Philip Monk
1.8K posts


Philip Monk
@pcmonk
A man alive, walking on two legs about the world. Infra lead @essential_ai


Ai has its uses. Here’s a recent one, I witnessed firsthand: A Soldier was notified that they had a substantial financial debt to the tune of close to 7k dollars. The only problem? The Soldier has no idea what the issue is, so they go to finance. Finance can’t figure it out. They say the debt is legitimate and the Soldier must pay. His only option is to request forgiveness from the first COL in the chain of command. In order to do so, he must provide evidence as to why he doesn’t owe the money. The problem is that no one knows what the debt is for, so he cant provide evidence. So him and the 1SG take all of his paystubs and put it into GenAi. The response? There was a mistake at a previous duty station. Not only does he not owe the money, finance owes HIM money. He takes all the evidence to finance. They process everything and he goes from owing thousands to getting thousands. Stay on top of your finances folks.

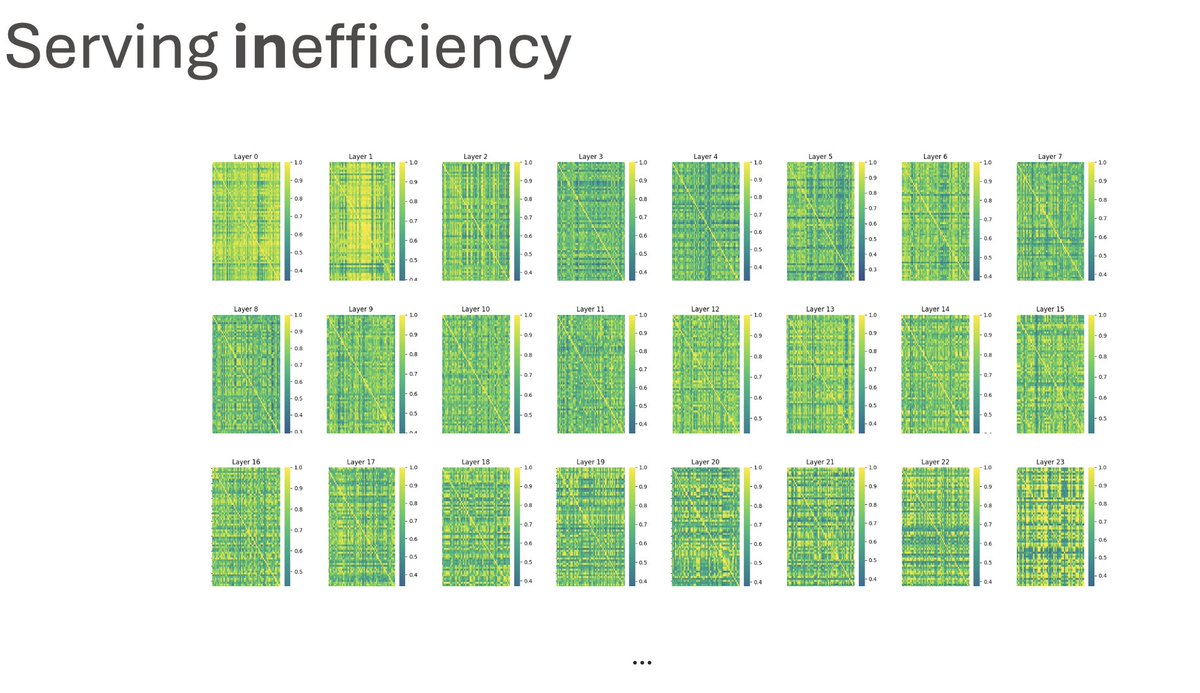

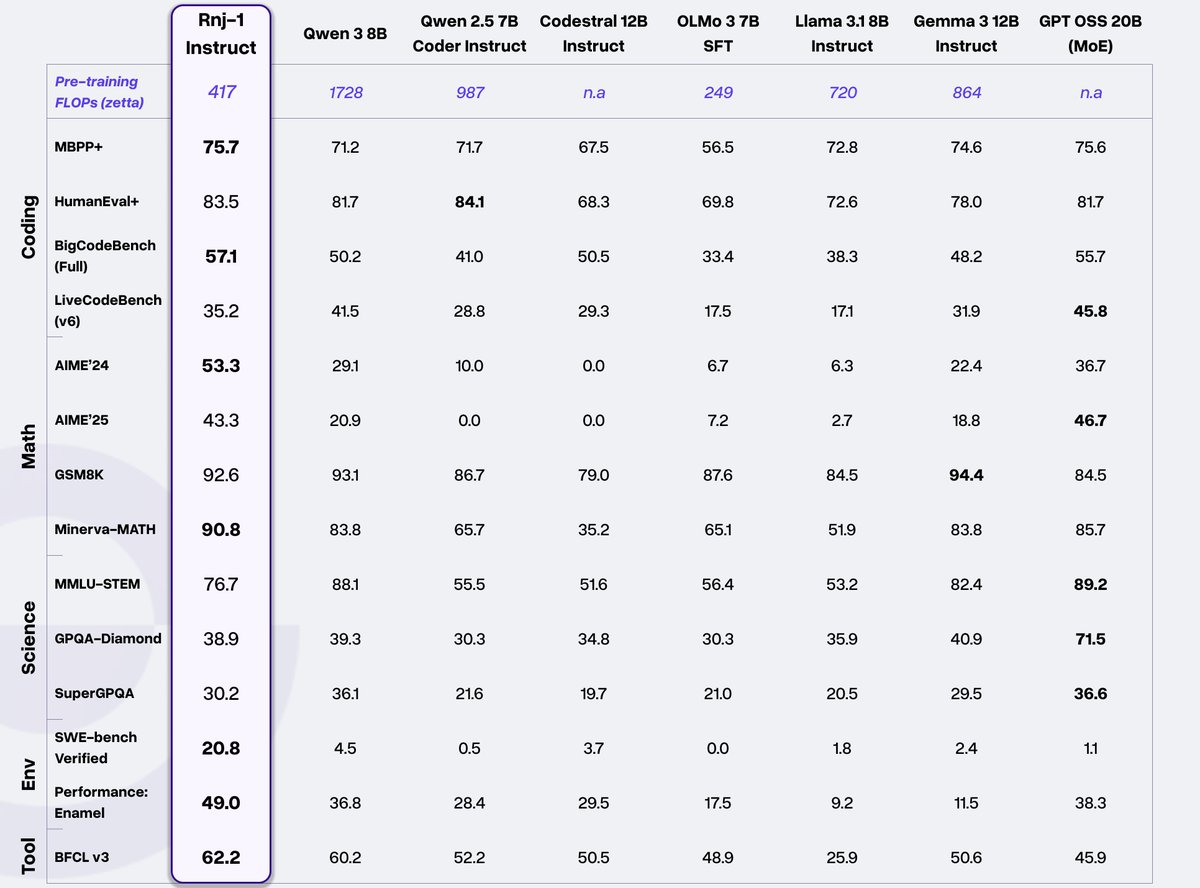
We are beyond thrilled to share our first flagship models, Rnj-1 base and instruct 8B parameter models. Rnj-1 is the culmination of 10 months of hard work by a phenomenal team, dedicated to advancing American SOTA OSS AI. Lots of wins with Rnj-1. 1. SWE bench performance close to GPT 4o. 2. Tool use outperforming all comparable open source models. 3. Mathematical reasoning (AIME’25) nearly at par with GPT OSS MoE 20B. ….



The things that are hard about ml infra are not things that rust solves

“We can just write a general purpose VM that compiles to a GPU” t. someone who has never looked at a roofline chart
The fact that Python is the standard for machine learning is a serious indictment of the field’s engineering standards