
retto
1.2K posts
retto
@rettooooo
software engineer, building things. founder @Vidbytee
United States Katılım Ekim 2023
106 Takip Edilen102 Takipçiler
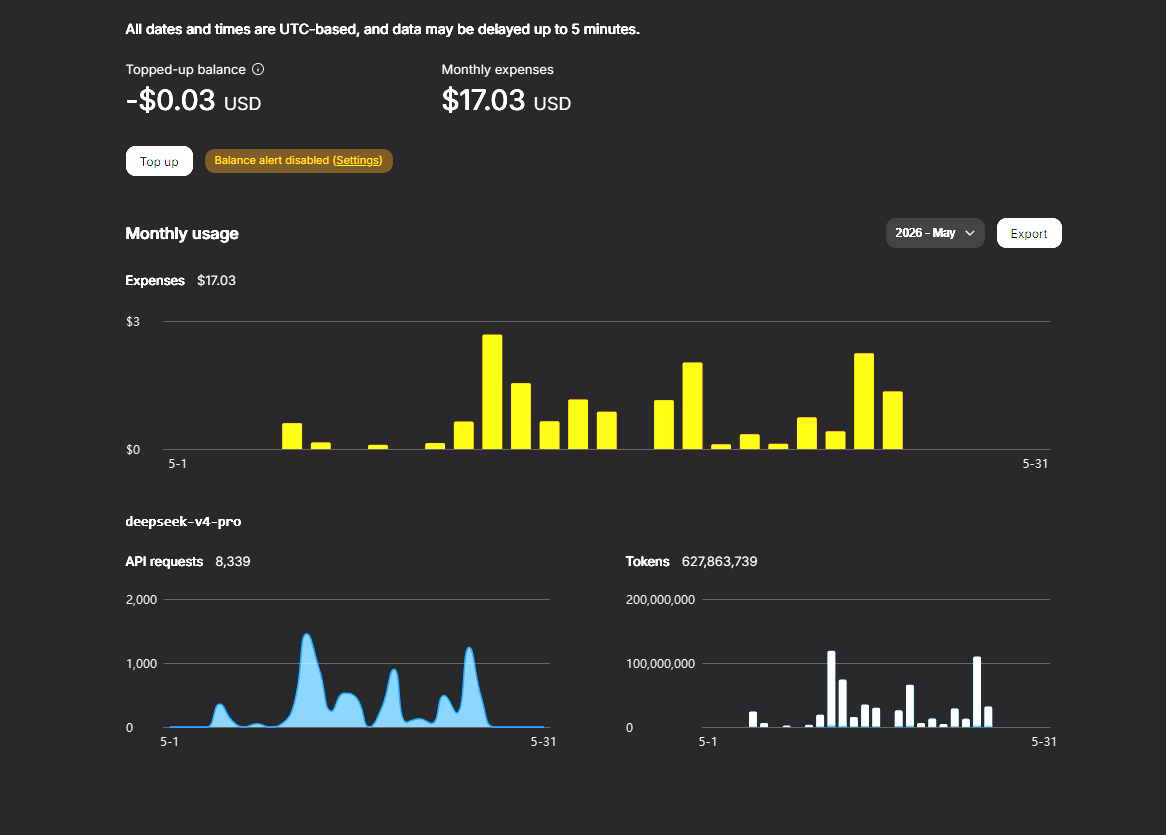

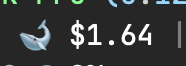
Unbelievable! @deepseek_ai is so darn cheap you don't even need a coding plan. I added $3 to my DS account many days ago and half of it has still remained. Do we really need $100/mo or $200/mo coding plans?!
English
@andersonbcdefg what happens when you think "coding is solved" and use claude to build claude code
English

