Yann LeCun (@ylecun ) explains why LLMs are so limited in terms of real-world intelligence.
Says the biggest LLM is trained on about 30 trillion words, which is roughly 10 to the power 14 bytes of text.
That sounds huge, but a 4 year old who has been awake about 16,000 hours has also taken in about 10 to the power 14 bytes through the eyes alone. So a small child has already seen as much raw data as the largest LLM has read.
But the child’s data is visual, continuous, noisy, and tied to actions: gravity, objects falling, hands grabbing, people moving, cause and effect. From this, the child builds an internal “world model” and intuitive physics, and can learn new tasks like loading a dishwasher from a handful of demonstrations.
LLMs only see disconnected text and are trained just to predict the next token. So they get very good at symbol patterns, exams, and code, but they lack grounded physical understanding, real common sense, and efficient learning from a few messy real-world experiences.
---
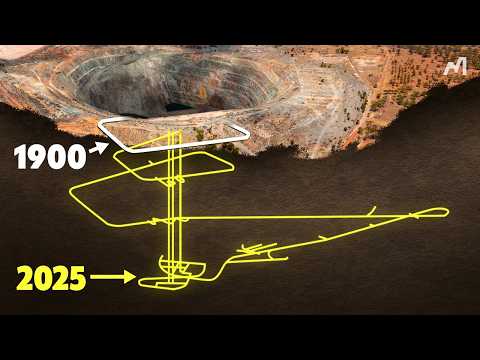
From 'Pioneer Works' YT channel (link in comment)
Apparently no one is paying attention to space garbage from past satellites and instruments clogging up and impeding future launches. Solving this problems could be the next trillion $+ opportunity. youtu.be/8ag6gSzsGbc?si… via @YouTube
This is a brilliant article.
The core idea: you have roughly 12 major “shots” in your career (assuming 4 years each across 50 working years), and three forces determine whether they land. In order of importance: 天 (timing), 地 (place/environment), 人 (people).
Timing matters most because power laws dominate outcomes. You don’t need 12 wins. You need one or two shots that catch the right wave. An average team in the right market at the right moment beats a brilliant team solving yesterday’s problem.
But here’s the tension the framework surfaces: timing is both the most important variable and the least controllable. You can’t predict when 天 aligns. You can only recognize it.
Which changes the strategy completely. The real optimization is shot frequency, not shot selection. You need enough at-bats that one of them accidentally lands in perfect timing. The people who hit outsized outcomes usually ran faster cycles early, failed cheaper, and built the pattern recognition that makes timing visible.
Four years per shot might be too conservative for most people in their 20s and 30s. Compressing cycle time on shots that don’t work teaches you what 天 looks like before you’ve burned half your window.
The “red paperclip” insight in the piece is the real unlock: you probably already have what you need to take your next shot. The constraint is usually permission, not resources.
“You have 12 shots, choose wisely” leads to paralysis. “You have 12 shots, shoot faster” leads to learning.
Fascinating stuff about the power of computational biology and the real positive potential of AI to revolutionize healthcare zmescience.com/feature-post/p…