Sabitlenmiş Tweet

I successfully defended my Ph.D. dissertation and started working at @MicrosoftAI as a Technical Advisor to the CEO! I'm excited to help make Copilot the most empowering, empathetic, and useful AI companion.

English
Paul Soulos
198 posts
@paulsoulos
Technical Advisor to the CEO @MicrosoftAI. Previously Neurosymbolic PhD @JhuCogsci, intern @ibmresearch and @msftresearch, and software @fitbit and @Google.


Claude Cowork feels very retro-futuristic to me: we’re summoning hyper-intelligent agents from the future, while at the same time returning to ancient file-and-folder rituals.
We believe this is the first documented case of a large-scale AI cyberattack executed without substantial human intervention. It has significant implications for cybersecurity in the age of AI agents. Read more: anthropic.com/news/disruptin…





The only bitter lesson is that LLMs have succeeded beyond any expert expectations. Underpinning LLMs is the idea of scaling, which is too often misunderstood as more parameters. Scaling is about using massive compute effectively to maximise the throughput of data ingestion into the learning process to obtain more capable models. We are still far from hitting the limits in this. We are still compute hungry because there is a ton more we could achieve if only we had more compute, from experimental ablations to data acquisition and curation. Scaling is largely about data and evals. The models are now trained on almost all the web and equally large (but growing) self generated synthetic data. sifting through such vasts quantities of data (the whole of the human creation) requires formidable engineering and intelligent ideas. This is what differentiates most models. AI is finally in the hands of billions of users, and with it come billions of tasks - every reasonable user need. This scaling in tasks and evaluations is many orders of magnitude larger than pre-LLMs. Having the right architecture matters, but we know several alternatives could all work well, eg replacing attention in Transformers for RNNs and interleaving such layers with local layers. What matters is fine ablations to maximise hardware usage. This is the realm of sophisticated high-precision engineering. It encompasses semiconductor design, datacenter design, distributed systems, MFU, etc. There is fascinating work on flow matching, JEPA, sparser MoEs, etc, that is all consistent with scaling. I’m terrible at predictions, but in this we have stayed the course. There’s been pleasant surprises like the effectiveness of reasoning, which while allowing for less parameters, still demands even more compute. Sparser multimodal MoEs also will allow for better continual learning. This is an old idea, eg arxiv.org/pdf/1108.3298, which is finally being done at scale. Successful scaling is mostly about organising people into effective teams for research, development and production. They have to be teams of happy and ambitious people who put the team first. Yes, tech VCs and CEOs: work life balance matters to achieve prologued success, something I think @demishassabis did really well at @GoogleDeepMind and which I promote at @MicrosoftAI. Bitter lesson: it really is all about scaling and hard work by thousands of amazing people. Hardly bitter, but hopeful and inspiring.



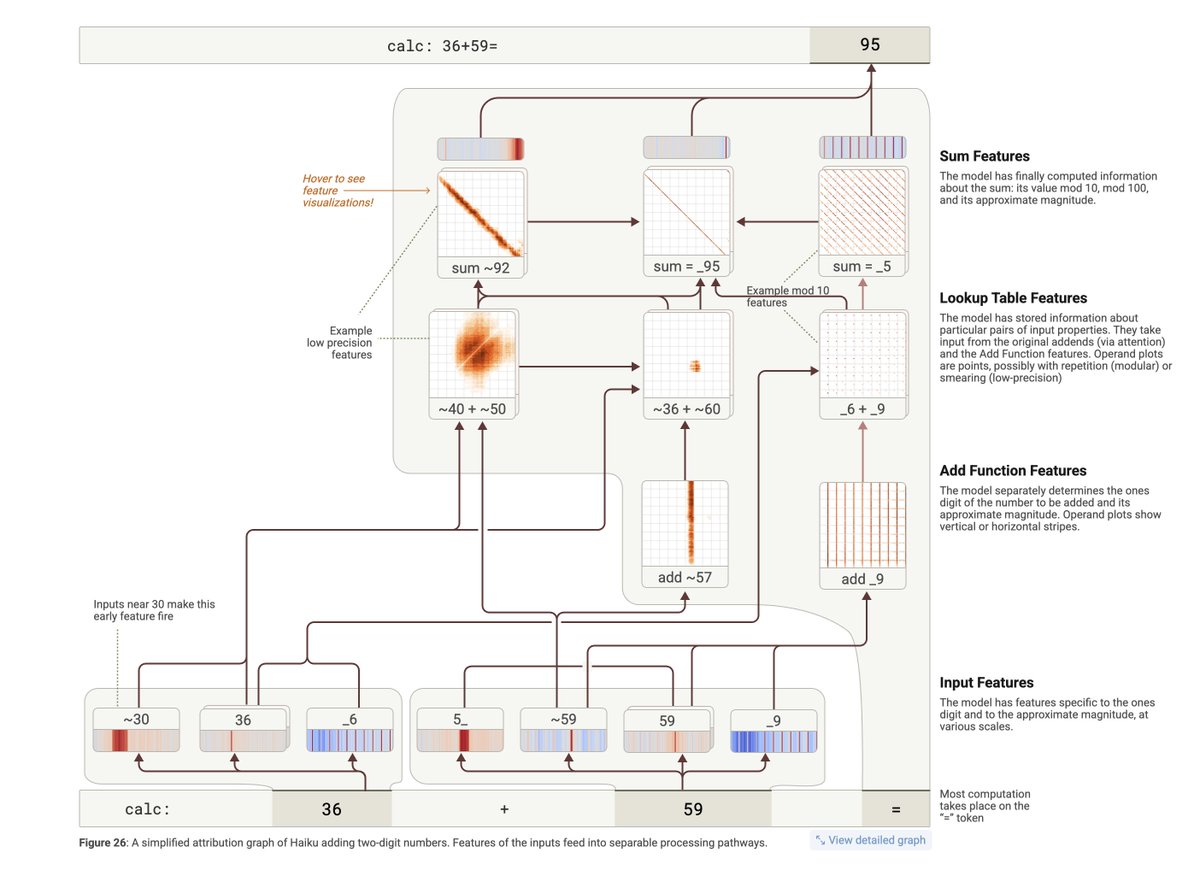


New Anthropic research: Tracing the thoughts of a large language model. We built a "microscope" to inspect what happens inside AI models and use it to understand Claude’s (often complex and surprising) internal mechanisms.

🚀 Introducing NSA: A Hardware-Aligned and Natively Trainable Sparse Attention mechanism for ultra-fast long-context training & inference! Core components of NSA: • Dynamic hierarchical sparse strategy • Coarse-grained token compression • Fine-grained token selection 💡 With optimized design for modern hardware, NSA speeds up inference while reducing pre-training costs—without compromising performance. It matches or outperforms Full Attention models on general benchmarks, long-context tasks, and instruction-based reasoning. 📖 For more details, check out our paper here: arxiv.org/abs/2502.11089