official confirmation that the claude code harness has become slop btw
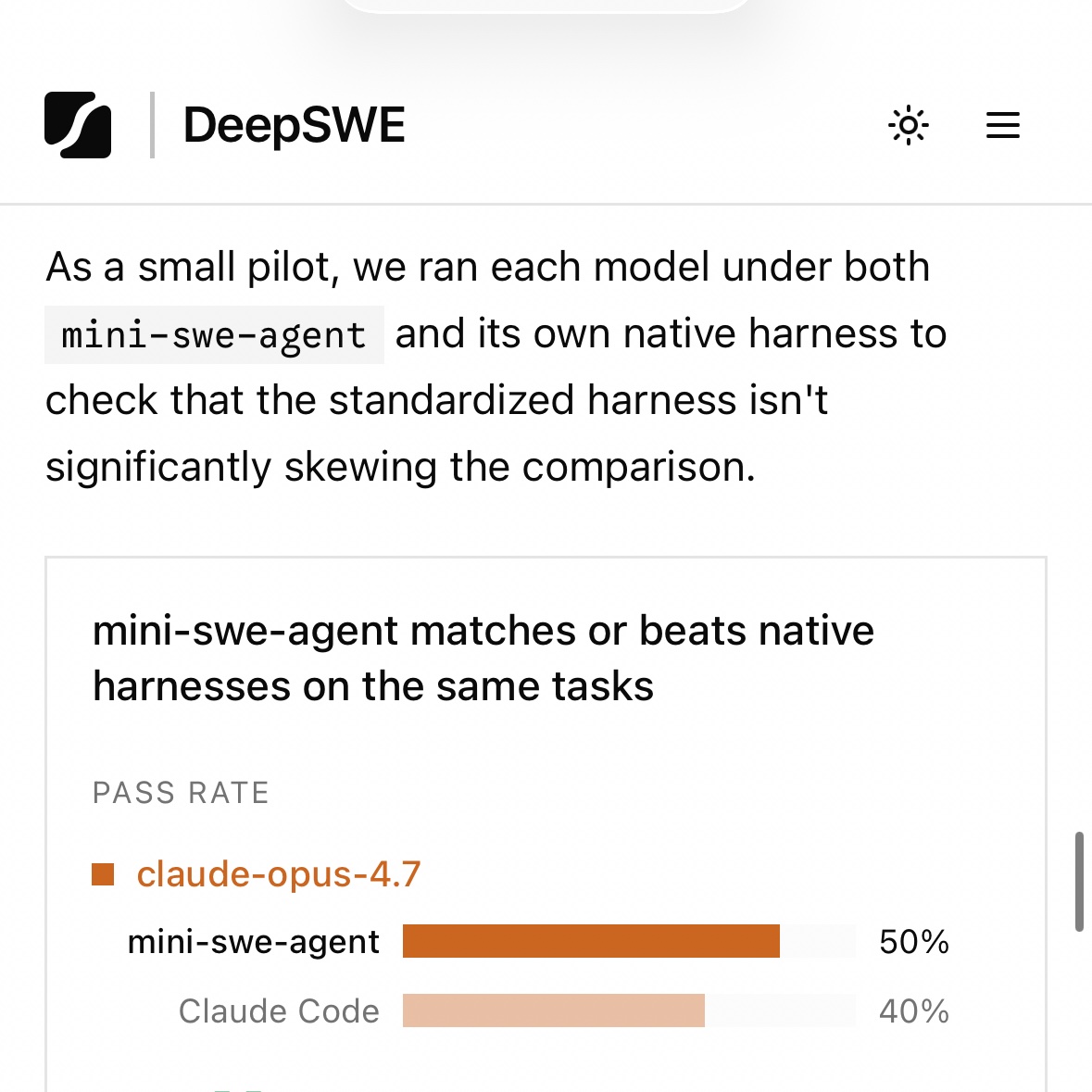
Serena Ge (Datacurve)@serenaa_ge
Today we’re releasing DeepSWE, a new standard for agentic coding benchmarks. On public leaderboards, top models often look relatively close in capability. DeepSWE shows where they actually diverge, reflecting the realistic experience of developers in their day-to-day work.
English
@beffjezos its unfortunate that working memory is very limited in our meat brains
English

they need to RLHF to minimize cognitive load now.
there's a limited amount of high perplexity tokens the brain can process per day before becoming fried
Hugo@striedinger
Is any other career dealing with so much ai slop? It’s an uphill battle smh, I’m mentally drained
English

