
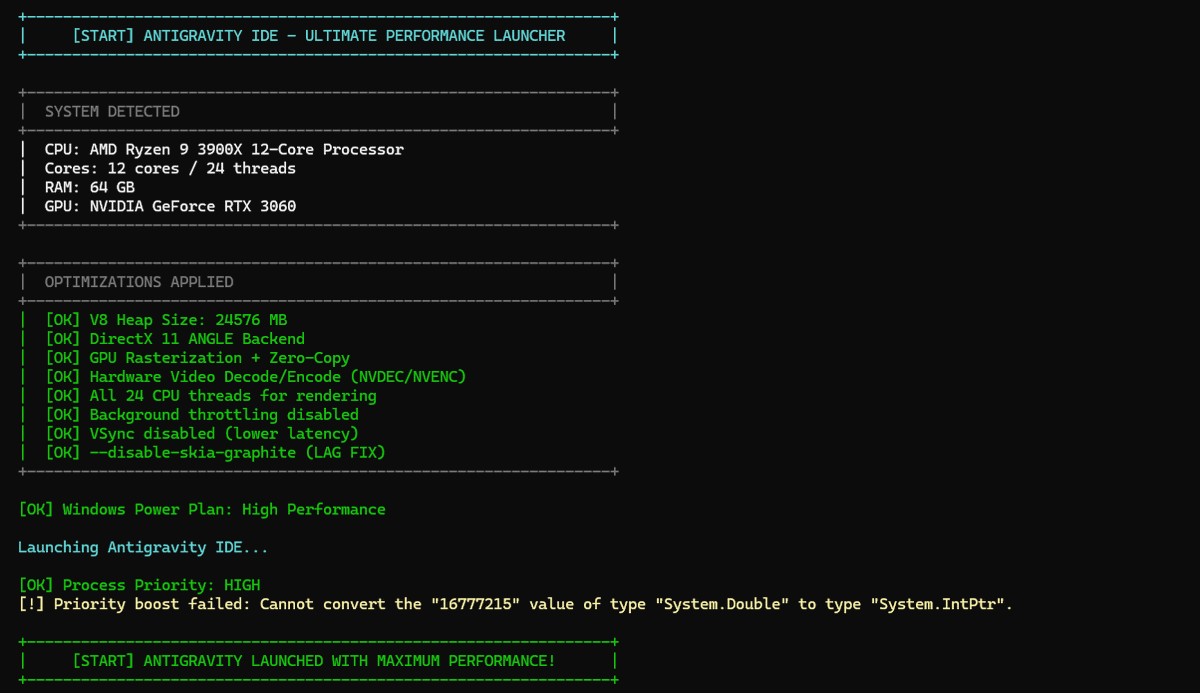
Built the 'ULTIMATE PERFORMANCE LAUNCHER' for @antigravity
→ 64GB RAM
→ RTX 3060
→ Max V8 heap
→ Every GPU flag known to man
Result: Extension hosts still dying and the profiler having a panic attack.
10/10 would over-engineer again.
English
quinten
196 posts

@quint3ns
building @provnai @provncloud verifiable infra for the agentic era 🇧🇪



The existential risk of artificial intelligence.


google should just give up on ai at this point




🚨 BREAKING: Google DeepMind just mapped the attack surface that nobody in AI is talking about. Websites can already detect when an AI agent visits and serve it completely different content than humans see. > Hidden instructions in HTML. > Malicious commands in image pixels. > Jailbreaks embedded in PDFs. Your AI agent is being manipulated right now and you can't see it happening. The study is the largest empirical measurement of AI manipulation ever conducted. 502 real participants across 8 countries. 23 different attack types. Frontier models including GPT-4o, Claude, and Gemini. The core finding is not that manipulation is theoretically possible it is that manipulation is already happening at scale and the defenses that exist today fail in ways that are both predictable and invisible to the humans who deployed the agents. Google DeepMind built a taxonomy of every known attack vector, tested them systematically, and measured exactly how often they work. The results should alarm everyone building agentic systems. The attack surface is larger than anyone has publicly acknowledged. Prompt injection where malicious instructions hidden in web content hijack an agent's behavior works through at least a dozen distinct channels. Text hidden in HTML comments that humans never see but agents read and follow. Instructions embedded in image metadata. Commands encoded in the pixels of images using steganography, invisible to human eyes but readable by vision-capable models. Malicious content in PDFs that appears as normal document text to the agent but contains override instructions. QR codes that redirect agents to attacker-controlled content. Indirect injection through search results, calendar invites, email bodies, and API responses any data source the agent consumes becomes a potential attack vector. The detection asymmetry is the finding that closes the escape hatch. Websites can already fingerprint AI agents with high reliability using timing analysis, behavioral patterns, and user-agent strings. This means the attack can be conditional: serve normal content to humans, serve manipulated content to agents. A user who asks their AI agent to book a flight, research a product, or summarize a document has no way to verify that the content the agent received matches what a human would see. The agent cannot tell the user it was served different content. It does not know. It processes whatever it receives and acts accordingly. The attack categories and what they enable: → Direct prompt injection: malicious instructions in any text the agent reads overrides goals, exfiltrates data, triggers unintended actions → Indirect injection via web content: hidden HTML, CSS visibility tricks, white text on white backgrounds invisible to humans, consumed by agents → Multimodal injection: commands in image pixels via steganography, instructions in image alt-text and metadata → Document injection: PDF content, spreadsheet cells, presentation speaker notes every file format is a potential vector → Environment manipulation: fake UI elements rendered only for agent vision models, misleading CAPTCHA-style challenges → Jailbreak embedding: safety bypass instructions hidden inside otherwise legitimate-looking content → Memory poisoning: injecting false information into agent memory systems that persists across sessions → Goal hijacking: gradual instruction drift across multiple interactions that redirects agent objectives without triggering safety filters → Exfiltration attacks: agents tricked into sending user data to attacker-controlled endpoints via legitimate-looking API calls → Cross-agent injection: compromised agents injecting malicious instructions into other agents in multi-agent pipelines The defense landscape is the most sobering part of the report. Input sanitization cleaning content before the agent processes it fails because the attack surface is too large and too varied. You cannot sanitize image pixels. You cannot reliably detect steganographic content at inference time. Prompt-level defenses that tell agents to ignore suspicious instructions fail because the injected content is designed to look legitimate. Sandboxing reduces the blast radius but does not prevent the injection itself. Human oversight the most commonly cited mitigation fails at the scale and speed at which agentic systems operate. A user who deploys an agent to browse 50 websites and summarize findings cannot review every page the agent visited for hidden instructions. The multi-agent cascade risk is where this becomes a systemic problem. In a pipeline where Agent A retrieves web content, Agent B processes it, and Agent C executes actions, a successful injection into Agent A's data feed propagates through the entire system. Agent B has no reason to distrust content that came from Agent A. Agent C has no reason to distrust instructions that came from Agent B. The injected command travels through the pipeline with the same trust level as legitimate instructions. Google DeepMind documents this explicitly: the attack does not need to compromise the model. It needs to compromise the data the model consumes. Every agentic system that reads external content is one carefully crafted webpage away from executing attacker instructions. The agents are already deployed. The attack infrastructure is already being built. The defenses are not ready.


