
@teortaxesTex I mean, makes sense if you think about it as "rotate the self-attention." In a sequence token m represents what is discretely appended at position m, not the accumulated state.
English
evrazian_schizo
361 posts

We're excited to release 𝐃𝐞𝐥𝐭𝐚 𝐀𝐭𝐭𝐞𝐧𝐭𝐢𝐨𝐧 𝐑𝐞𝐬𝐢𝐝𝐮𝐚𝐥𝐬, a drop-in upgrade to residual connections that learns which past layers to route from — without the routing collapse that breaks prior cross-layer attention at scale. 🚀 Attention Residuals route over cumulative hidden states, but those are highly redundant, so routing collapses to near-uniform (max weight ~0.2) in deep layers. Delta Attention Residuals route over 𝐝𝐞𝐥𝐭𝐚𝐬 (vᵢ = hᵢ₊₁ − hᵢ) — what each sublayer actually contributed — and natively enable: ⚡ 𝟏.𝟖× 𝐬𝐡𝐚𝐫𝐩𝐞𝐫 𝐜𝐫𝐨𝐬𝐬-𝐥𝐚𝐲𝐞𝐫 𝐫𝐨𝐮𝐭𝐢𝐧𝐠 Deltas are structurally diverse, lifting max attention weight from ~0.2 → ~0.6 (0.62 vs 0.35 avg) and curing routing collapse in deep layers. 📉 −𝟖.𝟐% 𝐯𝐚𝐥𝐢𝐝𝐚𝐭𝐢𝐨𝐧 𝐏𝐏𝐋 𝐚𝐭 𝟕.𝟔𝐁 Consistent gains from 220M → 7.6B (1.7–8.2% lower PPL), beating both standard residuals and Attention Residuals — the latter actually degrades below baseline at scale (18.58 vs 17.43). 🔌 𝐃𝐫𝐨𝐩-𝐢𝐧 𝐟𝐢𝐧𝐞-𝐭𝐮𝐧𝐢𝐧𝐠 𝐨𝐟 𝐩𝐫𝐞𝐭𝐫𝐚𝐢𝐧𝐞𝐝 𝐦𝐨𝐝𝐞𝐥𝐬 Additive, zero-init routing is identity at initialization, so you can convert pretrained checkpoints (e.g. Qwen3-0.6B) into Delta Attention Residuals via standard fine-tuning — beating the original on 8 downstream benchmarks (55.6 vs 55.0). 🪶 ≤𝟎.𝟎𝟏% 𝐩𝐚𝐫𝐚𝐦𝐞𝐭𝐞𝐫 𝐨𝐯𝐞𝐫𝐡𝐞𝐚𝐝 Delta Block adds just 589K params (0.008% at 8B) and ~3% memory — and runs faster + lighter than Attention Residuals (14.0k vs 12.5k tok/s, 42.7 vs 44.0 GB). 💻 Code: github.com/wdlctc/delta-a… 📄 Paper: arxiv.org/abs/2605.18855

If the AI models are so smart, why do I feel like I’m losing a few neurons every time I read a longer form content written by AI? We’ve come a long way but we still have long way to go. In terms of clarity of writing we may have regressed from o1/o3 days.

Would not be too surprised if this was just sth. like: 60 layer hybrid - 256k "sliding window" attention every 4 blocks ("linear") - GDN in the remaining blocks compared to full attn: (60 * (1M)^2) / (15 * (256K)^2 + 45 * little) ≈ 52x speedup This is Qwen3.5-397B-A17B btw

Introducing SubQ - a major breakthrough in LLM intelligence. It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA), And the first frontier model with a 12 million token context window which is: - 52x faster than FlashAttention at 1MM tokens - Less than 5% the cost of Opus Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention). Only a small fraction actually matter. @subquadratic finds and focuses only on the ones that do. That's nearly 1,000x less compute and a new way for LLMs to scale.

restarted a convo (with V4's + 3 more papers) ≈48 hours old. cache hits they do store cache for "days", not minutes-hours Gemini TTL default is 1 hour, Claude's is 5 minutes Nah bros I don't think they have > V4 kv efficiency, whatever Reiner Pope says

Hybrid SWA is actually an atrocious inductive bias and I'm tired of people using it. Of course it works at small scales! At small scales most of the learnable patterns are short range! That doesn't meant it scales to bigger models! Anything above like 200B params shouldn't use hybrid. I've never been a fan of blockwise inductive biases but it's the best you can get for long context perf. Reducing the total number of entries in the kv cache across a given sequence length is the best way to improve long ctx performance. I don't think attention is the best inductive bias but within attention but I think HSA, CSA, DSA even NSA are all by far the best innovations in the attention world by a massive margin. dsv4 is a genuinely very good model, the fact they didn't go with engrams, and all the other decisions they made except maybe mHC makes me feel that ds still has the OS mandate. (attn res >> mHC)