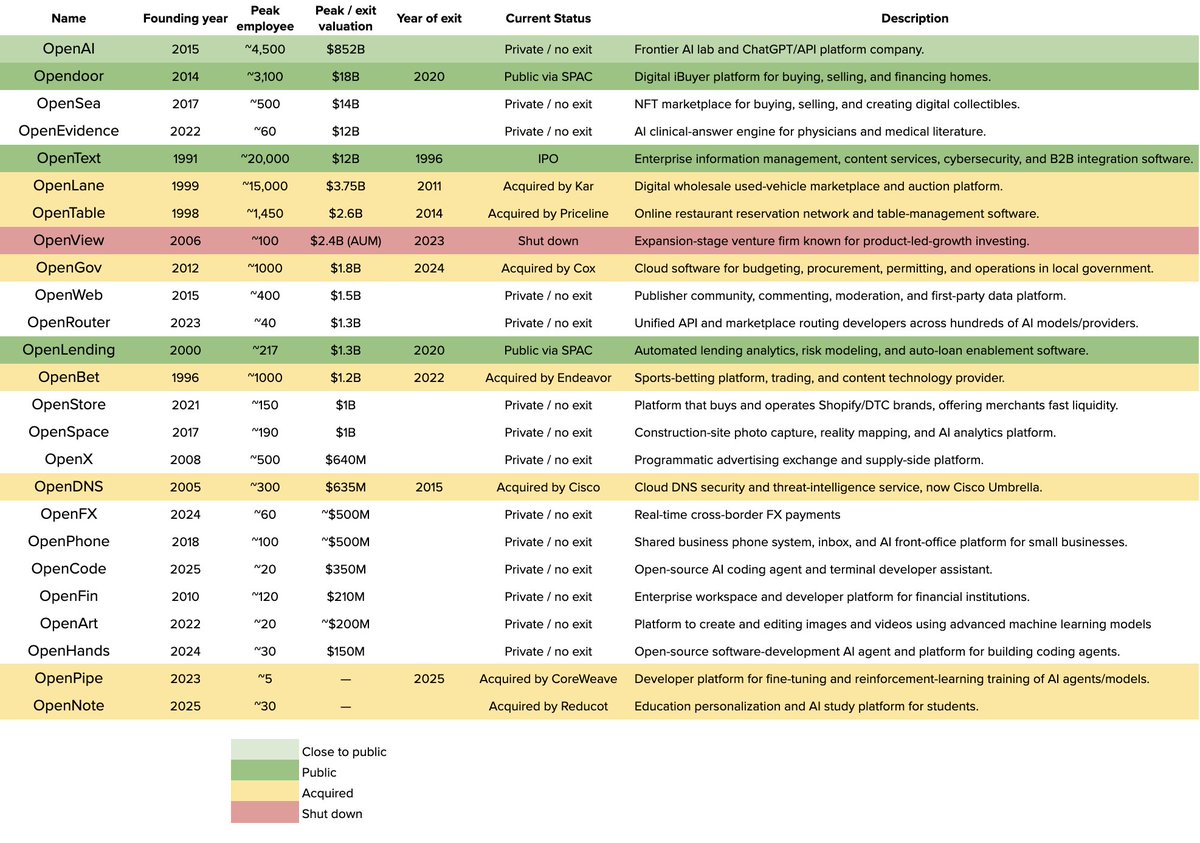

Bug fixes shipping to Grok Build 0.2.3 (release notes will be available in the TUI)
- add “Yes, and don't ask again for anything (always-approve mode)"
- add alpha/stable to welcome screen
- JetBrains/JediTerm terminal detection so TUI does not get confused and detect it as some other terminal
- persist model ID instead of display name for default_model
- clamp Q&A height to prevent ratatui buffer overflow
- better UX for tmux inside ssh copy-paste issues
- store vim mode persistently in the config.toml to prevent restart loss
- memory usage improvements for managing chat history on the hot path
English
@PeterDiamandis orders of magnitude away from the token-usage that power users need
English

