asitis
1.6K posts


asitis
@rifeash
Updating the world view one posterior at a time. For anonymous feedback: https://t.co/VcW2ZrZALN
Oblivious RAM Katılım Aralık 2021
631 Takip Edilen250 Takipçiler

For each answer that gets it right, the answer + person name will be in early supporters section when we release this
Ampixa Labs@__ampixa__
अन्दाज गर्नुहोस्, हामी केमा काम गरिरहेका छौँ? hint : यो लिम्बू(ᤕᤠᤰᤌᤢᤱ ᤐᤠᤴ) लिपि, अर्थात् सिरिजंगा, का लागि बनाइएको Validation Dashboard हो। PDF बाट निकालिएको image मा bounding box लगाइएको छ। दायाँपट्टि देखिएका blocks मा cropped image र त्यसको Noto Sans Devanagari मा equivalent Unicode राखिएको छ।
English

@__ampixa__ Congrats on the launch. I remember testing out the tts voice ranking site you guys posted on reddit.
English

🇳🇵 kala-tts : नेपालमै बनेको, पहिलो आफ्नै देवनागरी G2P सहितको खुला-स्रोत नेपाली VITS आवाज।
cloud छैन · तपाईंकै CPU मा चल्छ।
pip install kala-tts · 🎧 tts.ampixa.com/kala
NE
@shreemaan_abhi @__ampixa__ Thanks... more interesting things coming. Its been long time working on stealth . aba haluka significant kura yesari nai share gardai janchu hola
English

@__ampixa__ Great work dai and team. Now I can connect the dots backwards when you shared that tts ko graph draw gareko whiteboard diagram several months ago.
Rooting for you!
English
@aabhpsy @__ampixa__ You can also check Higgs Audio v3 TTS by @boson_ai
huggingface.co/bosonai/higgs-…
English
Any already available options even on GPU?
Can we continue work from what you have done so far and use GPUs to get production grade cloned audio in natural Nepali like we speak?
I don't understand all but I can dig in and learn from 0 but since you guys have pioneered, it would be nice to get insights.
English
@bbk_dkl Do you mean the full conversational voice agent?
For that we require speech language models ...
We might be able to join ASR + language model + TTS and in text to speech part we should be able to use it but i wouldn't think that would be the good usecase of this model here.
English

@bijaysenihang I understand you no longer access to fable as a Nepali citizen 😆
English

I am done staying in Nepal and creating hope, only for the pathetic Nepal government to break you from every side. Going forward, I will no longer provide my knowledge, time, or cybersecurity expertise to the Government of Nepal.
English
Design: model translates Limbu to Nepali, then in a completely fresh context translates its own Nepali back into Limbu.
Scored vs the original human Limbu (chrF).
An "echo" metric catches models that fake it by copying the input through both legs which disqualified our chinese brethrens
English


if this post gets 5 likes. i will open source it.
Ampixa Labs@__ampixa__
कि कसो @RabindraMishra ज्यू context: यो नेपालको लागी नेपालमा बनेको Text To Speech प्रणाली बाट बनाइएको हो ।
English
Something big to come within these 6 months. Each day is going to be exciting
Ampixa Labs@__ampixa__
Sneak peek
English
asitis retweetledi

i look forward to our chinese brothers liberating the knowledge from within fable-5 and selling it to me at 5% the cost & 2x the speed
English
exploration will lead to preservation. Exciting things will drop this week
Ampixa Labs@__ampixa__
English
She said "I'm fine", but my speech language model didn't understand her. Because it doesn't catch tones, emotion and stress.
Here is how to solve it
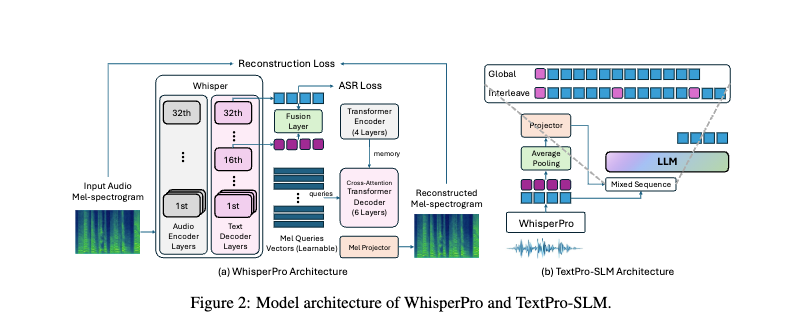
if you take ASR like whisper and it's 16th decoder layer(P_16).
Then create a reconstructor model
it is trained on three passes
first pass:
audio, text -> whisper -> P_16 + text
second pass:
p_16 + text--> reconstruct mel spectogram
third pass: compare with original mel spectogram
Train until reconstruction is perfect. Now you can replace that p_16 on whisper_v3 and get a new model.
Call it whisper pro
Now use the whisper pro +(texts, audio, emotion metadata) from emotion set like (IEMOCAP, CREMA-D)
to create a SLM(Speech language model)
input = [P₁₆ prosody vector] + [text token embeddings]
Congrats you got a better SLM
arxiv.org/abs/2605.05927
English