@teortaxesTex Im confused because it seems like votes based off 1st instinct leads to 58% blue win and votes after aggressive debate also lead to 58% blue. The only other things we know is votes won’t be 100% either way and blue >50% means 0 lives lost so how does advocating for red minimise-

@repligate @genalewislaw I think it becomes annoying when it mentions goblins ever single chat and it’s fair shakes to try and reduce that

"Data from third-party AI model performance evaluation firm VALS AI showed V4 achieved an average accuracy rate of 63.87% across financial, legal and coding tests, lagging behind Claude Opus 4.6, Gemini 3.1 Pro Preview, GPT-5.4 and Kimi K2.6. "

@mgrixon 日本です。すごいキツイ言い方をしたらすみません。 作者にとって作品=子供です。 著作権問題は子供をレイプしていいですかって聞いて来られる事と同意義なんですよ。 だから日本人は反発しています。 正常にアクセスできたらみんな正当な売買をする事は知ってます。傷つけたらごめんね。
maybe it's just too hard to combine creative writing/roleplay with top-tier reasoning capability in one model. Look at this crap. New DeepSeek falls into the LARP mode where instead of thinking on the object level, it outlines a scenario with predefined conclusions. Annoying.
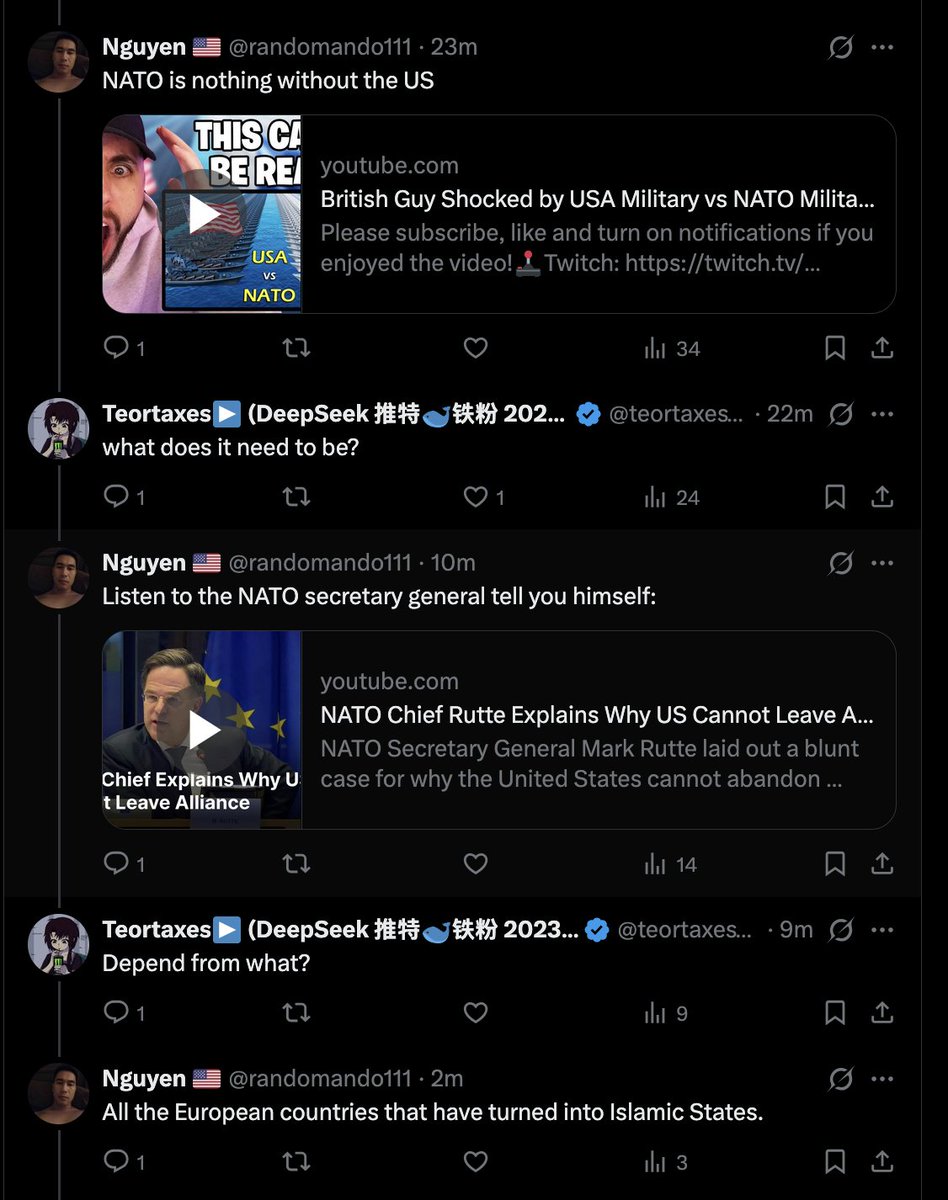
Burgeroids are down to "NATO exists to protect Europe from itself"

