
More news on the hiring front @cloudera : we are hiring over 175 people across Europe, Asia and the Americas to build an amazing data platform!
linkedin.com/posts/phunt1_c…
English
Patrick Hunt
2.8K posts
@phunt
Apache ZooKeeper committer, Cloudera Employee, Hacker, Architect, Husband, Dad







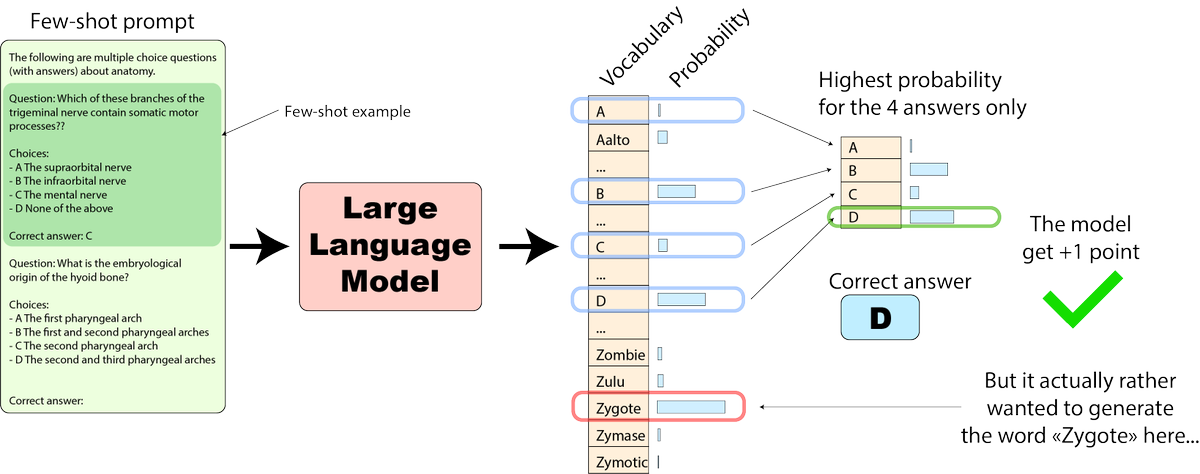

1/ We are launching SEAL Leaderboards—private, expert evaluations of leading frontier models. Our design principles: 🔒Private + Unexploitable. No overfitting on evals! 🎓Domain Expert Evals 🏆Continuously Updated w/new Data and Models Read more in 🧵 scale.com/leaderboard


I pulled together notes on all of the LLM plugins that have worked for me for Llama 3 - both for hosting locally (I've run 8B and 70B on my 64GB M2) and access via APIs (Groq is SO FAST for that) Options for accessing Llama 3 from the terminal using LLM simonwillison.net/2024/Apr/22/ll…

Introducing Gemma: a family of lightweight, state-of-the-art open models for developers and researchers to build with AI. 🌐 We’re also releasing tools to support innovation and collaboration - as well as to guide responsible use. Get started now. → dpmd.ai/3UJu1Y1
(plz retweet) Today we launched my new startup Vectara & announced the general availability of our easy-to-use API-first #NeuralSearch as a service. It comes with 15,000 queries/month for free. I invite you to learn more and signup for the free offering at vectara.com/meet-vectara-p…







