Rohan Paul@rohanpaul_ai
New Google paper trains LLM judges to use small bits of code alongside reasoning, so their decisions become precise.
So judging stops being guesswork and becomes checkable.
Text only judges often miscount, miss structure rules, or accept shaky logic that a simple program would catch.
TIR-Judge makes the judge think step by step, write code to check claims, run it in a sandbox, then update the verdict.
Training mixes tasks where code can verify answers and tasks where it cannot, so the judge learns when to call tools and when to rely on reasoning.
One prompt schema covers pointwise scoring, pairwise choices, and listwise selection, so it plugs into many workflows.
Reinforcement learning rewards being correct, following strict output tags, and using at most 3 tool calls.
A variant called TIR-Judge-Zero skips teacher distillation and still improves by alternating reinforcement learning, rejection sampling, and supervised fine tuning.
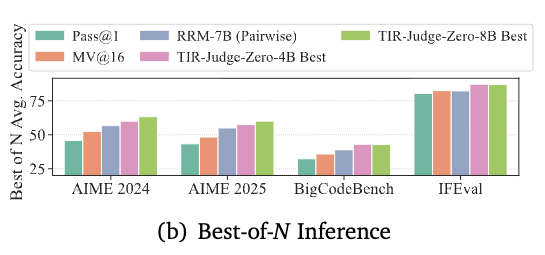
Across public judge benchmarks it beats text only judges, and with 8B it reaches 96% of Claude Opus 4 on listwise ranking.
The core idea, give the judge verifiable checks plus rewards that favor careful tool use.
----
Paper – arxiv. org/abs/2510.23038
Paper Title: "Incentivizing Agentic Reasoning in LLM Judges via Tool-Integrated Reinforcement Learning"