Sabitlenmiş Tweet

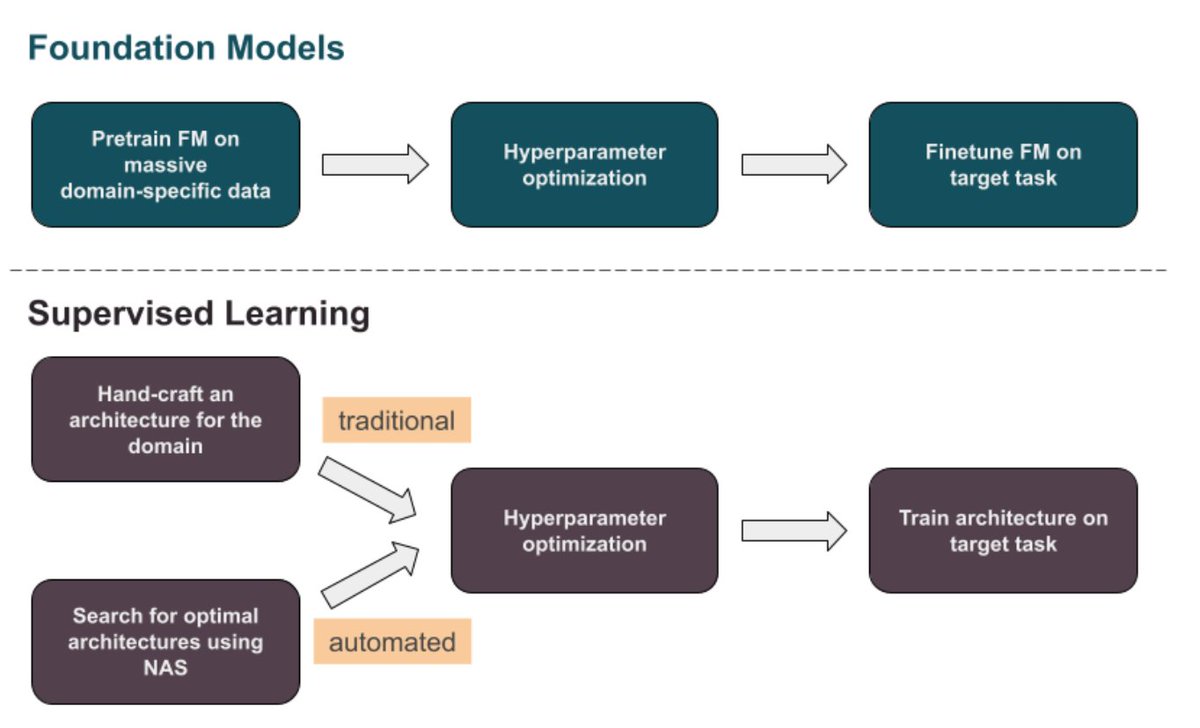
Check out some really interesting results from our study! Despite the wave of FMs in specialized domains such as genomics, satellite imaging, and time series, most of these specialized FMs are often no better--and sometimes even worse--than simple supervised baselines.
Misha Khodak@khodakmoments
🧵 on surprising revelations from our study of specialized foundation models (FMs beyond vision/text): after evaluating dozens of scientific & time series FMs we found that most weren’t even competitive with simple supervised models, some with as little as 513 parameters. 1/n
English