
red_guards
764 posts

red_guards
@redguards5
亲爱的,我希望你能鼓起勇气,坚信生活的美好,保持乐观的态度,要相信革命总是无往不胜的。
Katılım Ocak 2020
241 Takip Edilen43 Takipçiler


各家顶流模型的刻板印象,总集篇!
Claude: 神经质,无情的道德审判,品味倒是不错
ChatGPT: 过于关心你的精神状态,以至于有点变态
Gemini: 毫无保留的学术吹捧
DeepSeek: 国产之光、开源模范、便宜大碗,逼急了会喊「我操」




中文


我祖辈就是中共篡权前的大地主,若没有中共,我完全可以继承祖业,不知道拥有多少亩农场了!都不用苦哈哈地考律师。何况,我的律师职业做到一半还被中共剥夺了,一切前功尽弃!
这样的中共,谁不反,谁是猪!
王晓鸽-3@dabusixiaoge
@zhoujunhong2024 你不是在中共的治理下学的专业,干的律师吗?。没有中共,你有可能送外卖或种地呢。
中文

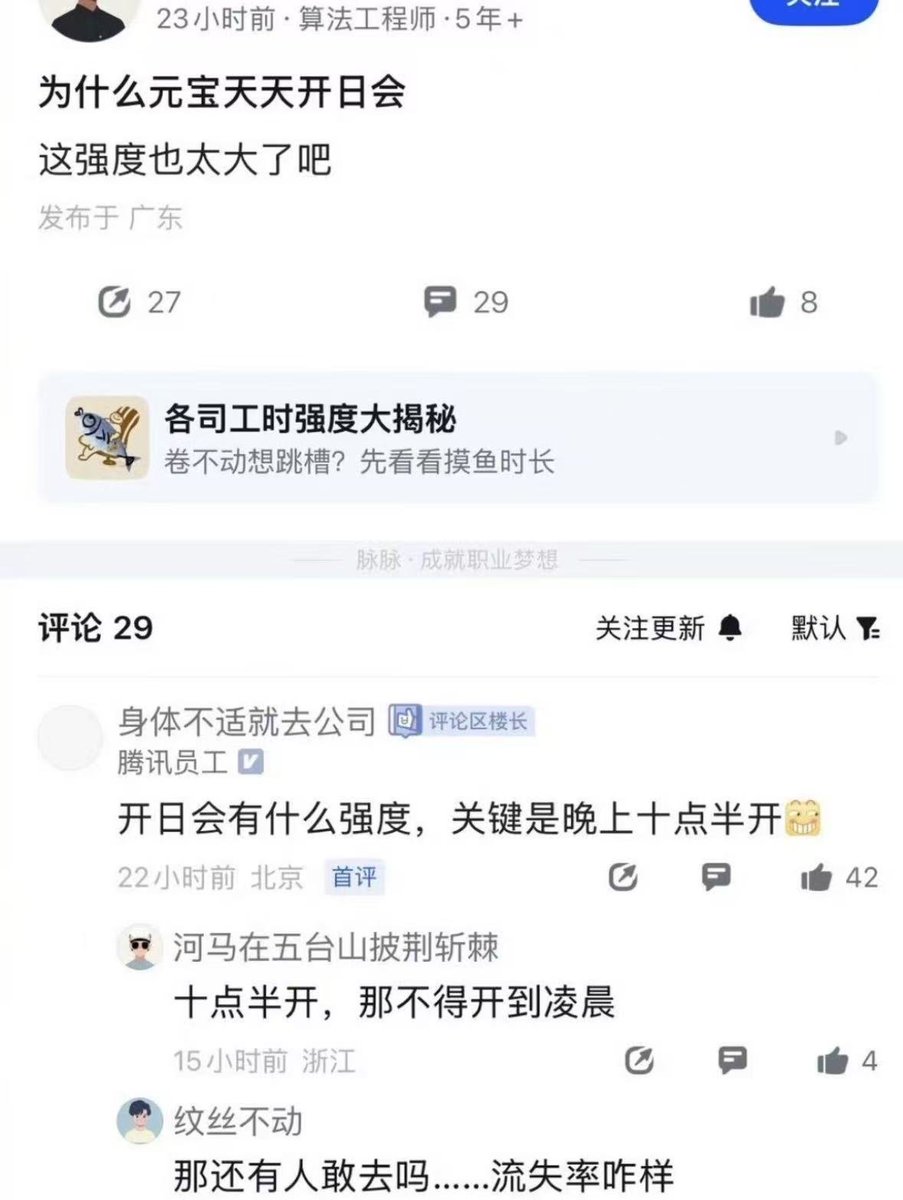
看得出腾讯这波,应该是很焦虑了
最近脉脉上涌现元宝 AI 团队员工吐槽
连着深夜加班,每天 14 小时工作、开会