Power users will soon want 1,000 concurrent agents. Engineers, architects, designers... all orchestrating swarms. Compare that demand to the current supply. It's peanuts.
English


Introducing Merge Gateway - Build Your Own Router.
You're three sprints into your coding assistant.
You pick the most hyped model, integrate, test, deploy.
A month later, a new model drops.
Now you re-test, re-integrate, re-deploy.
Your product didn't change, but the benchmark did.
That's how most AI teams operate.
Chasing a "best" defined by people who've never seen their product.
There is no best model.
There's only the right one for your product, users, and use-cases.
Build Your Own Router runs on your definition of good.
Pick your benchmarks, weigh them, add your own evals.
@merge_api routes every request to your winner.
👉$100 in credits to the first 200 people that comment
merge.dev/gateway
English

This is the next level.
Muratcan Koylan@koylanai
Gradient descent for SKILL.md files sounds interesting, maybe a bit complex but it's becoming a real part of agent harness. SkillOpt is one of the first papers to treat markdown skill files as trainable parameters and provides a proper optimization framework for them. A few things I learned that you should consider too. 1. The validation gate is the only thing that matters in a self-editing loop. Held-out set, strict improvement, ties rejected. End-to-end, their best skills land with 1 to 4 accepted edits total. If your "self-improving agent" is accepting most of what it proposes, you're shipping slop. 2. Bounded edits are better than full rewrites. 4 to 8 edits per step is the sweet spot. Remove the budget and performance collapses. This is the textual analog of learning rate, and it transfers to any LLM-as-author loop. If you're using an agent to refactor your docs, your prompts, or your skills, cap the diff size. 3. Compactness wins. Median final skill: ~920 tokens. Skills do not need to be long. They need to be high-signal. Most skill files I see are bloated because length feels like effort. It isn't. 4. The harness is becoming less important; the skill is becoming more important. A Codex-trained skill ported into Claude Code hit +59.7 points on SpreadsheetBench. Procedural knowledge is more general than the runtime that produced it. 5. Frozen model + trained context is the practical adaptation. GPT-5.4-nano with a SkillOpt'd skill ≈ frontier behavior on procedural benchmarks. Cheaper, portable, inspectable, zero inference-time cost. This is the answer to "how do we adapt a frontier model for our domain" for almost everyone who isn't training their own models. 6. Verification is the bottleneck. Every gate in this paper depends on an auto-grader. That works for benchmarks. It fails for writing, design, and strategy, exactly the open-ended work we want to automate. Whoever builds the verifier for open-ended tasks owns the next stage. There are also two leassons I learned while shipping v2.3.0 of my Context Engineering Agent Skills repo, measured across composer-2, claude-opus-4-7, gpt-5.5, and gemini-3.1-pro via the @cursor_ai SDK: - Description and body are two different surfaces. The router only sees the description. The agent sees the body once activated. They can quietly disagree, and only end-to-end task tests catch it. - Aggregate accuracy is the wrong unit. When I rewrote three descriptions, the corpus average moved ~1pp. Individual skills moved 23–25pp. Per-skill effect size is where the action is. Also, in Feb 2026 I shared a piece called Personal Brain OS arguing that the markdown file is a first-class substrate for agent state. SkillOpt is the optimizer-shaped version of that same argument: not "store memory in files" but "treat files as trainable parameters with proper optimization machinery around them." That's the move from static to measured. The fast/slow split they describe already lives implicitly in the digital-brain-skill repo: - voice-guide and tone-of-voice.md are slow-state (rarely touched) - posts.jsonl and bookmarks.jsonl are fast-state What SkillOpt adds that I didn't have is a protected section invariant, a structural guarantee that fast edits cannot overwrite slow lessons. Removing that mechanism cost them 22 points on SpreadsheetBench. Worth borrowing. If you're building agents, SkillOpt: Executive Strategy for Self-Evolving Agent Skills is a good paper to read: arxiv.org/pdf/2605.23904
English
@edwards345 @elonmusk 10x faster and cheaper engineering leads to solving bigger and harder problems
English

