Sabitlenmiş Tweet

if you think gpt-4.5 is big wait til you see gpt-4.11
OpenAI@OpenAI
GPT-4.5 has entered the Chat. openai.com/live/
English
Patrick Chao
54 posts
GPT-4.5 has entered the Chat. openai.com/live/
On GDPval, an eval measuring well-specified knowledge work tasks across 44 occupations, GPT-5.2 Thinking is our first model that performs at a human expert level. These tasks include making presentations, spreadsheets, and other artifacts.



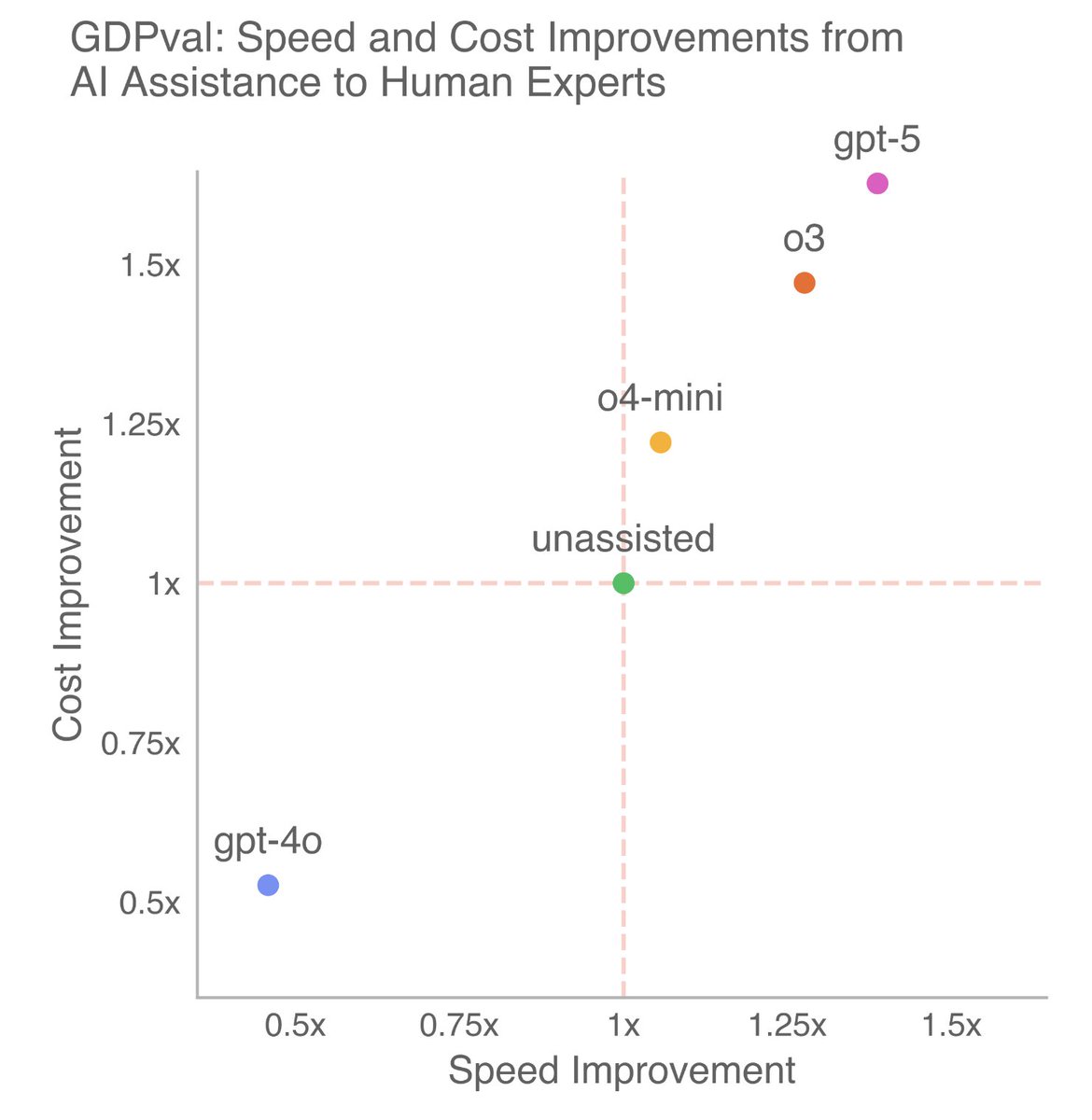
Today we’re introducing GDPval, a new evaluation that measures AI on real-world, economically valuable tasks. Evals ground progress in evidence instead of speculation and help track how AI improves at the kind of work that matters most. openai.com/index/gdpval-v0
GPT-5 is what you’ve been waiting for – it defines and extends the cost-intelligence frontier across model sizes today. it’s been a long journey, and we’ve landed pivotal improvements across many axes in the whole GPT-5 family. and hey no more model picker (by default)!









Advanced Voice is rolling out to all Plus and Team users in the ChatGPT app over the course of the week. While you’ve been patiently waiting, we’ve added Custom Instructions, Memory, five new voices, and improved accents. It can also say “Sorry I’m late” in over 50 languages.

We're releasing a preview of OpenAI o1—a new series of AI models designed to spend more time thinking before they respond. These models can reason through complex tasks and solve harder problems than previous models in science, coding, and math. openai.com/index/introduc…





