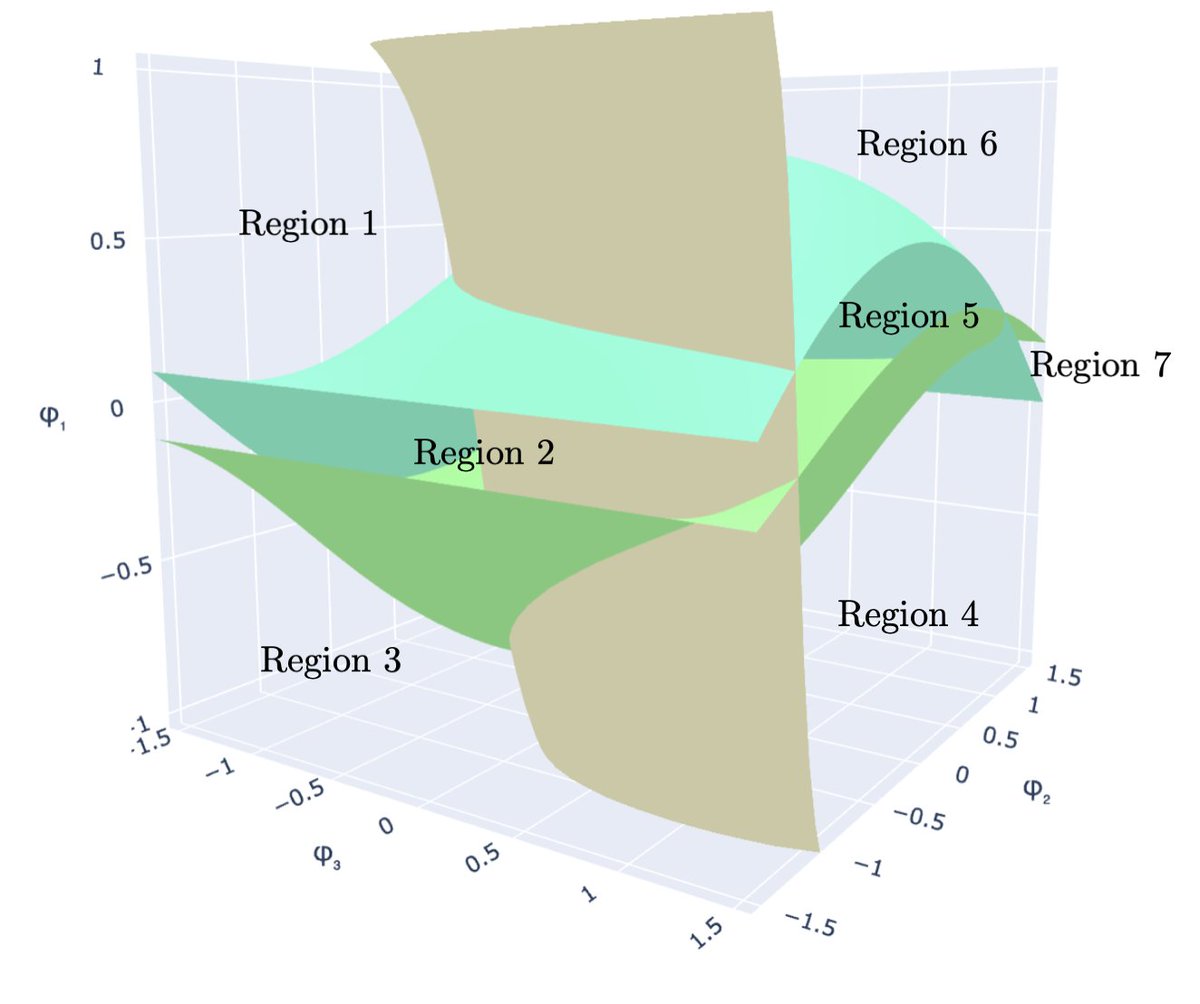
📄 arxiv.org/abs/2602.20376
🌐 akyrillidis.github.io/explore-quantu…
With Ria Stevens, Fangshuo Liao, Barbara Su, Jianqiang Li #MaxCut #CombinatorialOptimization #Algorithms
Indonesia
OptimaLab
387 posts

@optimalab1
Optimization for ML at Rice University (CS) led by Associate Prof. Anastasios Kyrillidis - Efficient training methods, non-convex optimization, and more.