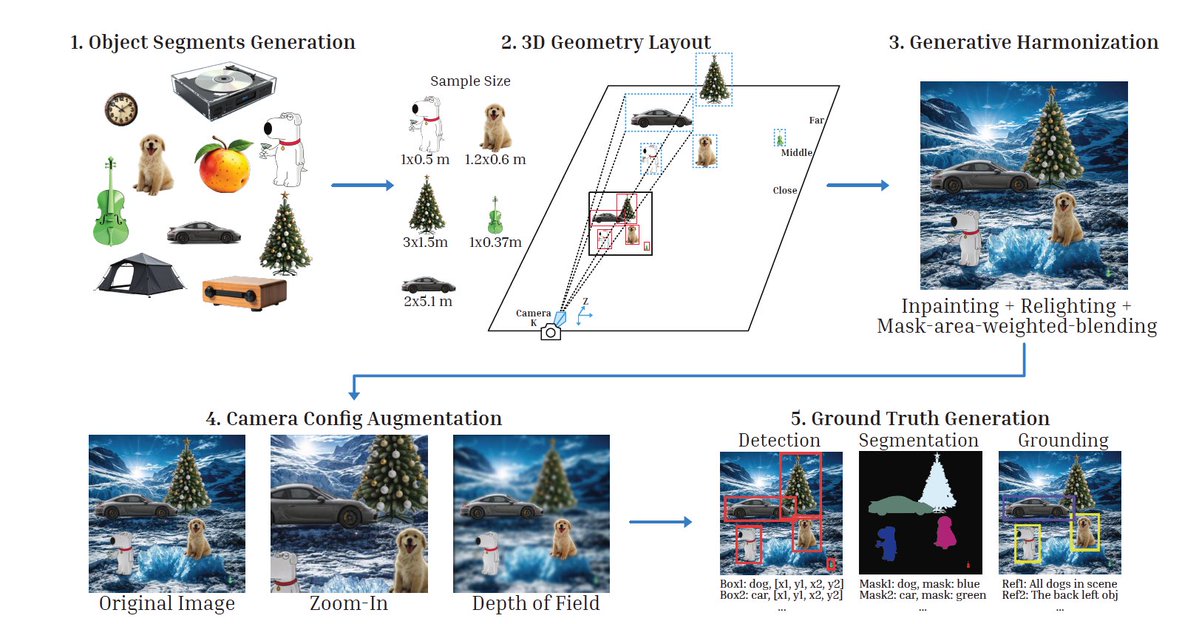
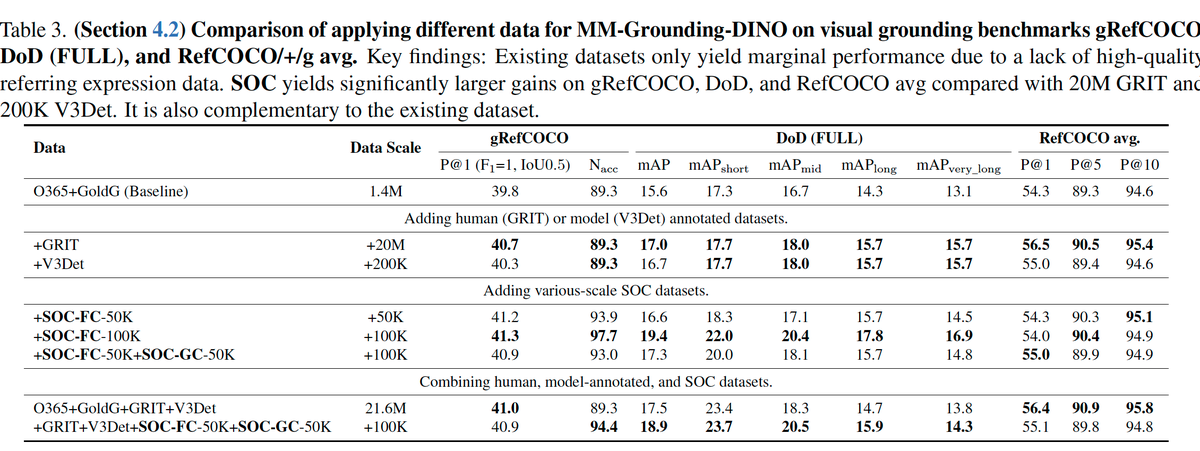
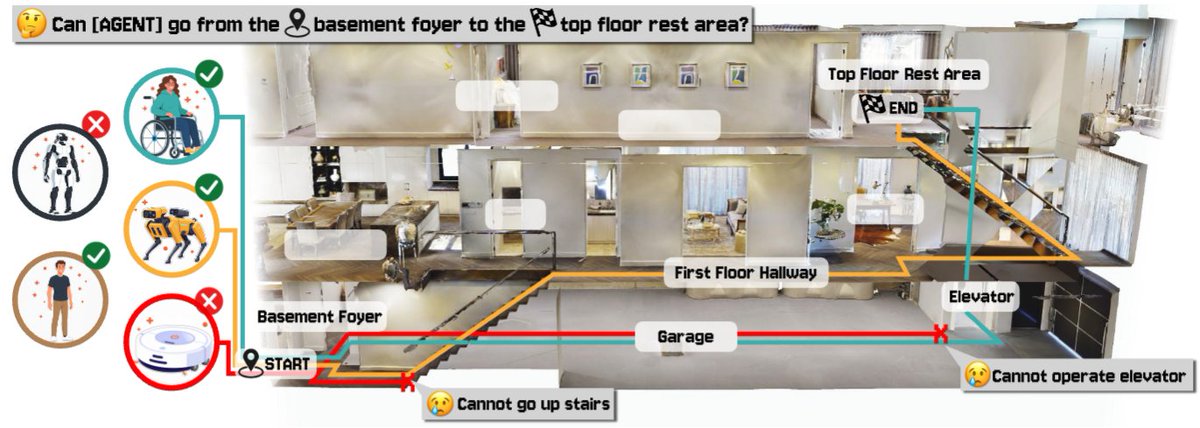
Ranjay Krishna retweetledi

VLMs today—including our own Molmo—point via raw text strings (e.g. ""). What if pointing meant directly selecting the visual tokens instead? 🤔
Introducing MolmoPoint: Better Pointing for VLMs with Grounding Tokens 🎯
🔓models, code, data, demo all OPEN 🧵👇
Paper: allenai.org/papers/molmopo…
English