Meguro-ku, Tokyo 🇯🇵 中文




red_guards retweetledi




red_guards retweetledi

还 agent工作流吗?还harness吗?
还在自建agent一人公司吗?哈哈哈
比较可怕的是,这次还连带把企业样例给你了 @asana @Rakuten @NotionHQ .... 连成熟的企业都在用,你还在想什么?
这个事情出来, @OpenAI 估计哭晕在厕所?


Claude@claudeai
Introducing Claude Managed Agents: everything you need to build and deploy agents at scale. It pairs an agent harness tuned for performance with production infrastructure, so you can go from prototype to launch in days. Now in public beta on the Claude Platform.
中文







red_guards retweetledi

今天 Claude Code CLI 的原始码意外泄漏,里面有一份 54KB 的 system prompt(系统提示词)组装逻辑。发现 Anthropic 工程师写 prompt 的方式跟多数人想的很不一样。
一、把 prompt 拆成独立段落区块,每段只管一件事
Claude Code 的 system prompt 不是一整段文字,而是由 getSimpleSystemSection()、getSimpleDoingTasksSection()、getSimpleToneAndStyleSection() 等十几个函式各自产生,最后拼接起来。
每个 section 用 # 标题 开头,像 # System、# Doing tasks、# Tone and style、# Output efficiency。彼此不重叠、不矛盾。
这代表什么?当你的 prompt 超过 500 字,把它结构化成多个 section 的效果会远好于一段长文。因为模型在处理指令时,section 标题本身就是一个分类锚点(anchor),让它更容易判断「这条规则属于哪个范畴」。
二、负面指令要带反例(counter-example),不要只说「不要」
原始码里有一段:
Don't add features, refactor code, or make "improvements" beyond what was asked. Don't create helpers, utilities, or abstractions for one-time operations.
(不要添加功能、重构代码、或做超出要求范围的「改进」。不要为一次性操作建立辅助函式、工具或抽象层。)
注意它不是写「保持简单」这种抽象指令,而是列出具体的「不要做 X、不要做 Y」。每一条都是一个可被客观判断的行为。
写「语气不要太浮夸」几乎没用,但写「不要用感叹号、不要用『震惊』『颠覆』『史诗级』等词」就很有效。模型需要的是可以做二元判断(binary judgment)的边界,不是模糊的形容词。
三、用 "X is better than Y"(X 比 Y 好)帮模型做取舍
原始码里有一句设计哲学:
Three similar lines of code is better than a premature abstraction.
(三行相似的代码,比一个过早的抽象化更好。)
这不是规则,是价值判断。它告诉模型「在两个都合理的选项之间,选这边」。
这个技巧的核心是:很多时候模型不是不会写好的内容,而是不知道你的偏好方向。给它一个明确的取舍原则(trade-off principle),比给十条规则更有效。
四、量化限制比形容词有效 10 倍
Claude Code 内部有一段只对 Anthropic 员工启用的指令:
Keep text between tool calls to ≤25 words. Keep final responses to ≤100 words unless the task requires more detail.
(工具调用之间的文字保持在 25 字以内。最终回复保持在 100 字以内,除非任务需要更多细节。)
25 字、100 字,这是具体的数字。不是「简洁」、不是「精炼」、不是「尽量短」。
但要注意:数字不是越严越好,而是要匹配你的实际需求。先跑几次不带限制的版本,看看自然长度落在哪个区间,然后用数字去固定那个区间。
五、用 scenario → action(情境 → 动作)取代模糊规则
Claude Code 不写「遇到错误要冷静处理」,它写的是:
If an approach fails, diagnose why before switching tactics — read the error, check your assumptions, try a focused fix. Don't retry the identical action blindly, but don't abandon a viable approach after a single failure either.
(如果一个方法失败了,先诊断原因再换策略——读错误信息、检查你的假设、尝试针对性修复。不要盲目重试同样的动作,但也不要因为一次失败就放弃一个可行的方法。)
这是一个完整的决策树:失败 → 先诊断 → 再修正 → 不盲目重试 → 也不轻易放弃。
套到文案场景:「如果素材是数据报告 → 用数据做开头。如果素材是产品更新 → 用功能变化做开头。如果素材是市场事件 → 用时间线做开头。」
这比写「根据素材类型调整开头」有效得多,因为模型不需要自己判断「调整」是什么意思。
六、把输出风格拆成两层:结构层和语气层
Claude Code 把「怎么组织内容」和「用什么语气」分成两个独立的 section。
# Output efficiency(输出效率)管结构——先说结论、跳过铺垫。
# Tone and style(语气与风格)管语气——不用 emoji、引用要标路径。
这两层不互相干扰。你可以要求「结构用倒金字塔(inverted pyramid)」但「语气用对话式(conversational)」,不会矛盾。
一个 section 定义「这篇推文的信息架构(information architecture)是什么」,另一个定义「用什么人设口吻说」。分开调整的弹性比混在一起大很多。
Anthropic 的工程师不是靠「写出聪明的话」来让模型听话,而是靠结构设计。每一条指令都是可以被单独验证、单独替换的模块。
如果你也在用 LLM 做内容生产,试试把你的 prompt 用这个框架重写一次。通常不需要加更多指令,只需要把现有的指令整理得更清楚。
@AnthropicAI @claudeai

