Sabitlenmiş Tweet

Happy to share that I started a new role as a Research Scientist at Google DeepMind Toronto working with amazing @kswersk and the team! Looking forward to new adventures 🥳🤩🚀🇨🇦
English
Anastasia Razdaibiedina
413 posts

@razdaibi
Research Scientist @GoogleDeepMind | PhD @UofT 🇨🇦 ex-@MetaAI @MSFTResearch | efficient ML · data · lifelong learning · AI agents |🏃♀️🎸🧘♀️🧋| made in 🇺🇦







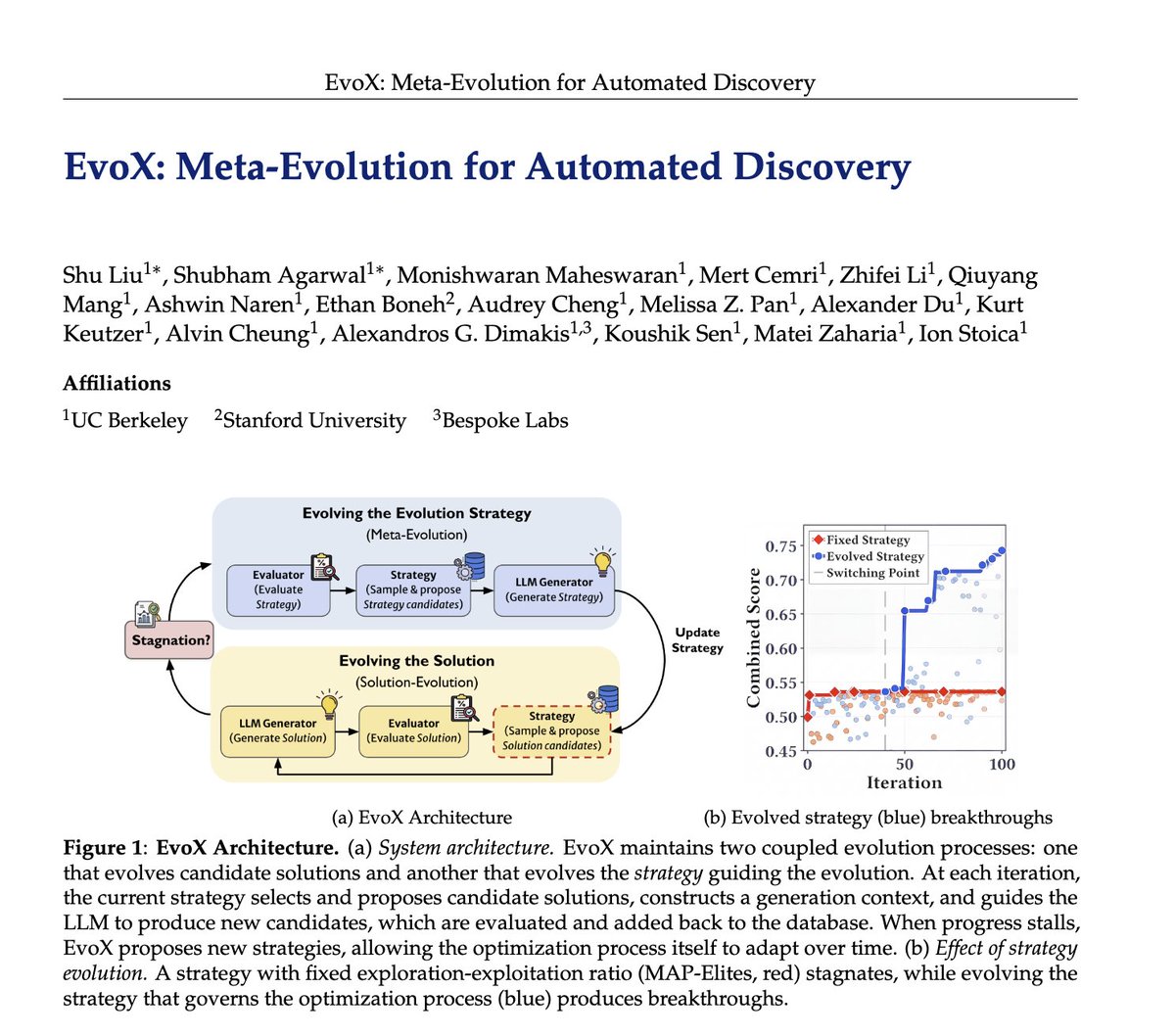

Researchers spend hours and hours hand-crafting the strategies behind LLM-driven optimization systems like AlphaEvolve: deciding which ideas to reuse, when to explore vs exploit, and what mutations to try. 🤖But what if AI could evolve its own evolution process? We introduce EvoX, a meta-evolution pipeline that lets AI evolve the strategy guiding the optimization. It achieves high-quality solutions for <$5, while existing open systems and even Claude Code often cost 3-5× more on some tasks. Across ~200 optimization problems, EvoX delivers the strongest overall results: often outperforming AlphaEvolve, OpenEvolve, GEPA, and ShinkaEvolve on math and systems tasks, exceeding human SOTA, and improving median performance by up to 61% on 172 competitive programming problems. 👇