Rakshith Subramanyam retweetledi
Rakshith Subramanyam
9 posts


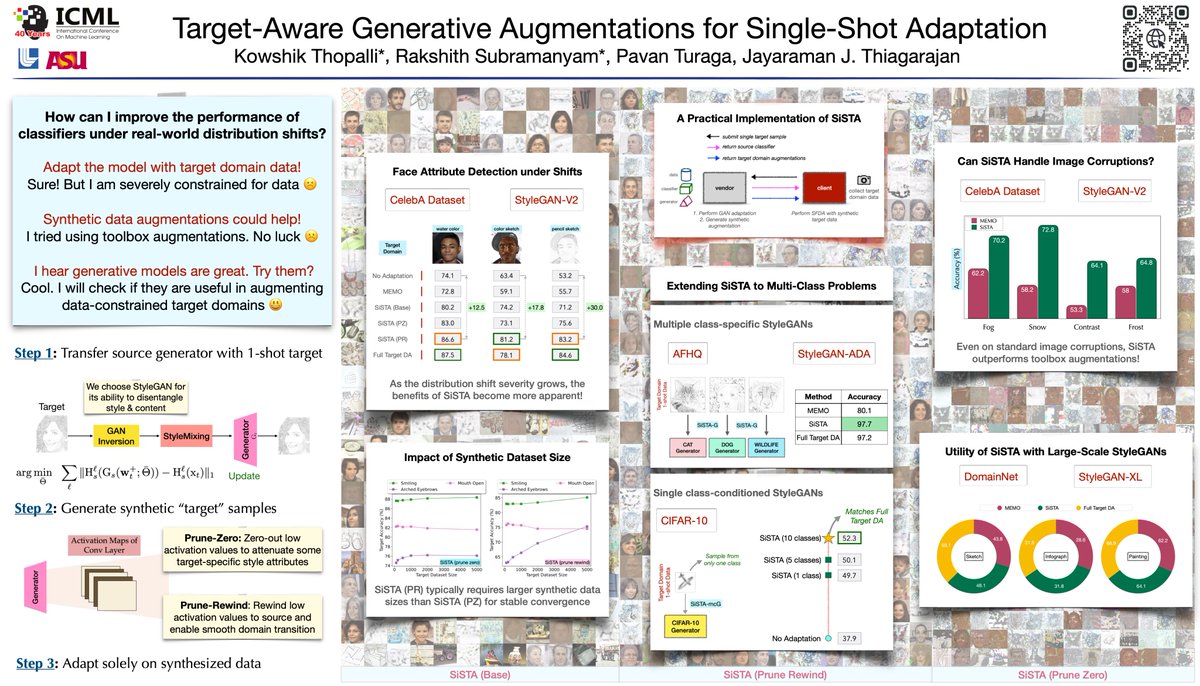
Venturing into single-shot domain adaptation? Meet SiSTA, our solution for large distribution shifts using a single-shot target! 🎯
🌐 Project: rakshith-2905.github.io/SiSTA/
Join us: ⏱️ Session: 27 Jul, 10:30 a.m. HST (Poster #104)
In collaboration with @kowshik0808 @pturaga1 @jjayram7
English
Rakshith Subramanyam retweetledi