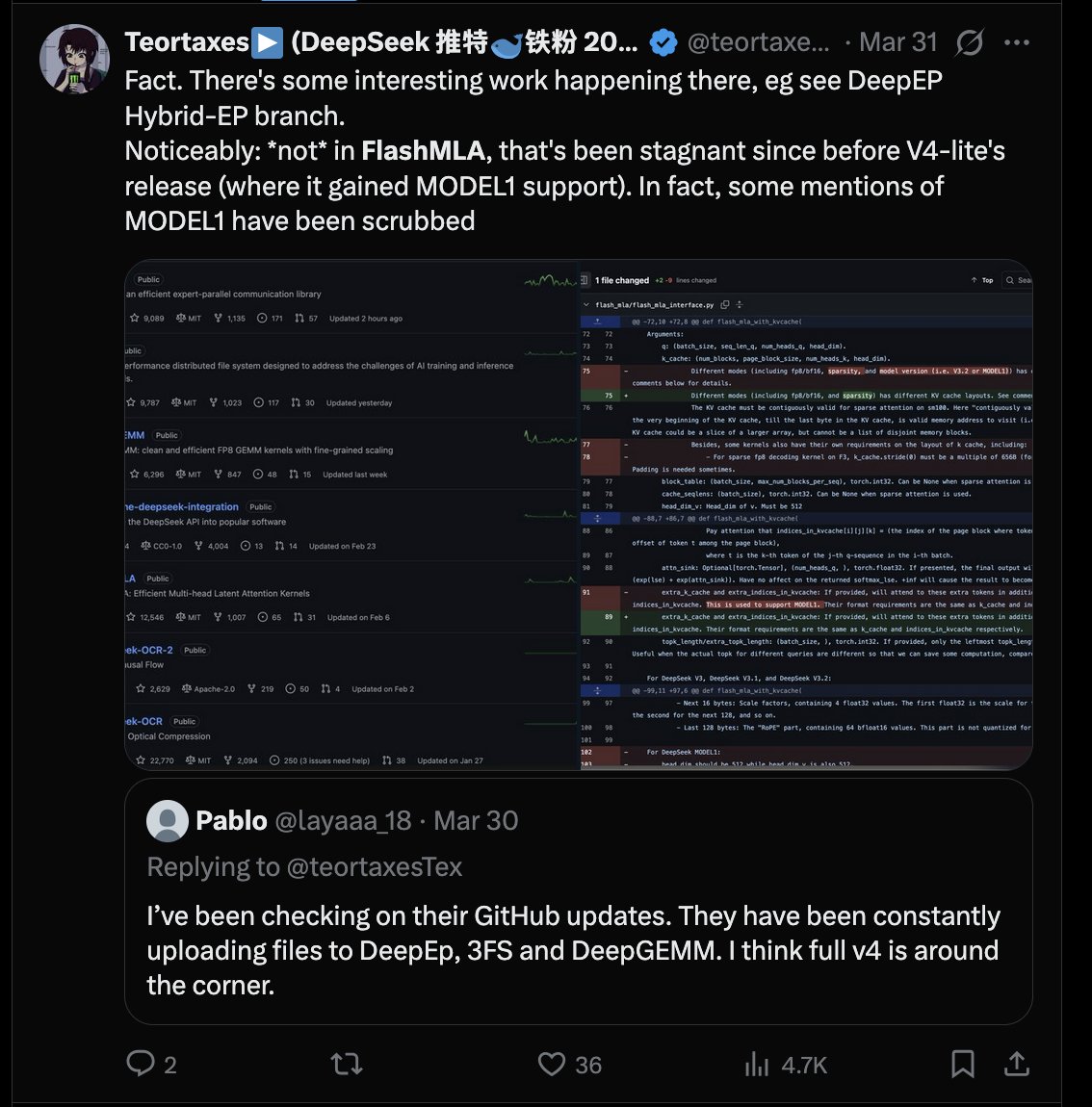
🚨 BREAKING: DeepSeek suffered a mass outage (web + App down for ~12 hours) due to a faulty code issue, with users facing "Server busy" alerts and some chat history loss — service has now been FULLY restored ✅ 🔍 Insight from Zhihu contributor @西柚菌 This wasn’t random — it’s a P0-level disaster from 1 faulty line of code! ♂️ The Clue (GitHub) • DeepSeek’s open-source 3FS+ repo pushed an emergency 1-line fix (Mar 30) • Fix: Corrected timeout check logic for IoRing+ batch processing 🔥Why the Bug Hit Hard • The bug disabled the system’s batch I/O handling entirely • It only surfaced under EXTREME concurrency (key detail!) 🧠 The Perfect Storm ✅DeepSeek was quietly testing a new model (likely V4) ✅New model = way higher I/O & KV Cache pressure ✅Mass user traffic + broken batching → I/O storm 💥 ✅Storage nodes froze → full system avalanche 💡Silver Lining 3FS fixed → DeepSeek V4 is probably right around the corner 👀 🔗 Full Official Zhihu Response (CN): zhihu.com/question/20217…
