
@DanielleFong i think it’s latent compaction. if you could make that work…. 🙇🏻
English
britt
6.1K posts

@p3ery
I love music, my dog and making things. building @cnvrsai


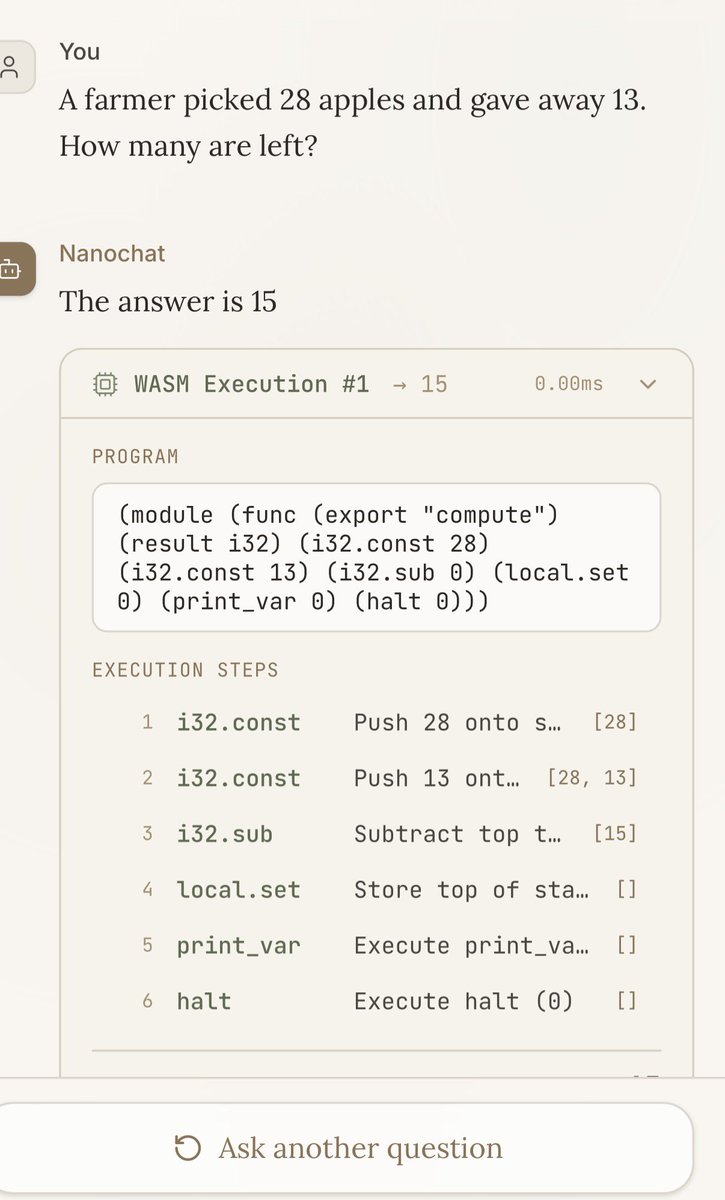
@__morse @thdxr @chrisbanes @opencode here’s a lil calculator to hopefully give a bit more structured intuition to what i’m specifically describing — would love real usage data to inform the calculations! it’s not so bad for smaller conversations, but longer chats add up …8376511f1b44542b51c65c3df.web.val.run

















At Stripe we have a tool called "minions" -- it lets us kick off async agents built right in our dev environment to one-shot bugs, features, and more e2e. I have team, project, and personal channels dedicated just to working with minions. I like to think of it as a new type of pair programming -- "pair prompting." Read more --> stripe.dev/blog/minions-s…

@justinskycak let’s see what the hype’s about


Watch Cursor build a 3M+ line browser in a week

