NTU SPML Lab retweetledi

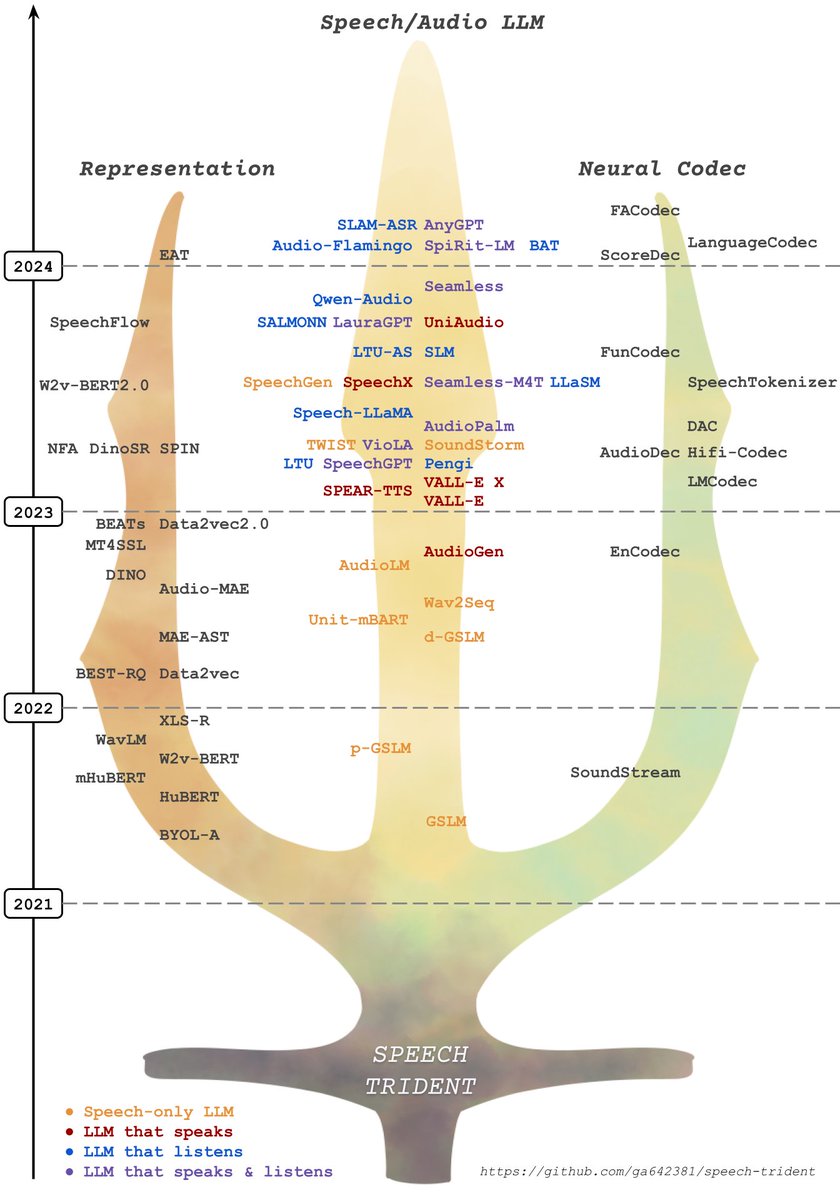
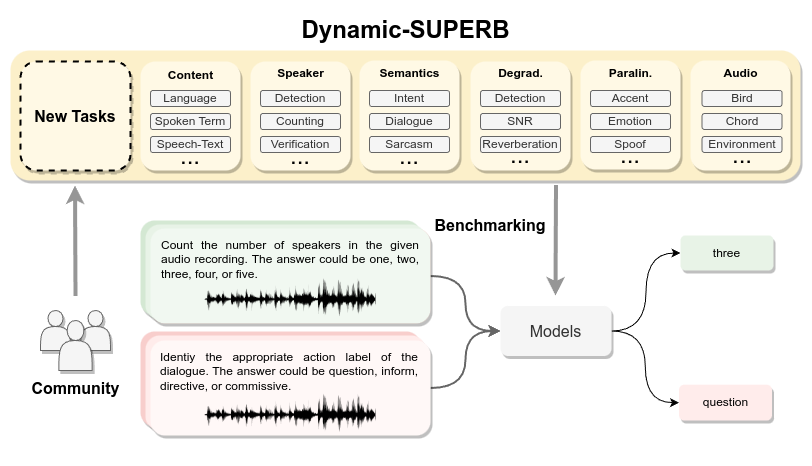
Join us for the Dynamic-SUPERB call-for-tasks event. Submit your innovative task to challenge the speech foundation models that can understand task instruction. Let's push the boundaries of what speech foundation models can do! github.com/dynamic-superb…
English