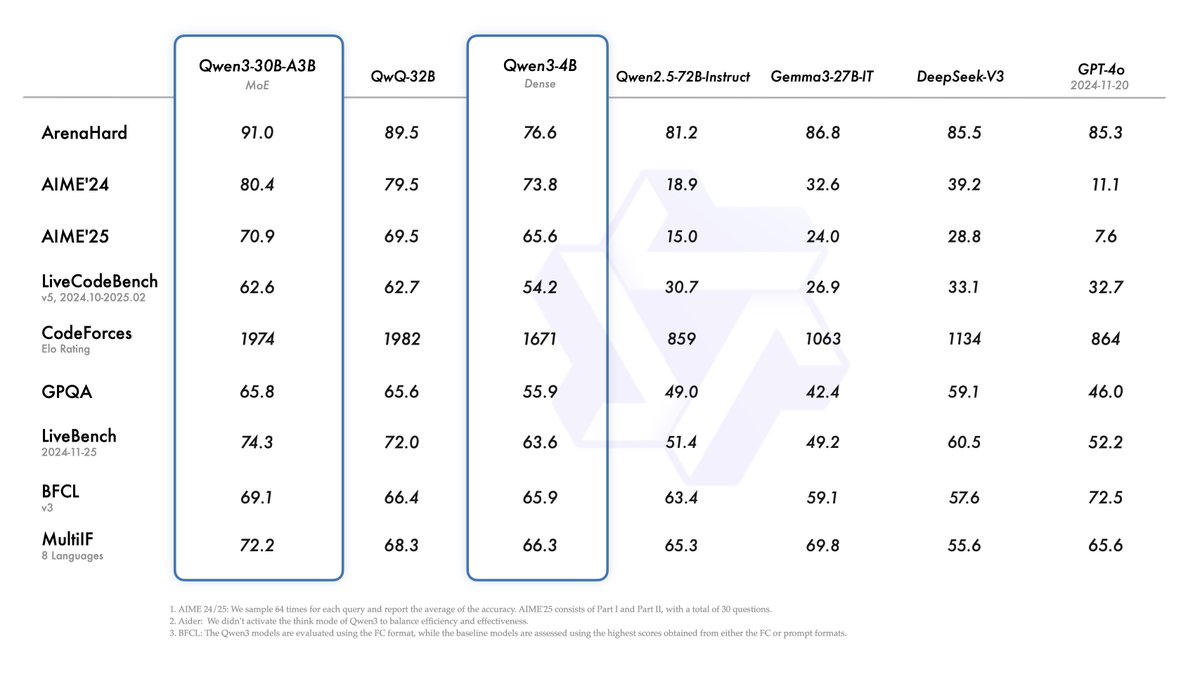
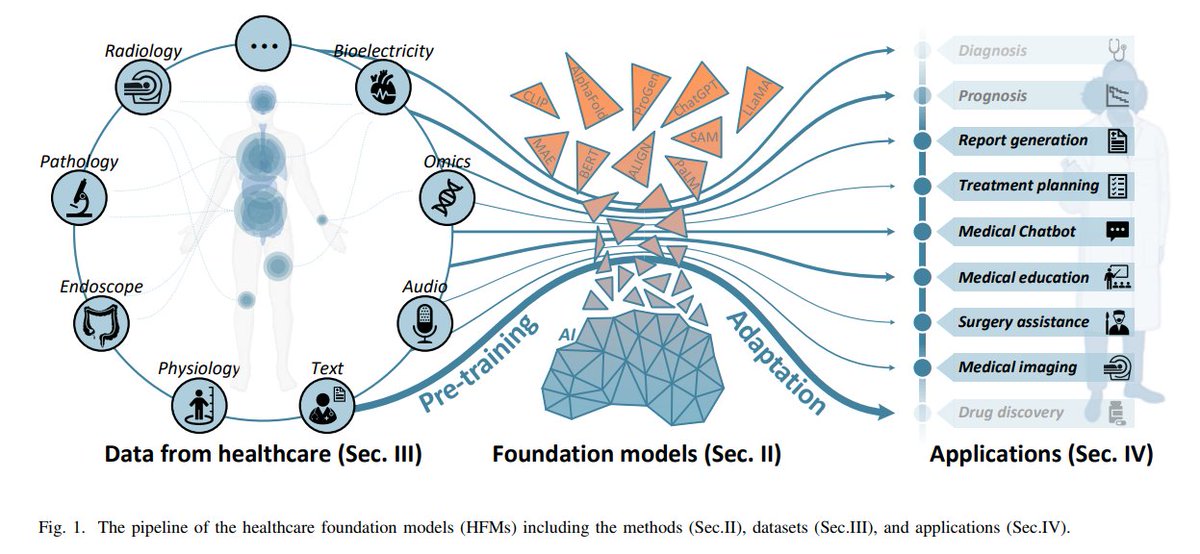
Yuxiang Nie retweetledi

Meet SmartCare! 🚀 Developed by SmartLab (Lead by S. He and Y. Nie @npyuxl) at HKUST. Now pilot-testing at the campus clinic with 15,000+ students & staff. Smarter triage, easier notes, better care. #AI #Healthcare
Read more: smartlab.cse.ust.hk/2025/07/29/sma…

English