
Mariano
5 posts

Mariano
@notdotme
👨💻 Dev web · Angular | Java | PostgreSQL · 🧠 DAW + DevOps
Katılım Temmuz 2025
72 Takip Edilen1 Takipçiler

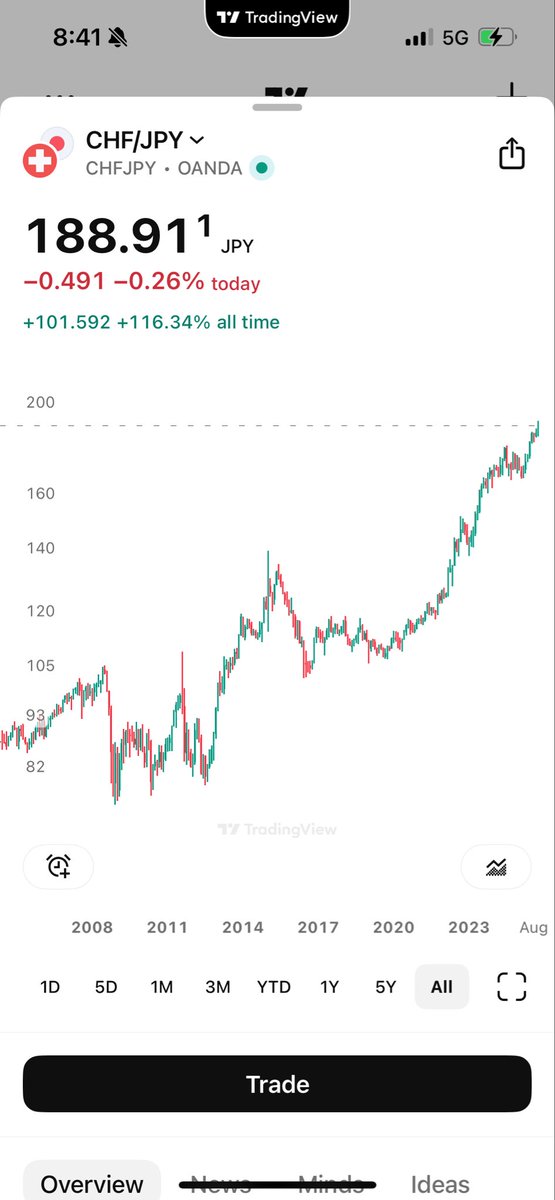
Swiss rates are negative and their currency continues to rise to all-time highs against the dollar and euro, so they will have no choice but to go negative. The only question is whether they do it before or after the next ECB cut which is being signal by the lower rates in Germany and the UK.


English


The bond market has completely rejected the Fed’s rate cut.
Yields have ripped higher following an initial drop on the rate cut announcement.
The rate cuts had the exact opposite effect of what the Fed wanted.
Mortgage rates will now spike.

English
Mariano retweetledi

silencio. el pitoniso va a hablar:
En la curva de Everett Rogers, los LLMs (y la IA en general) entraron en la fase "early adopters" hace 2 o 3 años. El dinero VC empezó a fluir y parecía no tener limite. El salto de gepeto2 a gepeto3 y de gepeto3 a gepeto4 fueron saltos bastante grandes.
Todas las empresas (y AI-bros) apostaban porque esos saltos evolutivos iban a seguir dándose y por eso no escatimaban en gastos, llegando a gastar decenas de mil-millones (OpenAI de momento se ha fundido unos ~$60MM). Es decir, la "carrera" consistía en ignorar el sangrado masivo de gasto porque el objetivo era llegar a la "AGI", "inteligencia humana" o cualquier otra cosa que cada uno entendiese como meta / objetivo final.
La premisa era que, una vez llegados a ese objetivo, todos los gastos se iban a recuperar... Obviamente, si "tuviéramos" ("nosotros", las empresas detrás de los modelos) una AGI que fuese capaz de inventar todo, podríamos crear productos nuevos (medicamentos, tecnología radicalmente nueva, etc...) que podríamos vender y recuperar toda la inversión / gastos.
A medida que los LLMs han ido entrando en la fase de "early majority", hemos empezado a comprender que a la AGI no íbamos a llegar (porque los modelos tienen un limite inherente en su funcionamiento; da igual como de grande sea el training set o cuantas GPUs usemos para entrenarlos, simplemente no *entienden*, solo repiten como loros). Así que la carrera se está modificando de "a ver quien llega primero a la AGI" a "a ver quien deja de desangrarse y puede continuar investigando".
Alguno limitan el número de tokens, otros limitan el número de "mensajes". Lo mismo da. La estrategia de verter dinero VC sin fin no es viable y está empezando a notarse.
En el futuro cercano, cuando entremos en el "late majority", va a ser muy interesante ver como seguirá cambiando la estrategia de las empresas, ya que éstas van a empezar a tener el siguiente problema:
Los modelos cada vez se optimizan mejor (ej LLaMa 2 usa 13B parámetros para llegar mas o menos al mismo nivel que LLaMa 1 65B), lo cual significa que se necesita cada vez menos hardware para obtener el mismo nivel.
Por otro lado, el hardware sigue mejorando y abaratándose (hoy en día una tarjeta gráfica con 4gb de RAM se considera low end y cuesta ~300€; hace 5-7 años algo parecido era mid-high end y costaba el doble).
Dentro de pocos años será posible ejecutar un modelo mas que decente en un hardware "de andar por casa".
Las empresas tendrán que encontrar alguna manera (funcionalidad, ventaja, X) de atraer a los usuarios (de pago). Si no la pueden encontrar, la gente simplemente no comprará su servicio y ejecutará los modelos en sus propios dispositivos (puede que incluso inconscientemente; Apple está dando los primeros pasos en esa dirección; mientras "los demás" están integrándose con APIs de terceros, Apple está metiendo sus propios modelos en sus dispositivos y la gente está empezando a usar la IA "local" sin siquiera darse cuenta).

Daniel Blanco 💻🤖@DanielBlancoSWE
Es muy interesante ver la batalla de las empresas que ofrecen productos de IA. Hace unos meses, el enfoque principal era quemar dinero para ofrecer un mejor servicio. Ya sea en forma de tokens o en forma de GPUs para entrenar modelos. Parecía que la batalla la ganaría quien pudiese quemar más dinero durante más tiempo. Pero el progreso se estancó. Ahora está claro que tirar dinero a cientos de miles de GPUs no sirve para continuar con la mejora exponencial. PERO sí sirve para continuar ofreciendo un servicio de calidad. Por ejemplo, los últimos movimientos de OpenAI y Cursor fueron claramente en la dirección de ahorrar costes. Y eso se nota MUCHO. Ambas herramientas están "vagas", limitan el razonamiento y dan respuestas mucho menos precisas. Es frustrante ver cómo, en lugar de mejorar el servicio, van a peor con el tiempo a no ser que pagues por uso o te vayas a suscripciones de $200. Creo que la batalla la ganará quien menos traicione a sus clientes con cambios abusivos en sus políticas. Giros como los que he mencionado hacen perder la confianza en un producto, y eso no se recupera con facilidad.
Español
Mariano retweetledi

"I use AI in a separate window. I don't enjoy Cursor or Windsurf, I can literally feel competence draining out of my fingers."
@dhh, the legendary programmer and creator of Ruby on Rails has the most beautiful and philosophical idea about what AI takes away from programmers.
English