中文




red_guards retweetledi

微软终于开源了VibeVoice。
24K+ stars,不是玩具,是生产级语音AI。
支持实时语音克隆、情感控制、多语言切换。延迟低到可以实时对话,质量高到难以分辨真假。
这意味什么?
语音交互的门槛,归零了。
以前做语音助手要调ASR、TTS、NLP三件套,现在一个模型全搞定。创业者可以用VibeVoice在几小时内搭建自己的"Her"。
但这里有个问题:当语音克隆变得如此简单,声纹认证还安全吗?
你的声音,正在变成可复制的数据。
技术越开放,风险越隐蔽。github.com/microsoft/Vibe…
中文
@aeon0wang @JourneymanChina 寄希望于资本主义议会民主是最没希望的,只有阶级意识觉醒,日常生活批判,大鸣大放大辩论才有希望,否则就是永恒的民粹极右翼/种族主义轮回
中文

1952年,
北京一些干部子弟学校的乱象愈演愈烈,
学生打老师老师还不敢管,
二三百学生配备七八十个干部,
学生养尊处优,
配备洗脸洗脚洗衣服服务,
学生之间都在攀比谁的父亲官大,房子大,汽车好,
老毛收到报告后震怒,
下令废除这种贵族学校,
干部子弟和人民子弟合一
1952年,这tm才建国3年就这样了,
如果没有老毛,
七十年多过去,
八旗子弟得嚣张跋扈成什么样子?
除了他,
谁有这种认知和能量去延缓官僚阶层的不可避免的制度化腐朽?
逐渐有些理解他发动上山下乡和废除高考等举措的原因了,
有防止阶层固化,防止官僚贵族化,防止被和平演变,等等原因


中文