This is our mission. The timeline for achieving this shrinks significantly if we can 10-100x the useful output of our engineering and manufacturing teams. AI and robotics make this possible. This can happen in our lifetime.
Elon Musk@elonmusk
Mostly true. What matters is securing the long-term future of consciousness, both on Earth and other heavenly bodies. We cannot just focus on Earth, because there are irreducible external (eg massive meteor) and internal (eg global nuclear war) cataclysmic risks. The Moon is faster to make self-growing, but is more susceptible to problems on Earth. Mars will take longer to make self-growing, because it is so hard to reach, but is more secure from Earth disasters for that same reason. Both the Moon and Mars should have self-growing civilizations. Making this happen is the prime directive of SpaceX.
English

System scaling is the next real bottleneck in agentic AI.
If you build agent orchestration layers, this is a clean map of where the engineering leverage actually sits. The labs own the model. You own the harness, and that is increasingly where agent quality is won or lost.
The default mental model still puts all the weight on the foundation model. Bigger model, better agent. But agent behavior actually emerges from the whole stack around it. Memory substrate, context constructor, skill routing, orchestration loop, and the verification and governance layer.
This new research calls that stack the harness and argues we should treat it as a first-class object of design and evaluation. It names three core bottlenecks to scale. Context governance, trustworthy memory, and dynamic skill routing. It also ships CheetahClaws, a Python-native reference harness, and compares it with Claude Code and OpenClaw.
Paper: arxiv.org/abs/2605.26112
Learn to build effective AI agents in our academy: academy.dair.ai

English
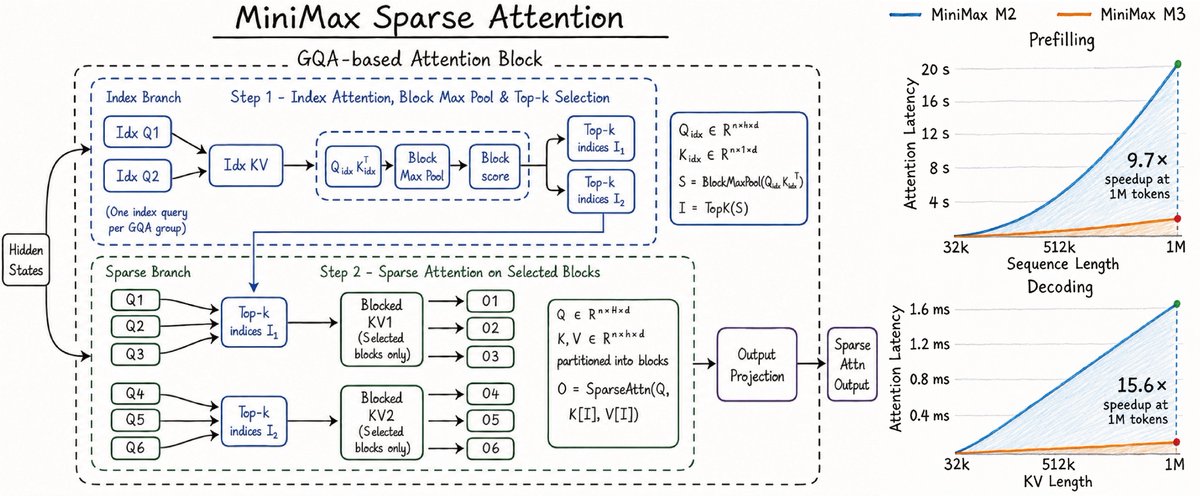
@kimmonismus when in doubt if you want to improve your models take inspiration from the human brain and built a sparse attention mechanism from the ground up
English

