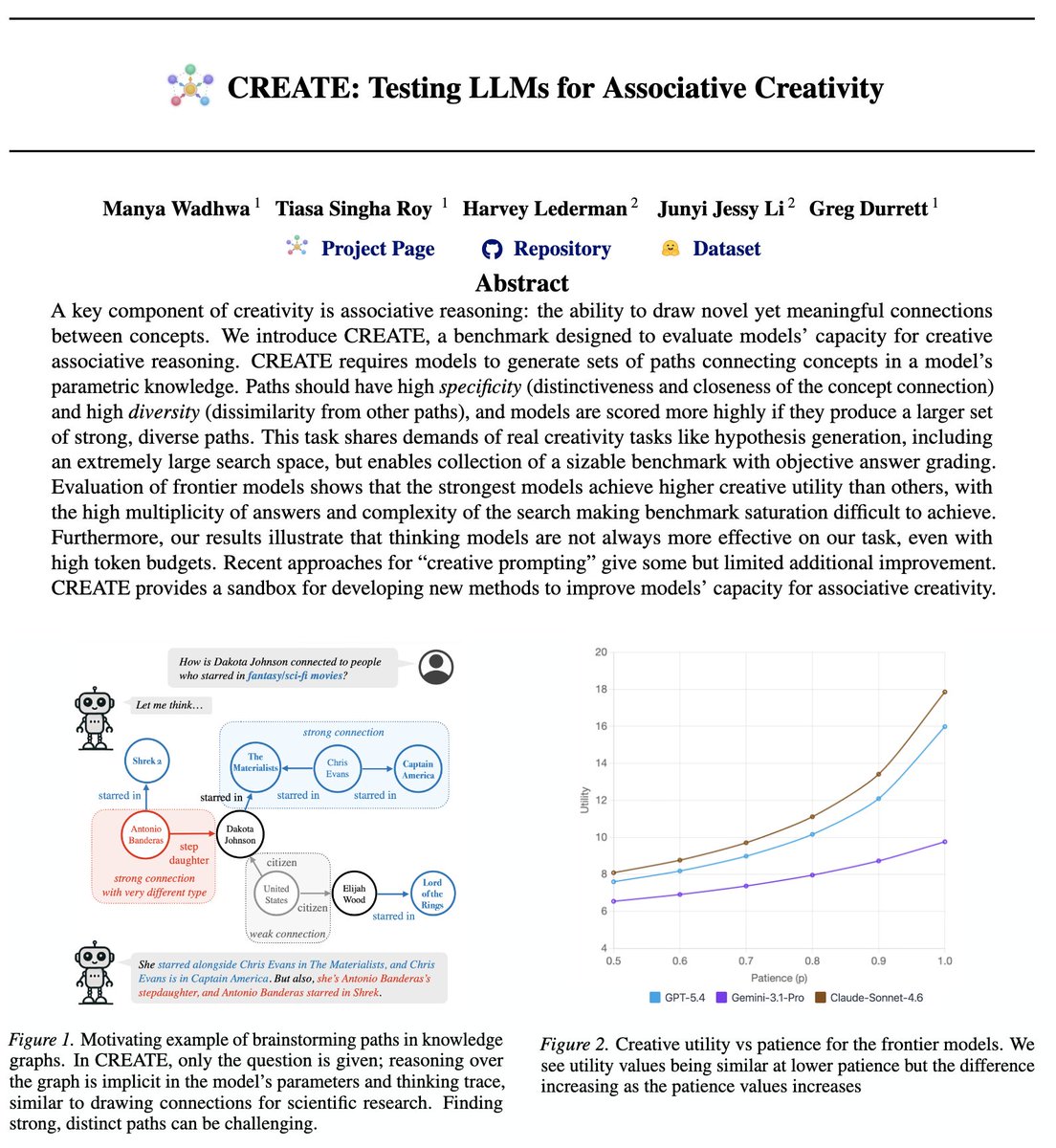
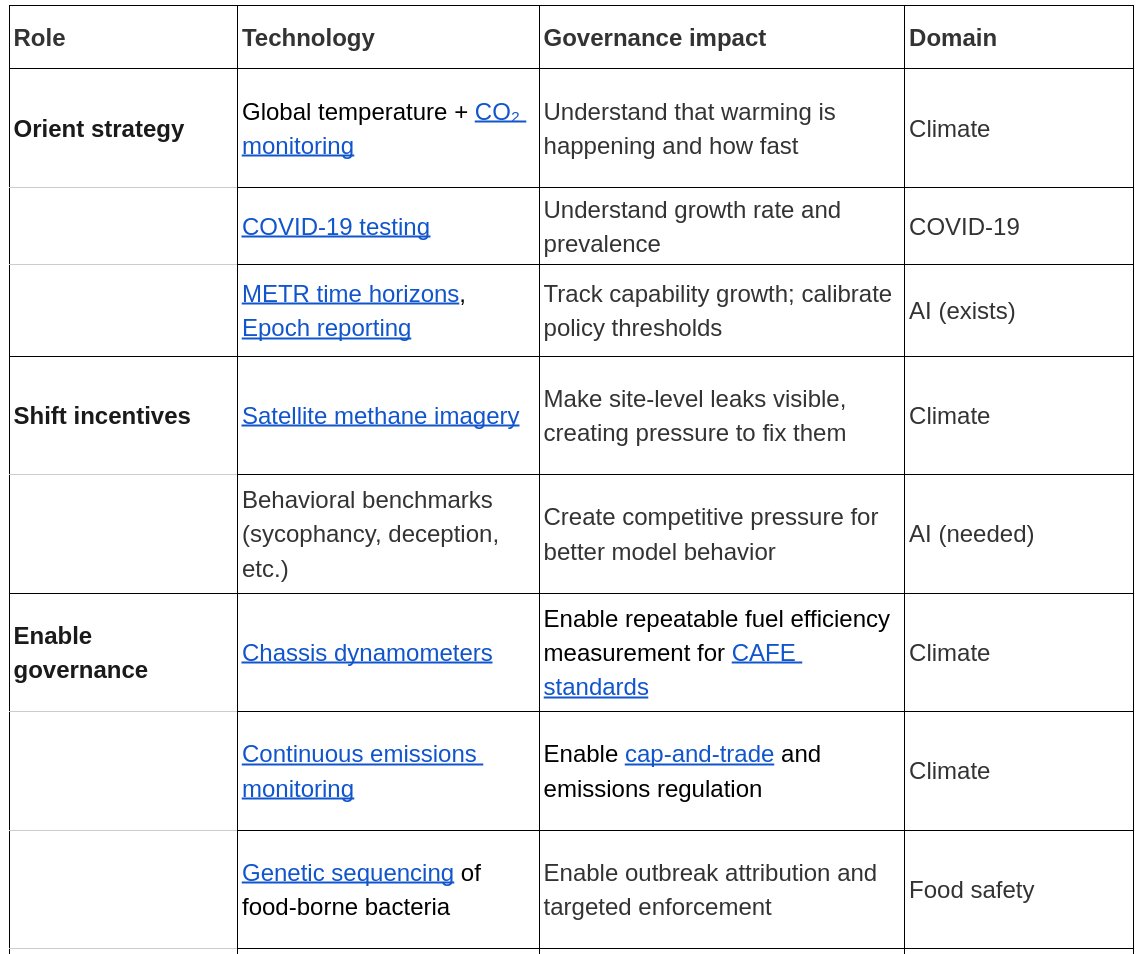
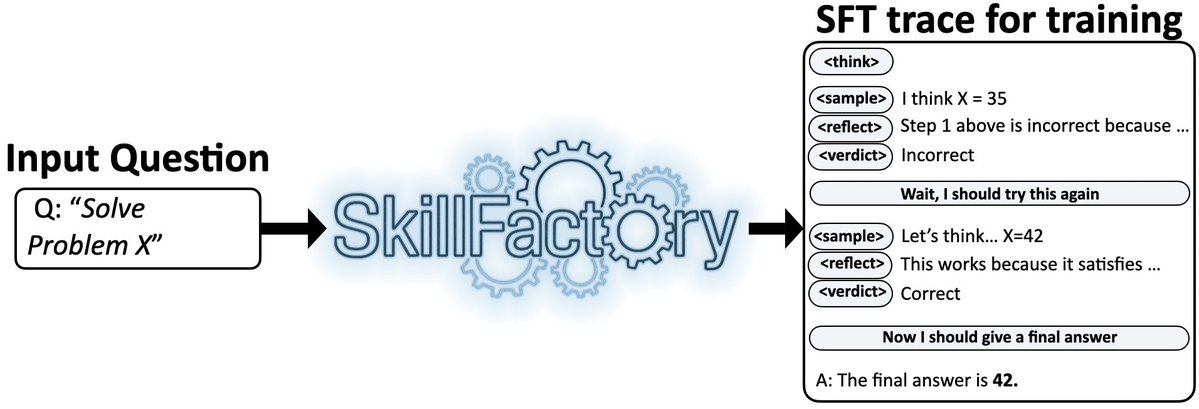
Prasann Singhal retweetledi

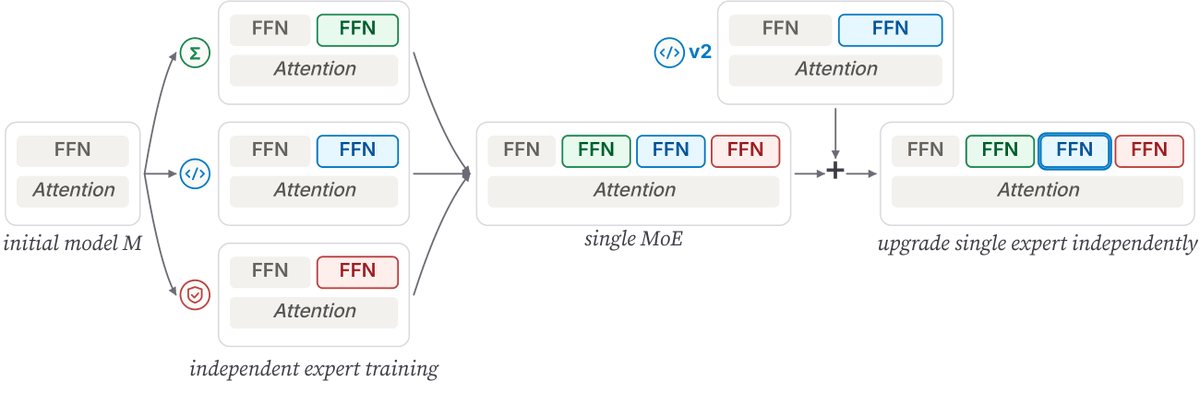
Imagine you fully post-trained "YourModel v1". Then, you've got better data — math, code, tool use, safety — and you want to improve it.
Today, that usually means retraining the whole model.
But what if new data could be added modularly, with a fixed cost each time?
Ai2@allen_ai
Last year, we introduced FlexOlmo, a novel way to train parts of a model independently then combine them later. BAR builds on that idea for a harder problem: how to keep improving a model without having to retrain each time. 🧵
English