
Sabitlenmiş Tweet

Introducing QIE-Bbox-Studio! 🔥🤗
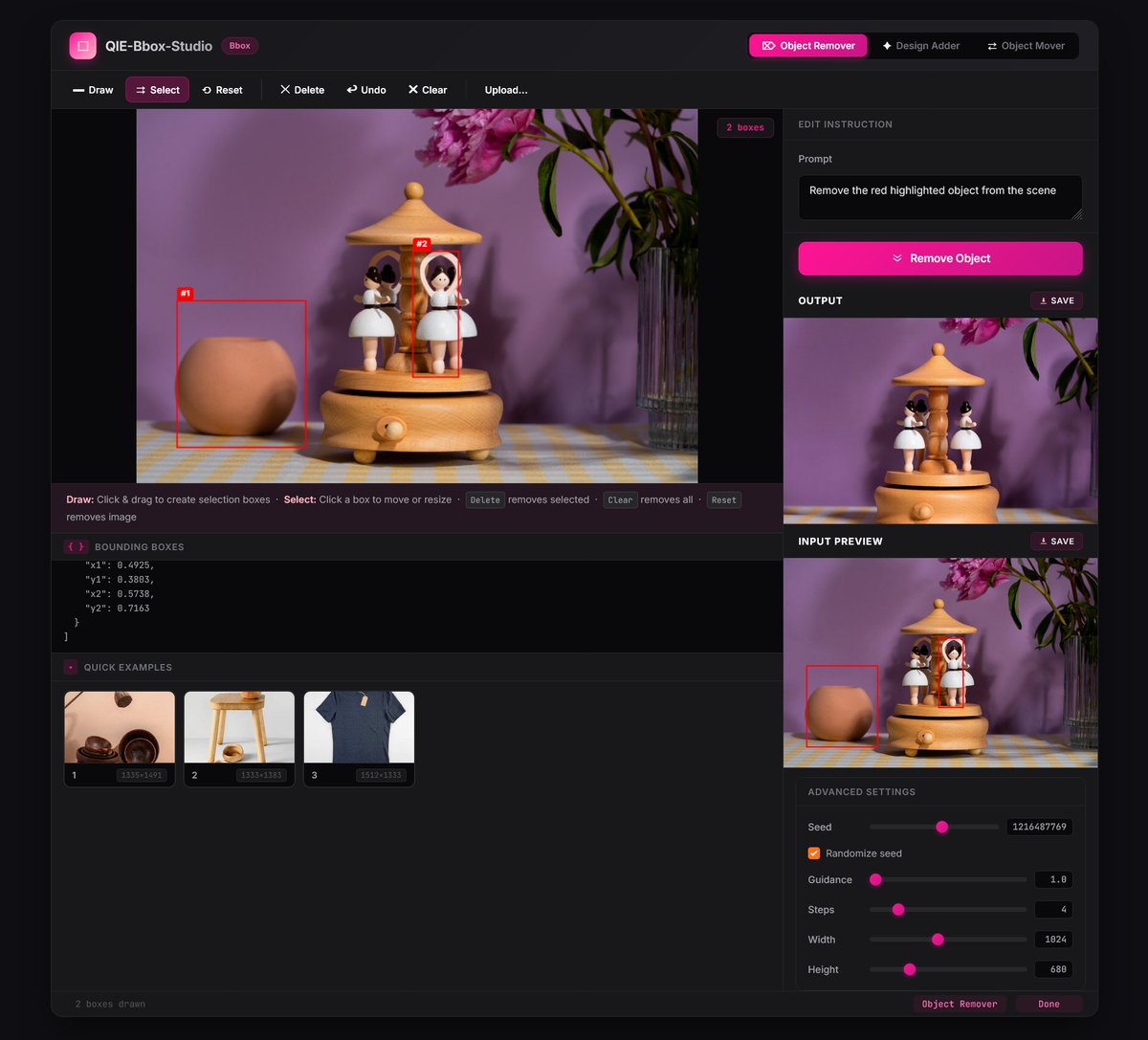
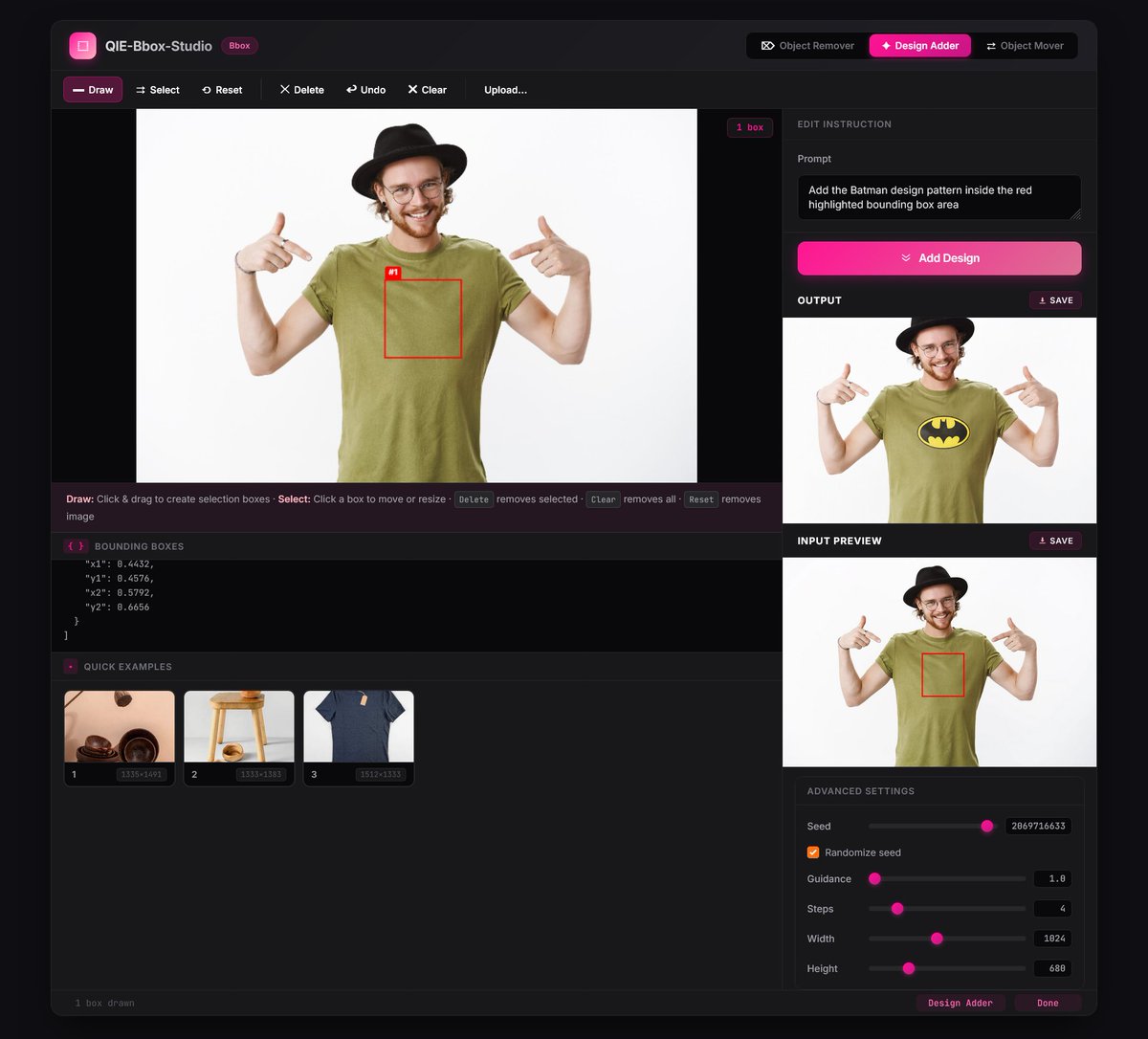
The QIE-Bbox-Studio demo is now live: more precise and packed with powerful new features. You can manipulate images with ease: remove objects, add designs, and even move elements from one place to another, all in a fast 4-step inference process.

English