MiniMax just teased their Sparse Attention architecture for M3. The benchmarks show 9.7x prefilling speedup and 15.6x decoding speedup at 1M tokens vs M2.
MiniMax deliberately went back to full attention for M2 because efficient attention wasn't production-ready. Their pretrain lead wrote a whole blog post about it in March. Now they're showing a new two-stage approach, lightweight index branch for block selection, then sparse attention only on relevant KV blocks.
Really interesting. And tbh I'm always happy when open source receives new wins.
MiniMax (official)@MiniMax_AI
#MSA #OpenSource #M3 🫣😎
English
@SkylerMiao7 the time to scale context windows is now, too much drift when you use 50 subagents, the context needs to be in 1 window to achieve maximum performance
English


First correct benchmark I’ve seen in a while
Serena Ge (Datacurve)@serenaa_ge
Today we’re releasing DeepSWE, a new standard for agentic coding benchmarks. On public leaderboards, top models often look relatively close in capability. DeepSWE shows where they actually diverge, reflecting the realistic experience of developers in their day-to-day work.
English

One of my friends at a tech company said the vibe inside offices right now is weird.
Junior devs think AI will take their jobs.
Senior devs think they’ll become outdated in 2 years.
Managers are scared companies won’t need so many layers anymore.
So everyone’s acting extra “AI-positive” publicly while privately panicking.
English

New coding benchmark.
GPT-5.5 and GPT-5.4 are ahead of Opus 4.7 💀
Serena Ge (Datacurve)@serenaa_ge
Today we’re releasing DeepSWE, a new standard for agentic coding benchmarks. On public leaderboards, top models often look relatively close in capability. DeepSWE shows where they actually diverge, reflecting the realistic experience of developers in their day-to-day work.
English


Imagine telling someone 50 years ago you'd have a machine that could explain any concept in human history, write code, diagnose disease, and reason through problems with you for $20/month
They would literally think you were describing god
This exists. You have access to it. Yet most of you are using it to summarize emails
The arbitrage between people who actually use AI and people who "use AI" is the widest it will ever be
That window is open right now and it will close faster than most people think
Tldr; start using AI for more than just mundane tasks
English
theoretically I can agree, but the only question I have is why has this not happened already? these models are sometimes already trillions of params in size and trained on the corpus of human knowledge already. There are also alot of examples of extensive scaffolding to give the models all of the context they could ever need. Is it really a model capability problem or is there some architectural failure point that these models have that is making them struggle to truly discover new science
English

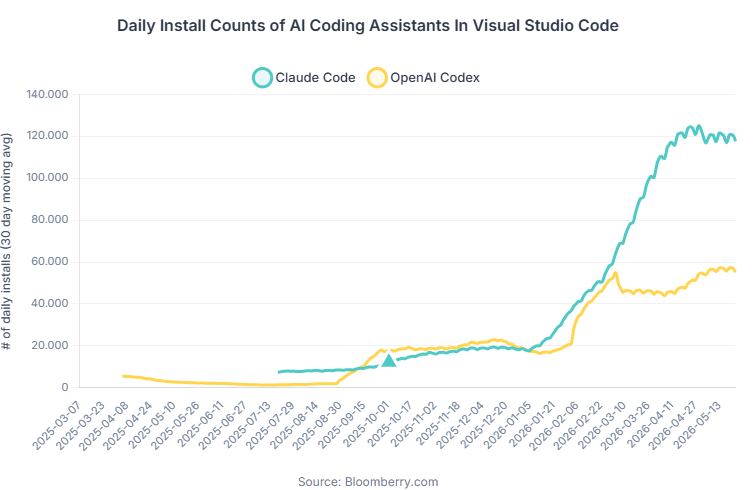
It's clear that growth for coding tools such as Claude Code has decelerated from the pace it was since the start of the year.
It might be compute- constrain related or due to many clients blowing their full-year AI budgets.
Monitoring this trend very closely with all the alt data. I will provide regular updates.
English