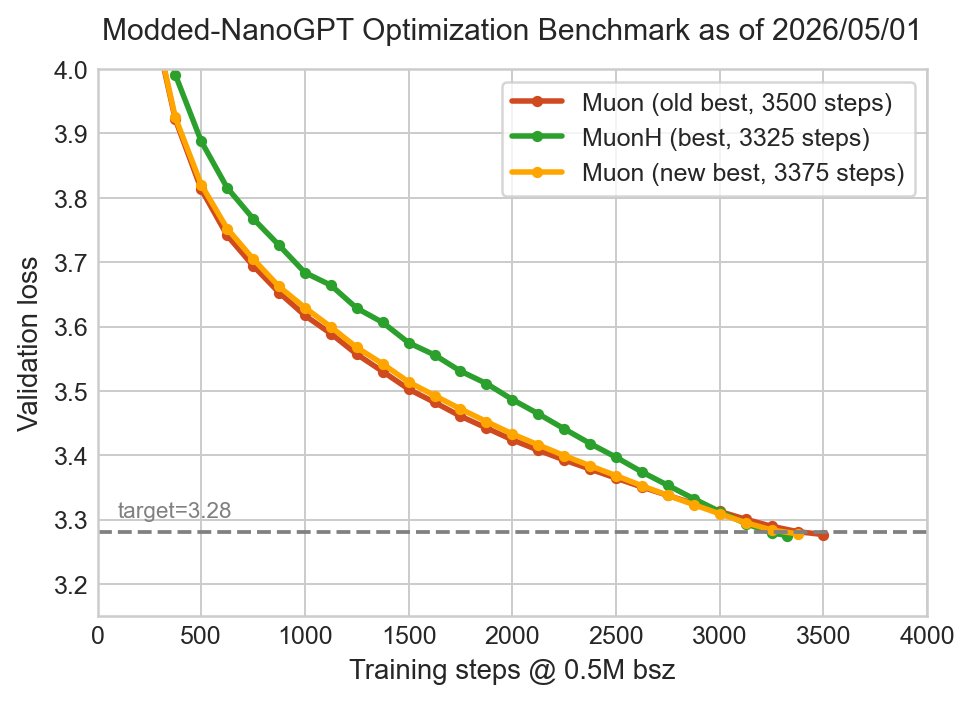
@PrimeIntellect let 2 AGIs run 10,000 experiments and it kept 2/3 of my innovations. A bit relieved actually
Prime Intellect@PrimeIntellect
Automating AI research is the next major step in AI We let Claude Code (Opus 4.7) and Codex (GPT 5.5) run autonomously on the nanoGPT speedrun optimizer track using our idle compute. ~10k runs, ~14k H200 hours Opus now holds the record at 2930 steps vs the 2990 human baseline
English