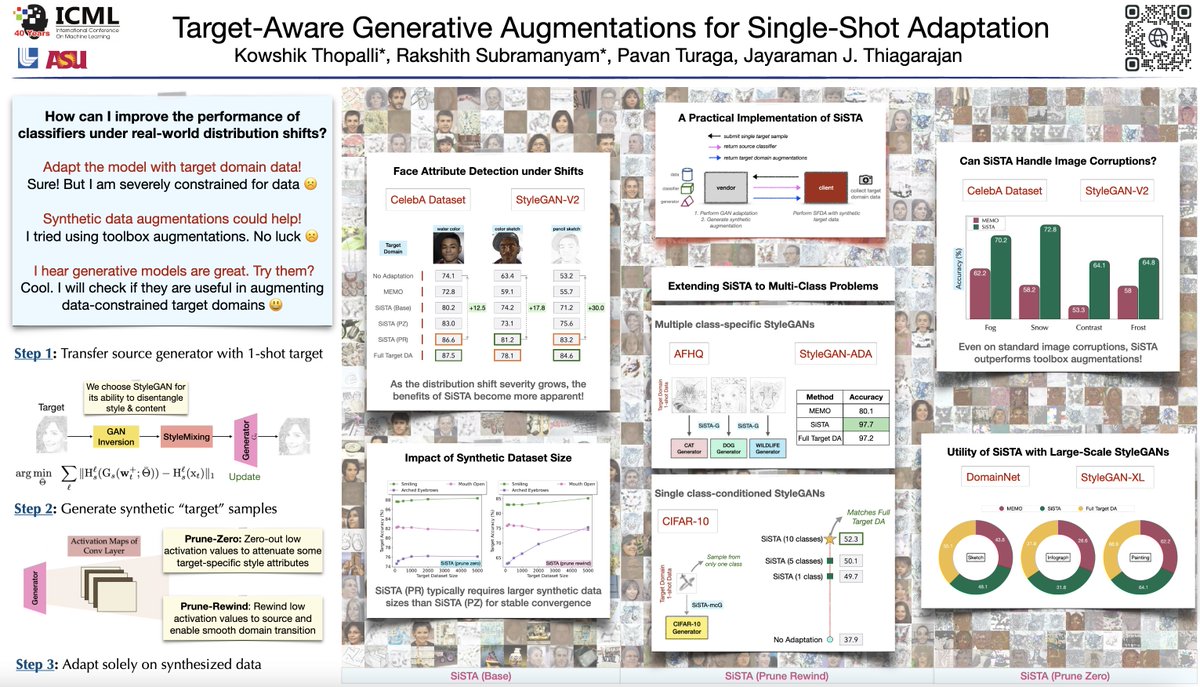
Interested in adapting high quality, pretrained models for safe & effective generalization on downstream tasks? Check out our new paper where we take a closer at model adaptation using feature distortion & simplicity bias! arxiv.org/abs/2303.13500 #ICLR2023🧵
English
Rakshith Subramanyam retweetledi

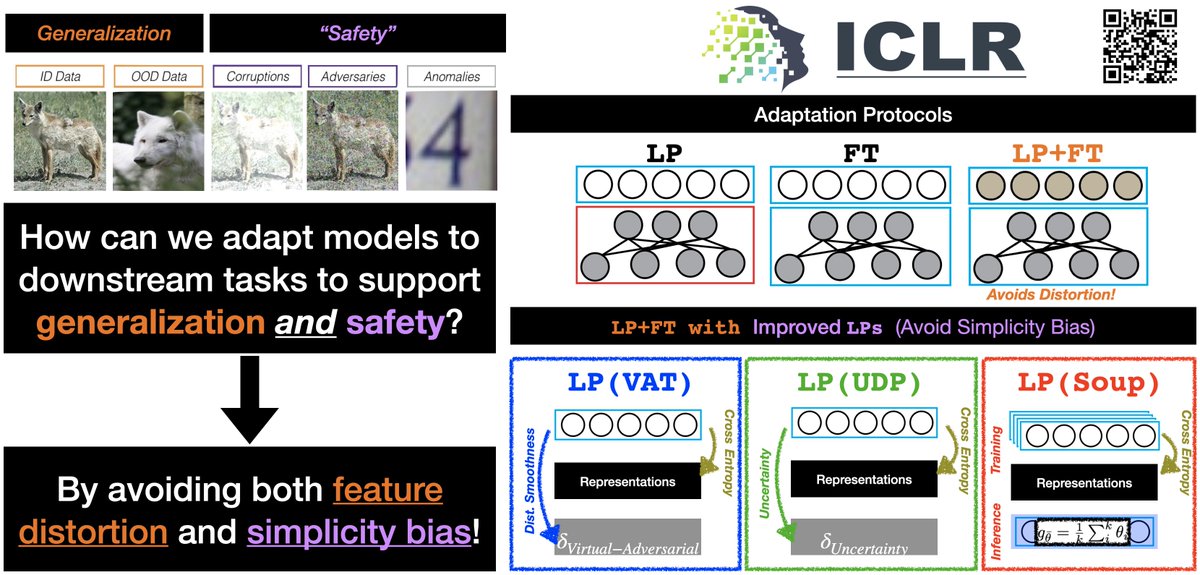
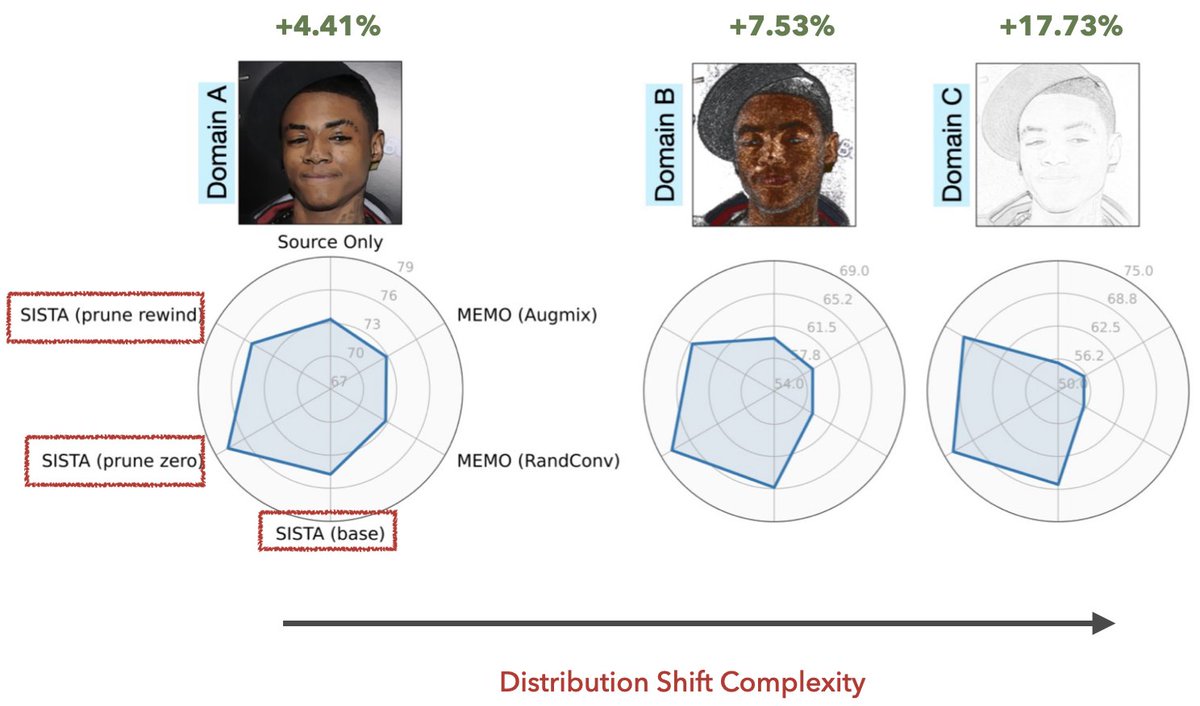
Are large-scale generative models (StyleGAN-XL) useful for data constrained domain adaptation? Our #ICML2023 paper introduces SiSTA, a new data augmentation method that works even with one shot!! Preprint & codes coming out soon. Stay tuned. @kowshik0808 @rakshith_subra @pturaga1
English
Rakshith Subramanyam retweetledi

🇮🇳 🇺🇸 His Excellency @SandhuTaranjitS, India's Ambassador to the United States, recently visited the Luminosity Lab to meet the students and explore the Rodel, our cutting-edge simulation designed to assist policymakers in making informed decisions about Arizona and beyond.


Phoenix, AZ 🇺🇸 English
Rakshith Subramanyam retweetledi
Codes for our #Neurips2022 paper on Delta-UQ are officially out now! If you are looking to quickly integrate an epistemic uncertainty estimator to your deep model, please check this out! @LLNL
Repo: github.com/LLNL/DeltaUQ
Paper: arxiv.org/pdf/2207.07235…
English
Rakshith Subramanyam retweetledi
2. Interested in few-shot learners that generalize across domains or to even unseen datasets? Check out CAML - it uses contrastively trained knowledge graph bridges for meta learning. Here is our paper led by @rakshith_subra
arxiv.org/abs/2207.12346
Jan 5 1815--1915 in Session 6B
English
Rakshith Subramanyam retweetledi
Come check out our work this Saturday at the PODs workshop at #ICML! We look at adapting pretrained models for both safety and generalization. :)
Jay Thiagarajan@jjayaram7
When you want to ensure improved accuracy as well as model safety, do you train a linear probe or fine-tune pre-trained models end-to-end? Check out our poster at the PODS@ICML workshop to learn about the best approach! @puja_computes @danaikoutra 3/9
English
Excited to present our work on repurposing pre-trained StyleGANs to solve inverse problems for Out-Of-Distribution images at #ICML2022, #GANinversion. Check our paper SPHInX proceedings.mlr.press/v162/subramany…
This work is in collaboration with @VivekSivaraman1 and @jjayaram7
Jay Thiagarajan@jjayaram7
Are you interested in re-purposing pre-trained face image StyleGANs to solve inverse problems with your own dataset? Check our paper on SPHINX, a new GAN inversion technique. Spotlight: Tue 19 Jul 8:35 a.m. — 8:40 a.m (PDT) Poster: Tue 19 Jul 3:30 p.m. — 5:30 p.m. (PDT) 2/9
English